谷歌自证清白?Jeff Dean 团队发文佐证AI模型不会产生大量碳足迹

新智元报道
新智元报道
来源:venturebeat
编辑:yaxin
【新智元导读】近日,谷歌研究人员发表的一篇论文认为大型人工智能模型不会产生大量碳排放,并通过对5大NLP模型进行训练评估来佐证这一观点。

人工智能碳排放的影响有多大?

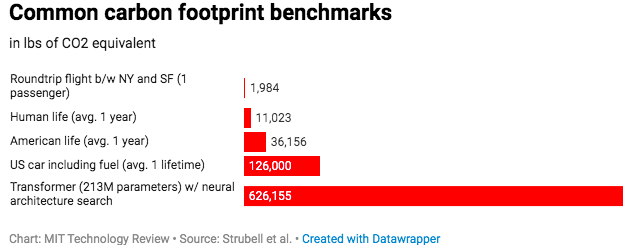

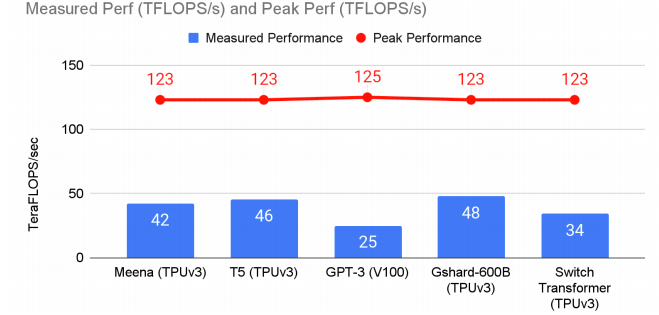
训练5种NLP模型,碳足迹量并不多

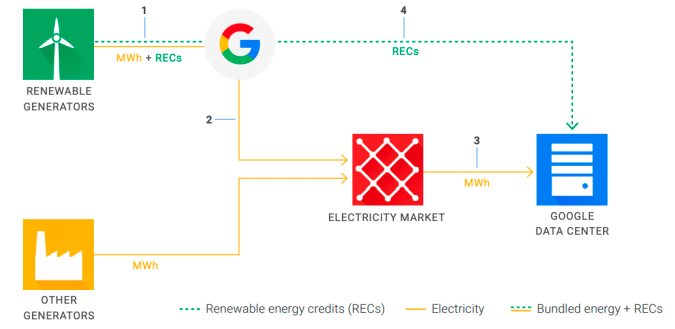
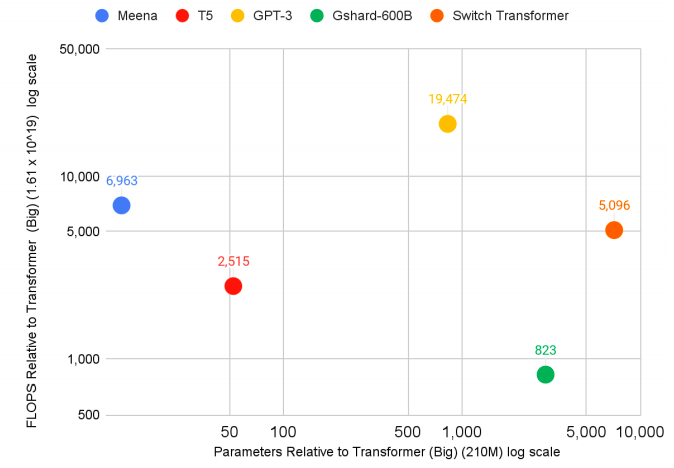
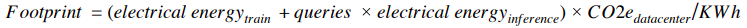
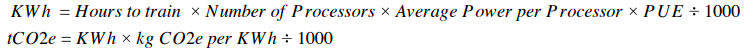
论文只是为了谷歌的商业利益?

https://venturebeat.com/2021/04/29/google-led-paper-pushes-back-against-claims-of-ai-inefficiency/

AI家,新天地。西山新绿,新智元在等你!
【新智元高薪诚聘】主笔、高级编辑、商务总监、运营经理、实习生等岗位,欢迎投递简历至wangxin@aiera.com.cn (或微信: 13520015375)
办公地址:北京海淀中关村软件园3号楼1100

登录查看更多
相关内容

Google Research Group的Google高级研究员,他与人共同创立并领导了Google Brain团队,即Google的深度学习和人工智能研究团队。他和他的合作者正在研究语音识别,计算机视觉,语言理解和各种其他机器学习任务的系统。Jeff在Google期间,曾对Google的爬网,索引和查询服务系统,Google的主要广告和AdSense for content系统的主要部分以及Google的分布式计算基础结构(包括MapReduce,BigTable和Spanner)进行代码签名。杰夫(Jeff)是ACM和AAAS,美国国家工程院院士,计算机科学ACM -Infosys基金会奖获得者。他拥有华盛顿大学的计算机科学博士学位,在那里他与Craig Chambers一起研究了面向对象语言的全程序优化技术,并获得了明尼苏达大学的计算机科学和经济学学士学位。
Arxiv
0+阅读 · 2021年6月22日
Arxiv
0+阅读 · 2021年6月22日
Arxiv
6+阅读 · 2020年8月20日
Arxiv
11+阅读 · 2019年10月30日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年6月22日
Arxiv
0+阅读 · 2021年6月22日
Arxiv
6+阅读 · 2020年8月20日
Arxiv
11+阅读 · 2019年10月30日