【学界】造假AI又进化!只要一张照片,说话唱歌视频自动生成,降维打击Deepfakes丨已开源
来源:量子位
曾造出无数“小视频”、恶搞过多位明星的知名换脸神器Deepfakes,这下被降维打击了。
这个新AI不再是篡改视频了,而是直接把一张静态的照片变成视频。
像这样,一张施瓦辛格:

开始说话了:

饶舌歌手Tupac Shakur:

也能张嘴了:

只要有一张静态的人脸照片,甭管是谁,在这个新AI的驱动下,任意配上一段语音,就能张嘴说出来。
当然,上面的gif动图没有声音,你可以点开下面视频听听效果,里面有川普、施瓦辛格,还有爱因斯坦。
△ 总共2M,流量党请放心食用
当然,除了说话之外,唱歌也毫无问题,比如让生活在一百多年前的“俄罗斯妖僧”拉斯普京唱碧昂丝的Halo:
虽然声音和性别不太匹配,但是画面和歌曲组合起来有种莫名的鬼畜感呢。
你也别以为这个AI只能给照片对口型,它还可以让这个说话的人拥有喜怒哀乐各种情绪。
开心的:

难过的:

炸毛的:

连体态都符合不同情绪的状态,你打开视频听听看,是不是很符合说话的情绪?
这眉眼,这目光,这脸部肌肉,得拯救多少“面瘫”演员啊!
这项研究来自帝国理工学院和三星,研究者们还准备了一套包含24个真假难辨的视频的图灵测试,我们简单测了一下,只能猜对一半左右。
也就是说,这些AI生成的“真假美猴王”,足以蒙骗人类了。
相比此前的斯坦福输入任意文本改变视频人物口型的研究,以及三星的说话换脸,实现难度可以说高了很多。
不少网友闻之色变:

现在是拉斯普京唱Halo,以后会不会整出川普向墨西哥选战啊,感觉怕怕的。
连科技媒体The Verge都评价说:

这样的研究总让人们担忧,怕它会被用在谣言和政治宣传上,实在是让美国立法者们伤脑筋。当然,你也可以说这种在政治领域的威胁没那么严重,但deepfakes已经确确实实伤害了一些人,尤其是女性,在未经同意的情况下被用来制造了又难堪又羞辱的色情视频。
也有人觉得,等技术普及之后会给做坏事的人掩盖的理由:
等这技术成熟了,川普真的干坏事的小视频出来,他就可以轻描淡写的说这是假视频。
呵呵,真棒,以后坏人们被捏到把柄的时候,就都能说“没有的事啦,是假视频。”
多鉴别器结构
如何用一张照片做出连贯视频?研究人员认为,这需要时序生成对抗网络(Temporal GAN)来帮忙。
逻辑上不难理解,如果想让生成的假视频逼真,画面上至少得有两点因素必须满足:
一是人脸图像必须高质量,二是需要配合谈话内容,协调嘴唇、眉毛等面部五官的位置。也不用动用复杂的面部捕捉技术,现在,只用机器学习的方法,就能自动合成人脸。
这中间的秘诀,就在于时序生成对抗网络,也就是Temporal GAN,此前在2018年提出过这个研究。
这是一个端对端的语音驱动的面部动画合成模型,通过静止图像和一个语音生成人脸视频。
在Temporal GAN中有两个鉴别器,一个为帧鉴别器,确保生成的图像清晰详细,另一个是序列鉴别器,负责响应听到的声音并产生对应的面部运动,但效果并不那么优异。

△ Temporal GAN模型示意图
论文End-to-End Speech-Driven Facial Animation with Temporal GANs 地址:
https://arxiv.org/abs/1805.09313
在这项工作,研究人员借用这种时序生成对抗网络,使用两个时间鉴别器,对生成的视频进行视听对应,来生成逼真的面部动作。
同时还鼓励模型进一步自发产生新的面部表情,比如眨眼等动作。
所以,最新版基于语音的人脸合成模型来了。模型由时间生成器和3个鉴别器构成,结构如下:

这是一个井然有序的分工结构,生成器负责接收单个图像和音频信号作为输入,并将其分割为0.2秒的重叠帧,每个音频帧必须以视频帧为中心。
这个生成器由内容编码器(Content Encoder),一个鉴别编码器(Identity Encoder)、一个帧解码器(Frame Decoder)和声音解码器(Noise Generator)组成,不同模块组合成一个可嵌入模块,通过解码网络转换成帧。
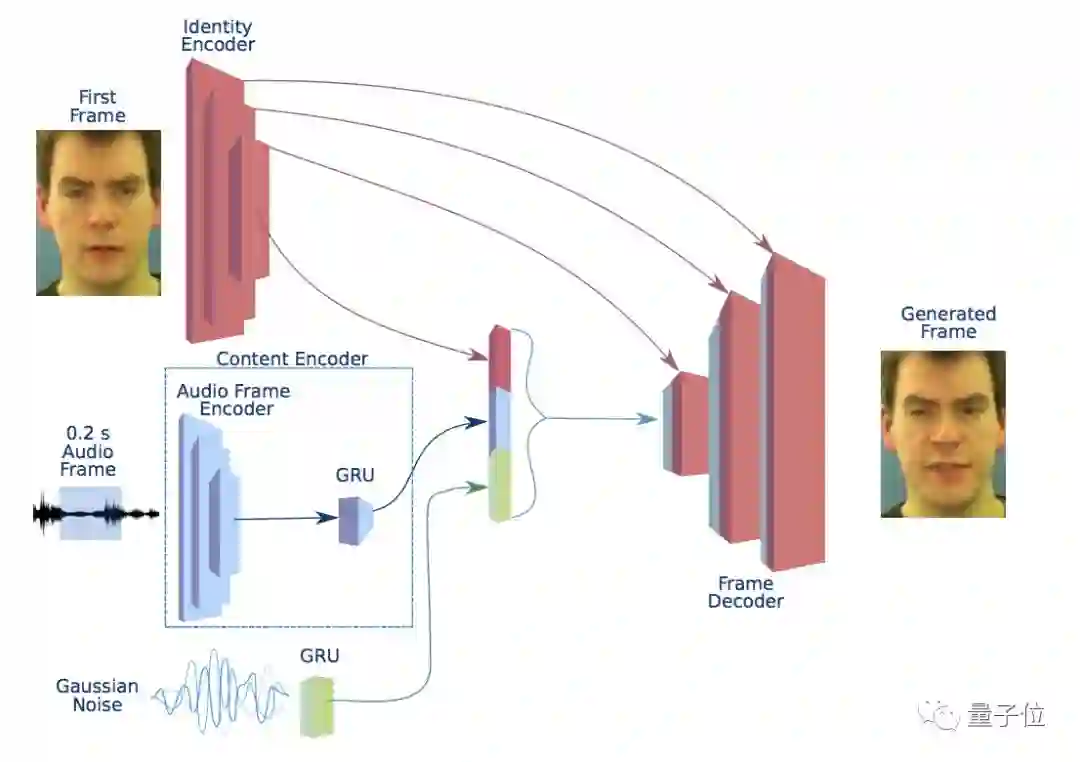
这个系统使用了多个鉴别器来捕捉自然视频的不同方面,各部分各司其职。
帧鉴别器(Frame Discriminator)是一个6层的卷积神经网络,来决定一帧为真还是假,同时实现对说话人面部的高质量视频重建。
序列鉴别器(Sequence Discriminator)确保各个帧能形成一个连贯的视频,显示自然运动。
同步鉴别器(Synchronization Discriminator)加强了对视听同步的要求,决定画面和音频应该如何同步。它使用了两种编码器获取音频和视频的嵌入信息,并基于欧式距离给出判断。
同步鉴别器的结构如下:

就是这样,无需造价高昂的面部捕捉技术,只需这样一个网络,就能将一张照片+一段音频组合成流畅连贯的视频了。
30多篇CVPR的作者
这项研究共有三位作者,分别为Konstantinos Vougioukas、Stavros Petridis和Maja Pantic,均来自伦敦帝国学院iBUG小组,主攻智能行为理解,其中二作和三作也是英国三星AI中心的员工。

一作Konstantinos Vougioukas2011年在佩特雷大学获得电气与计算机工程专业的本科学位后,奔赴爱丁堡大学攻读人工智能方向的硕士学位。

现在,Konstantinos Vougioukas在伦敦帝国学院的Maja Pantic教授(本文三作)的指导下攻读博士,主要研究方向为人类行为合成和面部行为合成。
Maja Pantic教授是iBUG小组的负责人,也是剑桥三星AI中心的研究主任,她在面部表情分析、人体姿态分析、情绪和社会信号是挺分析等方面发表过超过250篇论文,引用次数超过25000次。

从2005年开始,Maja Pantic带学生发了30多篇CVPR(包含workshop)论文。
Maja Pantic教授主页:
https://ibug.doc.ic.ac.uk/people/mpantic
传送门
论文Realistic Speech-Driven Facial Animation with GANs地址:
https://arxiv.org/abs/1906.06337
项目主页:
https://sites.google.com/view/facial-animation
GitHub:
https://github.com/DinoMan/speech-driven-animation
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得



