深度学习发展下的“摩尔困境”,人工智能又将如何破局?

来源:AI科技大本营
本文约1910字,建议阅读4分钟
本文介绍了在Ignite大会上,微软正式宣布进军「元宇宙」,并将旗下混合现实会议平台Mesh融入到Teams中。
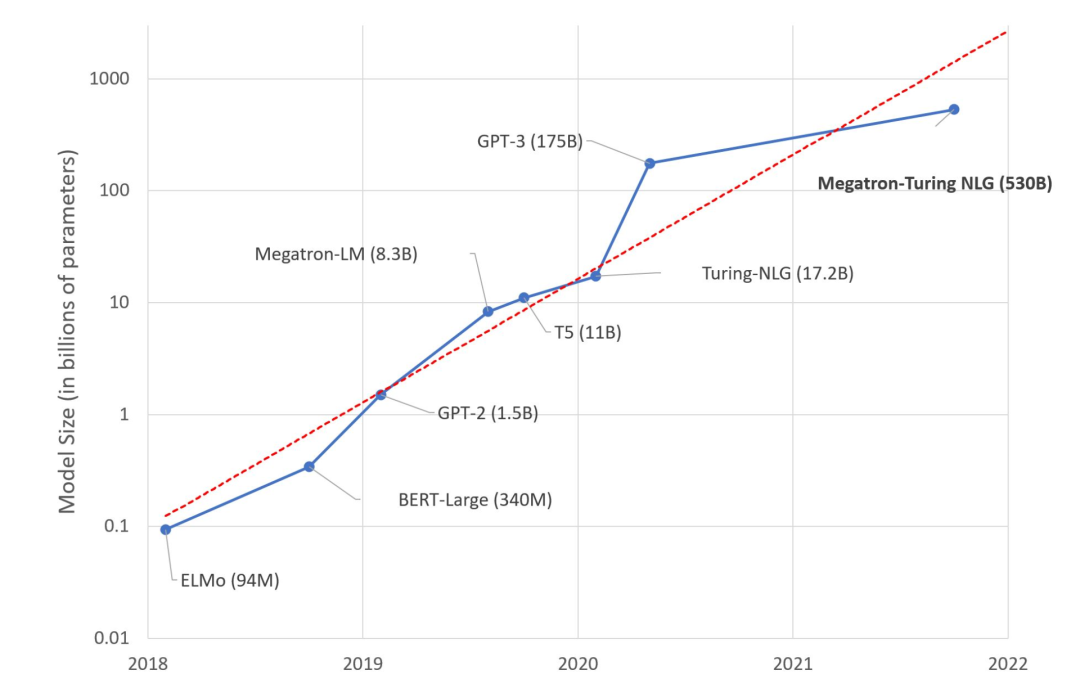
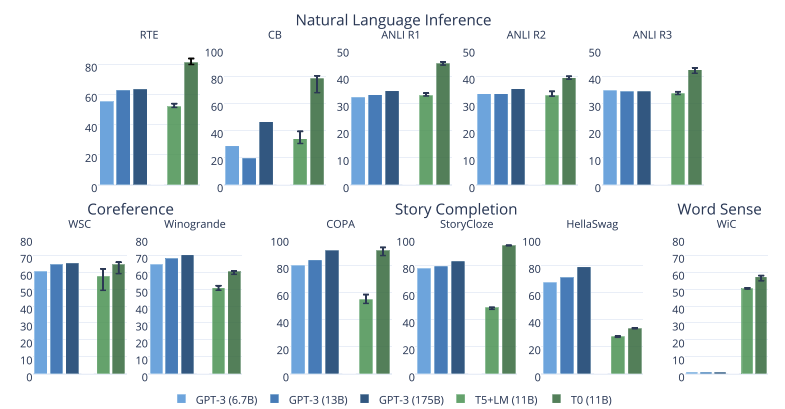
-
需要收集、存储、清理和注释的数据更少 -
实验和数据迭代的速度更快 -
获得产出所需的资源更少
07. 使用基于云的基础设施
-
硬件:大量面向加速训练任务(Graphcore、Habana)和推理任务(Google TPU、AWS Inferentia)的专用硬件。 -
剪枝:删除对预测结果影响很小或没有影响的模型参数。 -
融合:合并模型层(比如卷积和激活)。 -
量化:以较小的值存储模型参数(比如使用8位存储,而不是32位存储)

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
15+阅读 · 2021年9月22日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
15+阅读 · 2021年9月22日