5300亿!巨型语言模型参数每年暴涨10倍,新「摩尔定律」要来了?

新智元报道
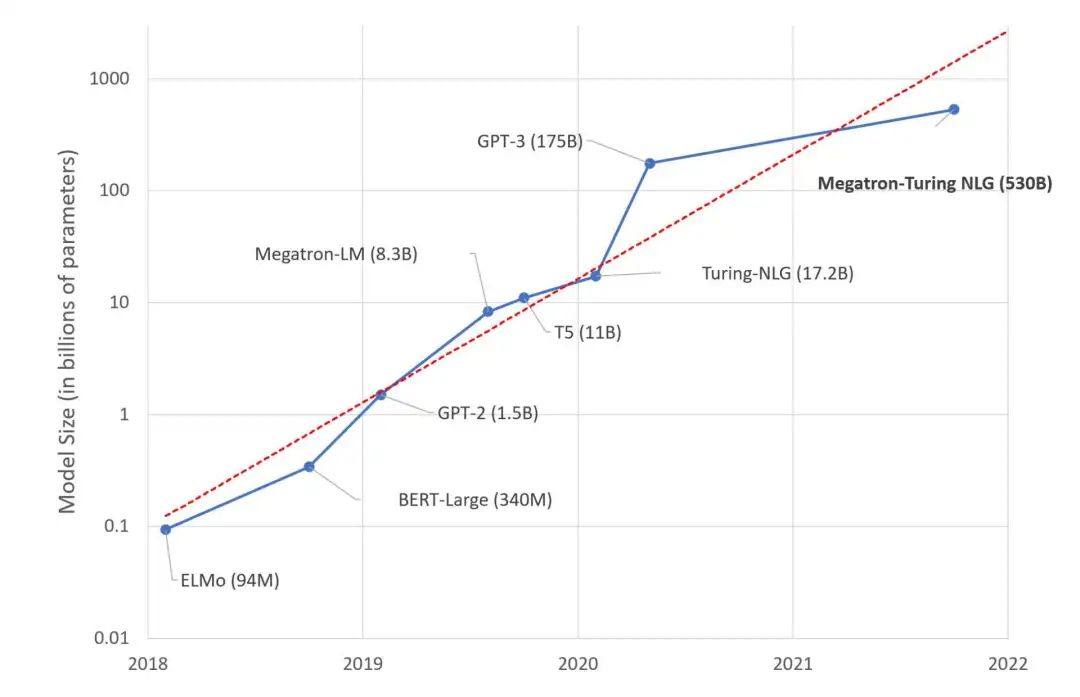
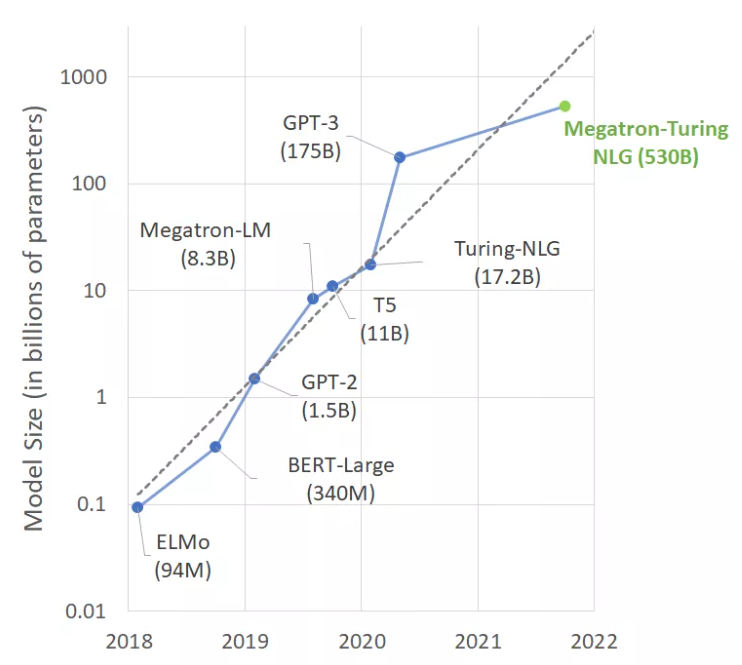
【新智元导读】近年来,大型语言模型参数量每年暴增10倍,最近的巨无霸模型MT-NLG,参数更是达到了5300亿!关于模型参数的「新摩尔定律」已呼之欲出。不过,这可不一定是好事。
大脑的深度学习
研究人员估计,人类大脑平均包含860亿个神经元和100万亿个突触。但不是所有的都用于语言。有趣的是,GPT-4预计将有大约100万亿个参数。

这会是一个巧合吗?我们不禁思考,建立与人脑大小差不多的语言模型是否是一个长期可行的方法?
是深度学习,还是「深度钱包」?
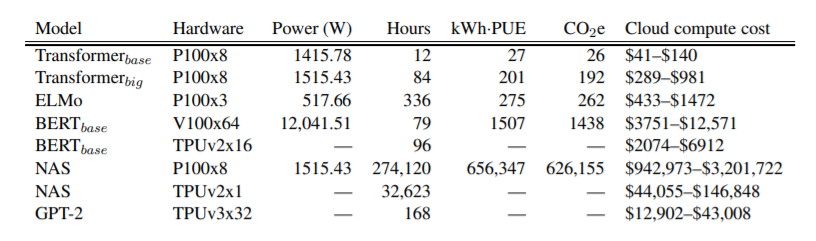
在庞大的文本数据集上训练一个5300亿个参数模型,无疑需要庞大的基础设施。

GPU集群:散热、环保都成问题
实际上,在GPU上训练深度学习模型是一项十分费力的事情。

使用预训练模型
绝大多数情况下,并不需要定制模型体系结构。
使用小模型

微调模型
需要收集、存储、清理和注释的数据更少
实验和数据迭代的速度更快
获得产出所需的资源更少
使用云基础设施

优化模型
从编译器到虚拟机,软件工程师长期以来一直使用工具来自动优化硬件代码。

硬件:大量面向加速训练任务(Graphcore、Habana)和推理任务(Google TPU、AWS Inferentia)的专用硬件。
剪枝:删除对预测结果影响很小或没有影响的模型参数。
融合:合并模型层(比如卷积和激活)。
量化:以较小的值存储模型参数(比如使用8位存储,而不是32位存储)
另一个「摩尔定律」要来了吗?

参考链接:
https://huggingface.co/blog/large-language-models

登录查看更多
相关内容
专知会员服务
99+阅读 · 2020年7月3日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
15+阅读 · 2021年9月22日




相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
15+阅读 · 2021年9月22日