一上台就紧张?这个模型帮你生成演讲「替身」,肢体语言比总统候选人还丰富
机器之心报道
参与:杜伟、魔王
只输入语音便能生成人体姿势。瑞典皇家理工学院的研究者做到了!









论文主页:https://diglib.eg.org/handle/10.1111/cgf13946
项目地址:https://github.com/simonalexanderson/StyleGestures
数据集无需手动标注;
具备不确定性(因而可以得到无限种类的姿势变体);
能够输出全身姿势。

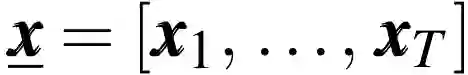 稳定自回归模型中,学习姿势 X 的多维下一步(next-step)分布。归一化流这一通用技术在表示大量连续值分布 p(x) 时能够同时实现高效推理(概率计算)以及高效的分布采样。
稳定自回归模型中,学习姿势 X 的多维下一步(next-step)分布。归一化流这一通用技术在表示大量连续值分布 p(x) 时能够同时实现高效推理(概率计算)以及高效的分布采样。
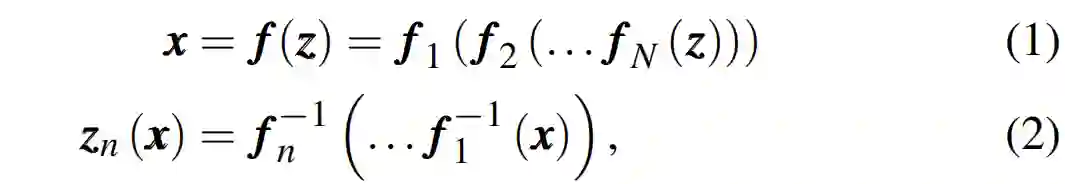
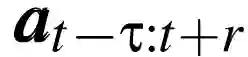 的视窗(window),从而将足够的未来信息考虑在内。完整的动作生成流程如上图 1 所示。
的视窗(window),从而将足够的未来信息考虑在内。完整的动作生成流程如上图 1 所示。

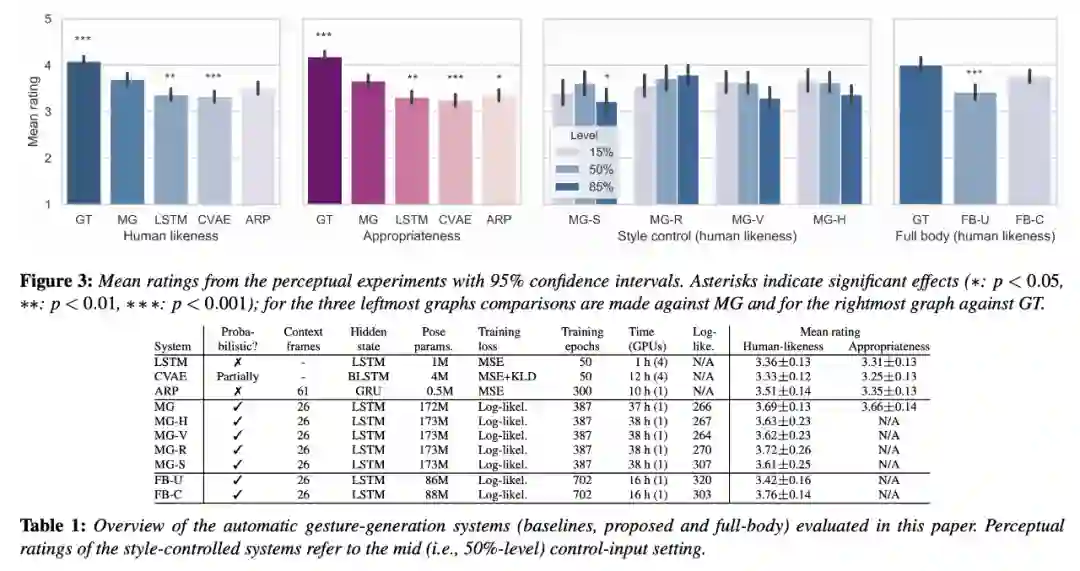
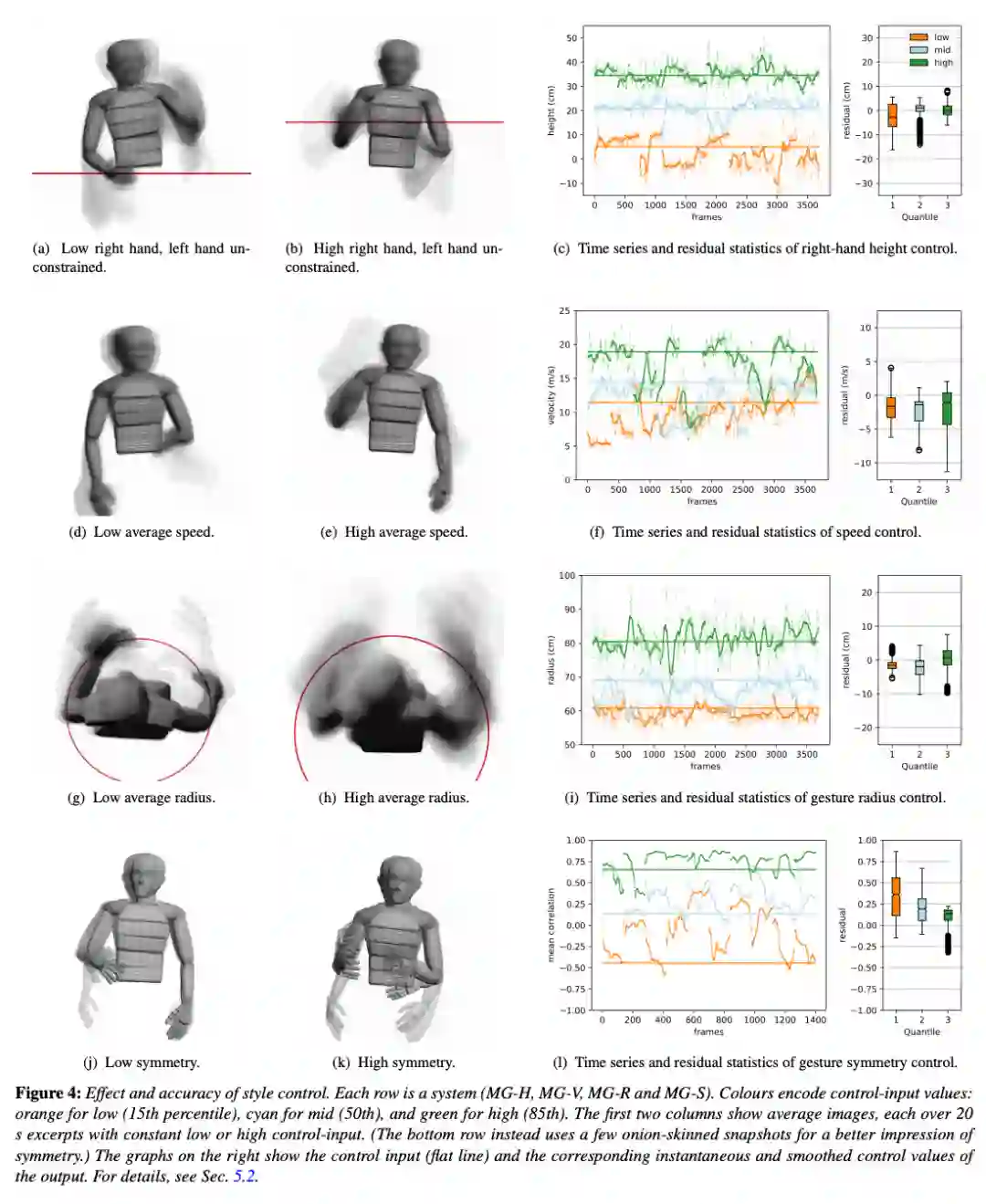
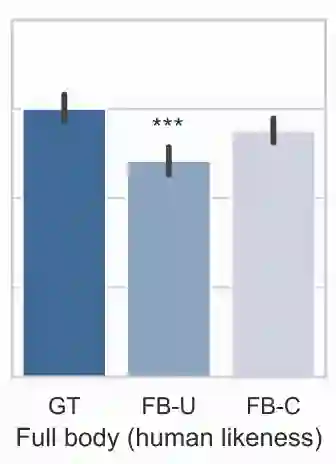
你说的对!这个模型仅倾听语音(没有文本输入),但并不包含任何人类语言模型。我认为,使用这类模型生成具备语义意义的姿势(尤其还要与语音节奏保持一致)仍是一个未解难题。
数据是目前的主要瓶颈。该模型基于同一个人的大约四小时的姿势和语音数据。我们很难找到足够的高质量语音和动作平行数据。一些研究者使用 TED 演讲,但是从此类视频中提取的姿势动作看起来不具备说服力,不够自然。(好的运动数据需要运动捕捉设置和仔细的数据处理。)因此,该研究目前使用的是较小型的高质量数据集。

登录查看更多
相关内容

Arxiv
9+阅读 · 2019年10月12日
Arxiv
3+阅读 · 2018年7月19日




相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2019年10月12日
Arxiv
3+阅读 · 2018年7月19日