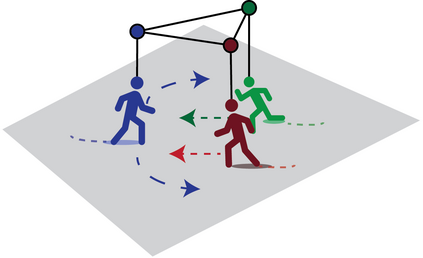
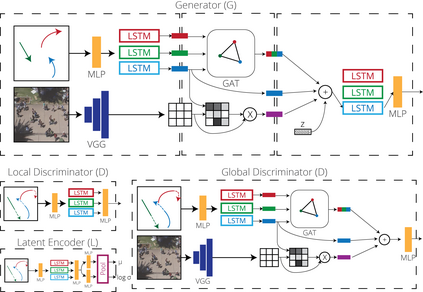
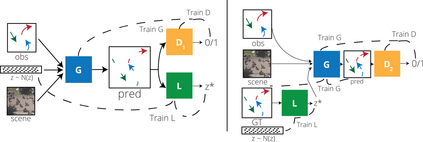
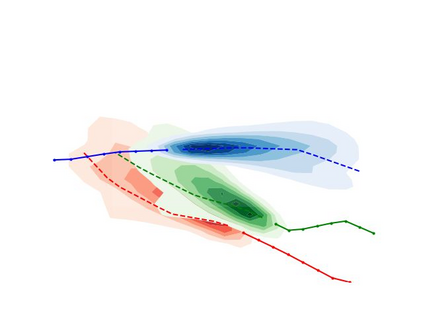
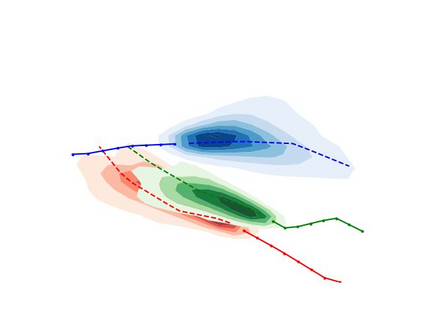
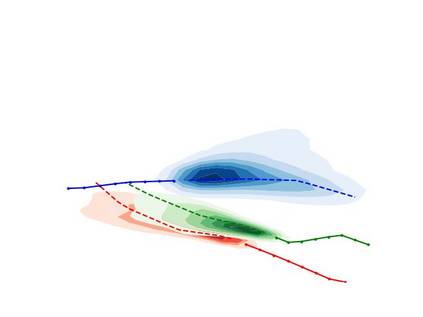
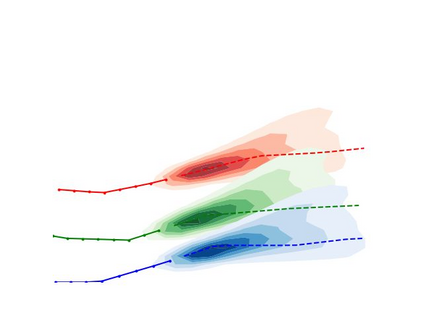
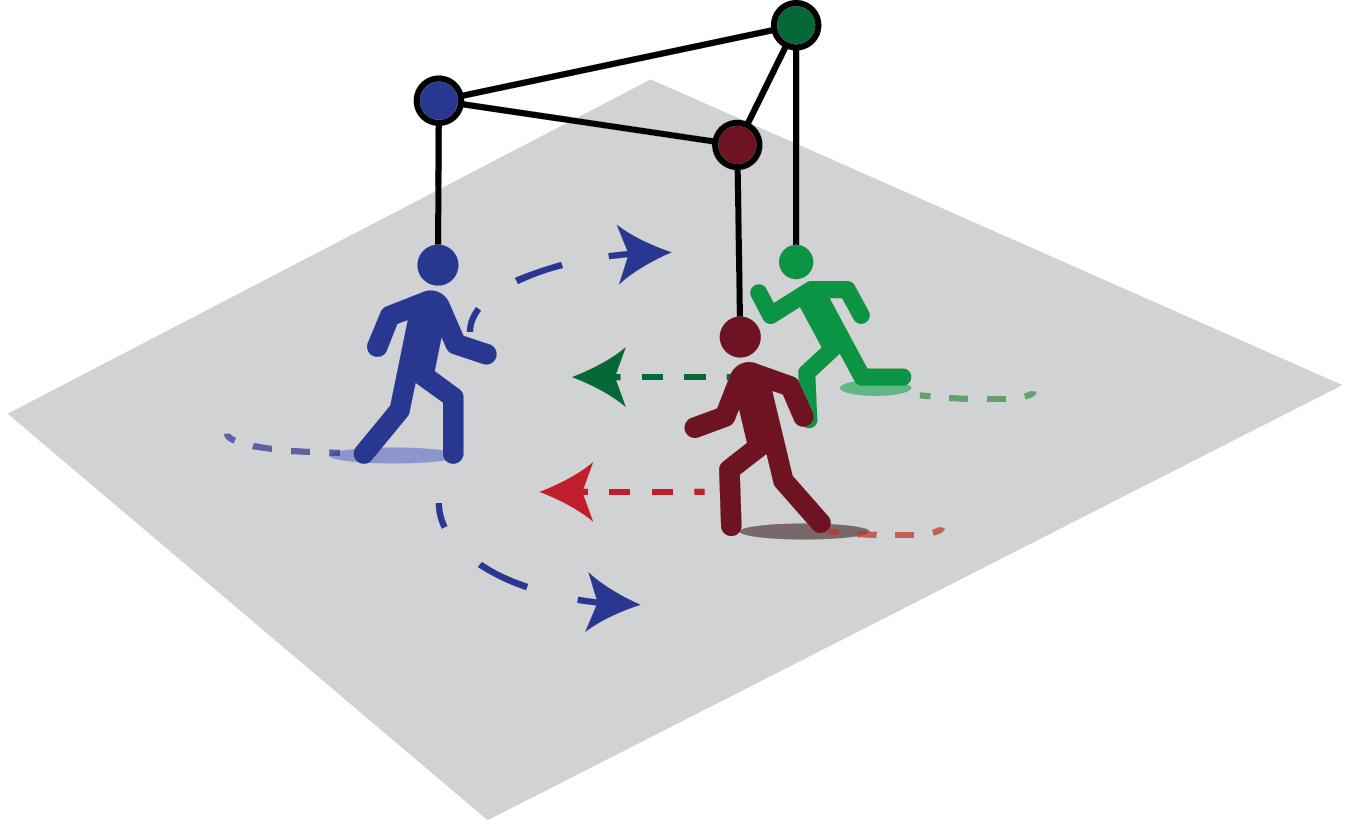
Predicting the future trajectories of multiple interacting agents in a scene has become an increasingly important problem for many different applications ranging from control of autonomous vehicles and social robots to security and surveillance. This problem is compounded by the presence of social interactions between humans and their physical interactions with the scene. While the existing literature has explored some of these cues, they mainly ignored the multimodal nature of each human's future trajectory. In this paper, we present Social-BiGAT, a graph-based generative adversarial network that generates realistic, multimodal trajectory predictions by better modelling the social interactions of pedestrians in a scene. Our method is based on a graph attention network (GAT) that learns reliable feature representations that encode the social interactions between humans in the scene, and a recurrent encoder-decoder architecture that is trained adversarially to predict, based on the features, the humans' paths. We explicitly account for the multimodal nature of the prediction problem by forming a reversible transformation between each scene and its latent noise vector, as in Bicycle-GAN. We show that our framework achieves state-of-the-art performance comparing it to several baselines on existing trajectory forecasting benchmarks.
翻译:预测一个场景中多个互动剂的未来轨迹已成为许多不同应用的日益重要问题,从控制自主车辆和社会机器人到安全和监视等,这个问题由于人类之间的社会互动及其与场景的物理互动而变得更加复杂。虽然现有文献探讨了其中的一些提示,但主要忽视了每个人类未来轨迹的多式性质。在本文中,我们介绍了社会-BiGAT,这是一个基于图形的基因对抗网络,它通过更好地模拟一个场景中行人的社会互动而产生现实的多式轨迹预测。我们的方法基于一个图形关注网络(GAT),它学习可靠的地貌表现,记录了现场人之间的社会互动,以及一个经常性的编码器解码器结构,这种结构经过了对抗性的培训,可以根据这些特征预测人类未来轨迹。我们明确地解释了预测问题的多式性质,在每一场景及其潜在噪声矢量之间形成可逆转的转变,就像在Bicyclo-GAN中那样。我们展示了我们的框架实现了对当前几条基线轨迹进行对比的状态的状态预测。