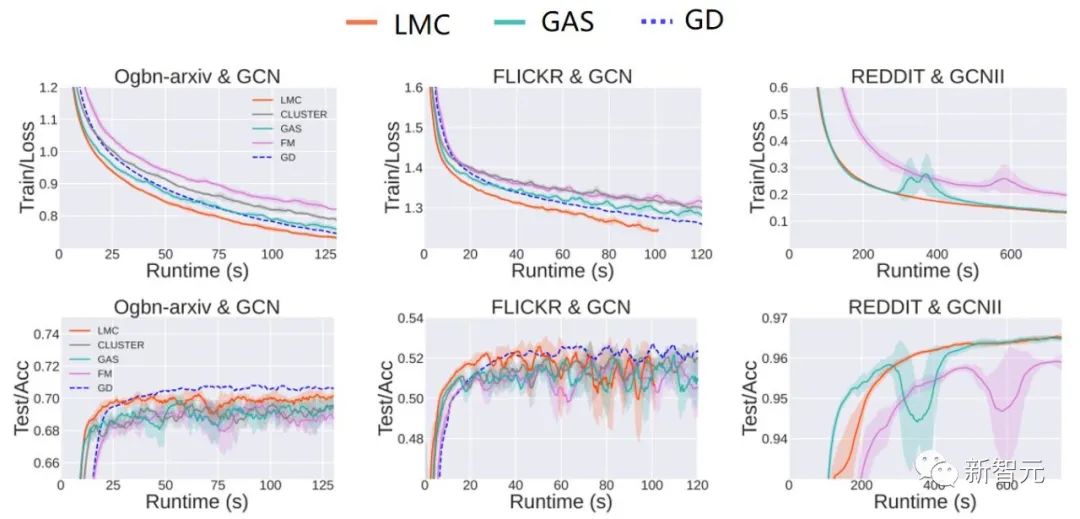
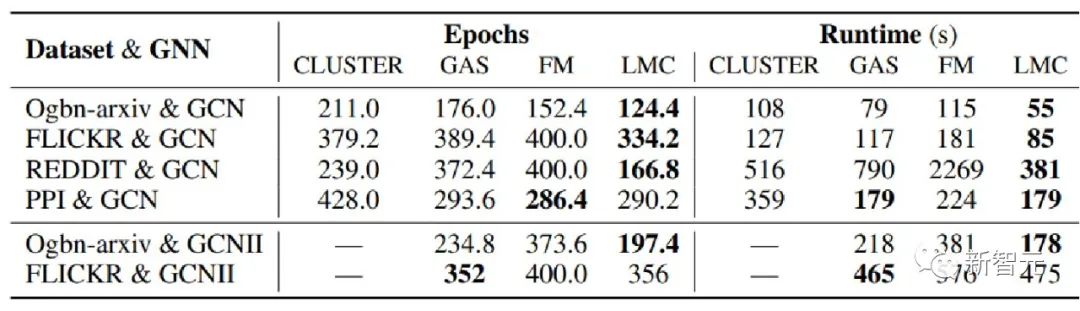
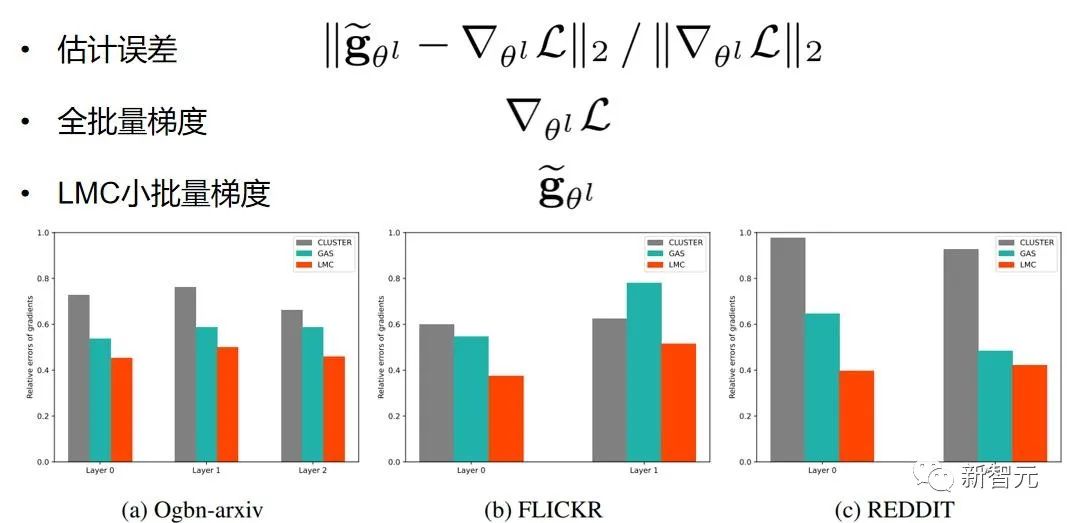
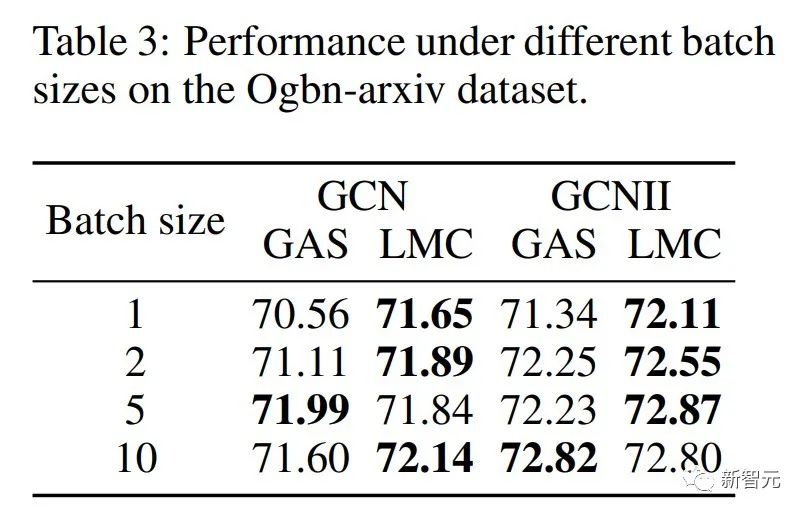
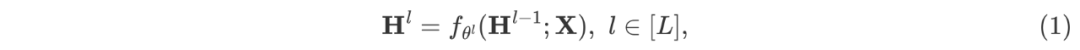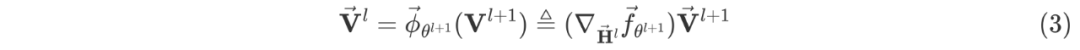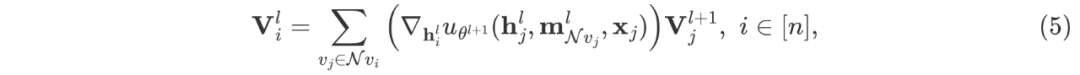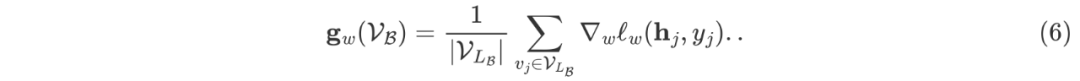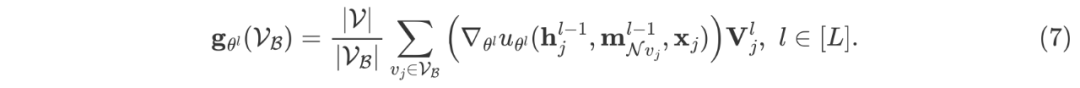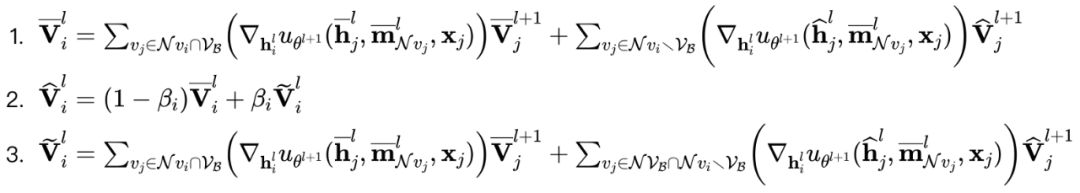进一步做了 small batch size 下的实验,前面在子图采样算法中举了一个例子,子图规模很小的话,丢弃的节点就很多,很容易达到次优。如表三所示,我们的方法对 batch size 更加鲁棒,因此在计算资源受限的情景下,LMC的优势会更加明显。
▲ 图6. 不同批量大小的表现
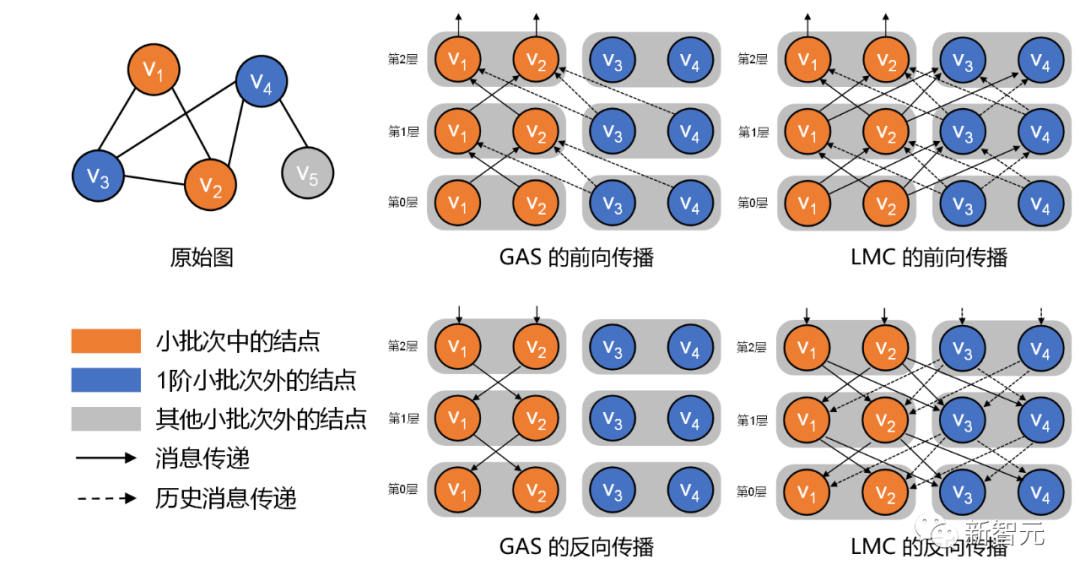
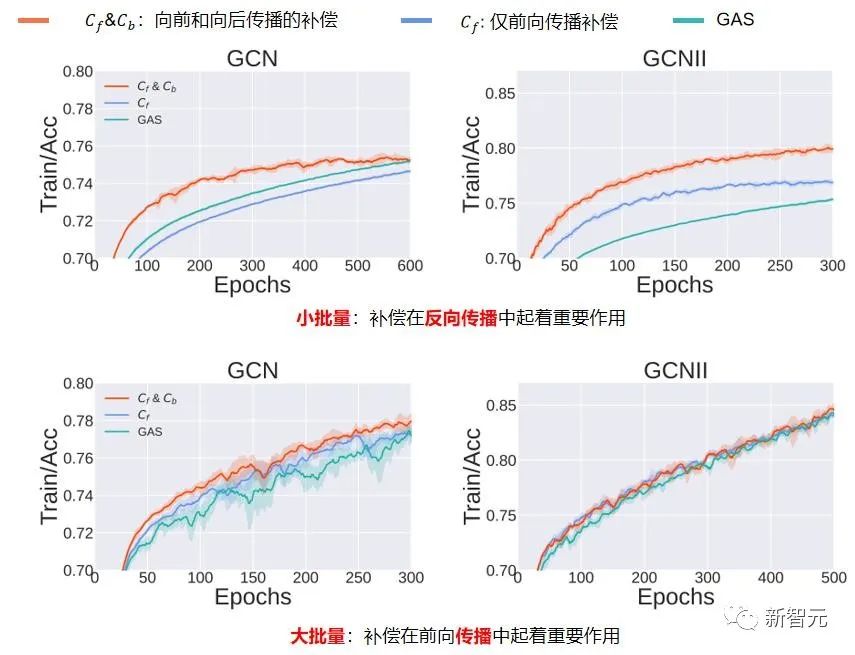
最后是消融实验,相对于 SOTA 的 GAS 方法,我们对前向传播过程的补偿消息进行了改进,并且在反向传播也加入了一个补偿。如图7所示,我们发现,在batch size很小的情况下,反向传播的补偿很重要,因为这一 设定下,丢弃了很多消息,导致收敛到次优解。在batch size较大的时候,采样子图一阶邻居是很大的,我们通过采样子图一阶邻居内部的消息传递,提高了历史信息的准确率,也能提高子图采样算法的性能。
▲ 图7. 消融实验
参考文献
[1] Hamilton, William L. "Graph representation learning." Synthesis Lectures on Artifical Intelligence and Machine Learning 14.3 (2020): 1-159.[2] Brin, Sergey, and Lawrence Page. "The anatomy of a large-scale hypertextual web search engine." Computer networks and ISDN systems 30.1-7 (1998): 107-117.[3] Fan, Wenqi, et al. "Graph neural networks for social recommendation." The world wide web conference. 2019.[4] Gostick, Jeff, et al. "OpenPNM: a pore network modeling package." Computing in Science & Engineering18.4 (2016): 60-74.[5] Moloi, N. P., and M. M. Ali. "An iterative global optimization algorithm for potential energy minimization." Computational Optimization and Applications 30 (2005): 119-132.[6] Kearnes, Steven, et al. "Molecular graph convolutions: moving beyond fingerprints." Journal of computer-aided molecular design 30 (2016): 595-608.[7] Wang, Zhihai, et al. "Learning Cut Selection for Mixed-Integer Linear Programming via Hierarchical Sequence Model." arXiv preprint arXiv:2302.00244 (2023).[8] Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." Advances in neural information processing systems 30 (2017). [9] Chen, Jianfei, Jun Zhu, and Le Song. "Stochastic training of graph convolutional networks with variance reduction." arXiv preprint arXiv:1710.10568 (2017).[10] Chen, Jie, Tengfei Ma, and Cao Xiao. "Fastgcn: fast learning with graph convolutional networks via importance sampling." arXiv preprint arXiv:1801.10247 (2018).[11] Zou, Difan, et al. "Layer-dependent importance sampling for training deep and large graph convolutional networks." Advances in neural information processing systems 32 (2019).[12] Huang, Wenbing, et al. "Adaptive sampling towards fast graph representation learning." Advances in neural information processing systems 31 (2018).[13] Chiang, Wei-Lin, et al. "Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks." Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019.[14] Zeng, Hanqing, et al. "Graphsaint: Graph sampling based inductive learning method." arXiv preprint arXiv:1907.04931 (2019).[15] Fey, Matthias, et al. "Gnnautoscale: Scalable and expressive graph neural networks via historical embeddings." International Conference on Machine Learning. PMLR, 2021.[16] Zeng, Hanqing, et al. "Decoupling the depth and scope of graph neural networks." Advances in Neural Information Processing Systems 34 (2021): 19665-19679.[17] Cong, Weilin, et al. "Minimal variance sampling with provable guarantees for fast training of graph neural networks." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.