【直观详解】什么【直观理解】一文搞懂RNN(循环神经网络)基础篇是PCA、SVD
推荐阅读时间8min~15min
主要内容简介:神经网络基础、为什么需要RNN、RNN的具体结构、以及RNN应用和一些结论
神经网络可以当做是能够拟合任意函数的黑盒子,只要训练数据足够,给定特定的x,就能得到希望的y,结构图如下:
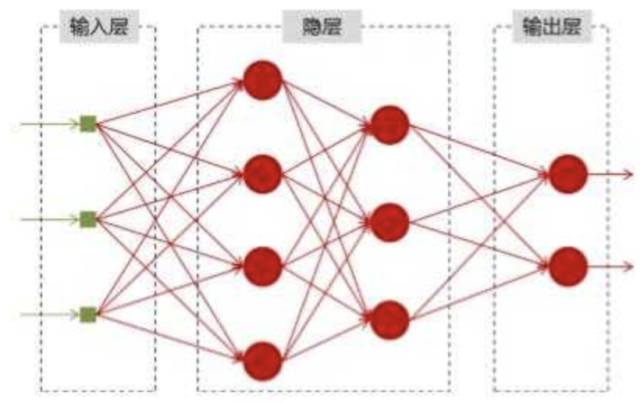
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
那么这个任务的输入就是:
我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
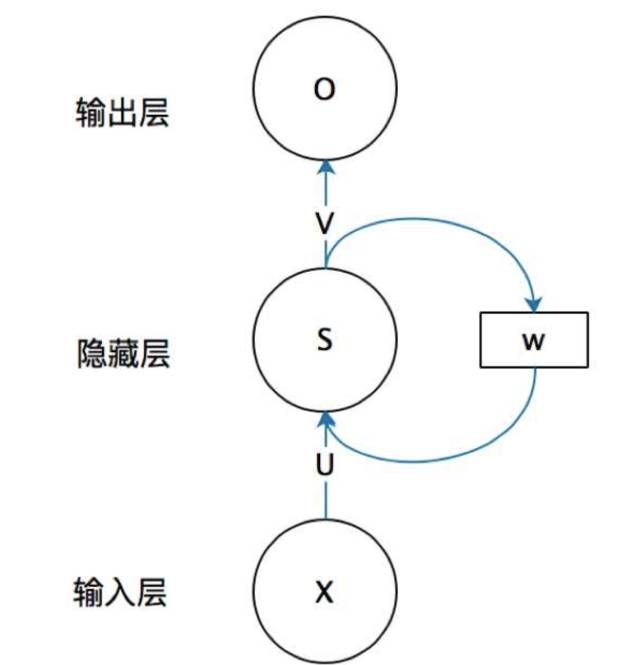
不知道初学的同学能够理解这个图吗,反正我刚开始学习的时候是懵逼的,每个结点到底代表的是一个值的输入,还是说一层的向量结点集合,如何隐藏层又可以连接到自己,等等这些疑惑~这个图是一个比较抽象的图。
我们现在这样来理解,如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。
x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
转自:机器学习算法与自然语言处理
完整内容请点击“阅读原文”




