计算所网络数据社会计算组共获3篇CIKM论文
ACM CIKM是国际计算机学会主办的基于informationretrieval, data management, and knowledge management的重要会议,CIKM2017已于上周在新加坡完美落幕。本次会议共收到长文855篇,录用171篇(录用率20%),收到短文398篇,录用119篇(录用率30%),竞争异常激烈。此次会议共有800多人参加,包括40多个国家的顶尖研究人员和国内外企业巨头,盛况空前。
而就在竞争如此激烈的CIKM盛会中,中科院计算所网络数据科学与技术重点实验室的NASC组共收获了3篇论文(实验室共收获5篇论文),分别为:
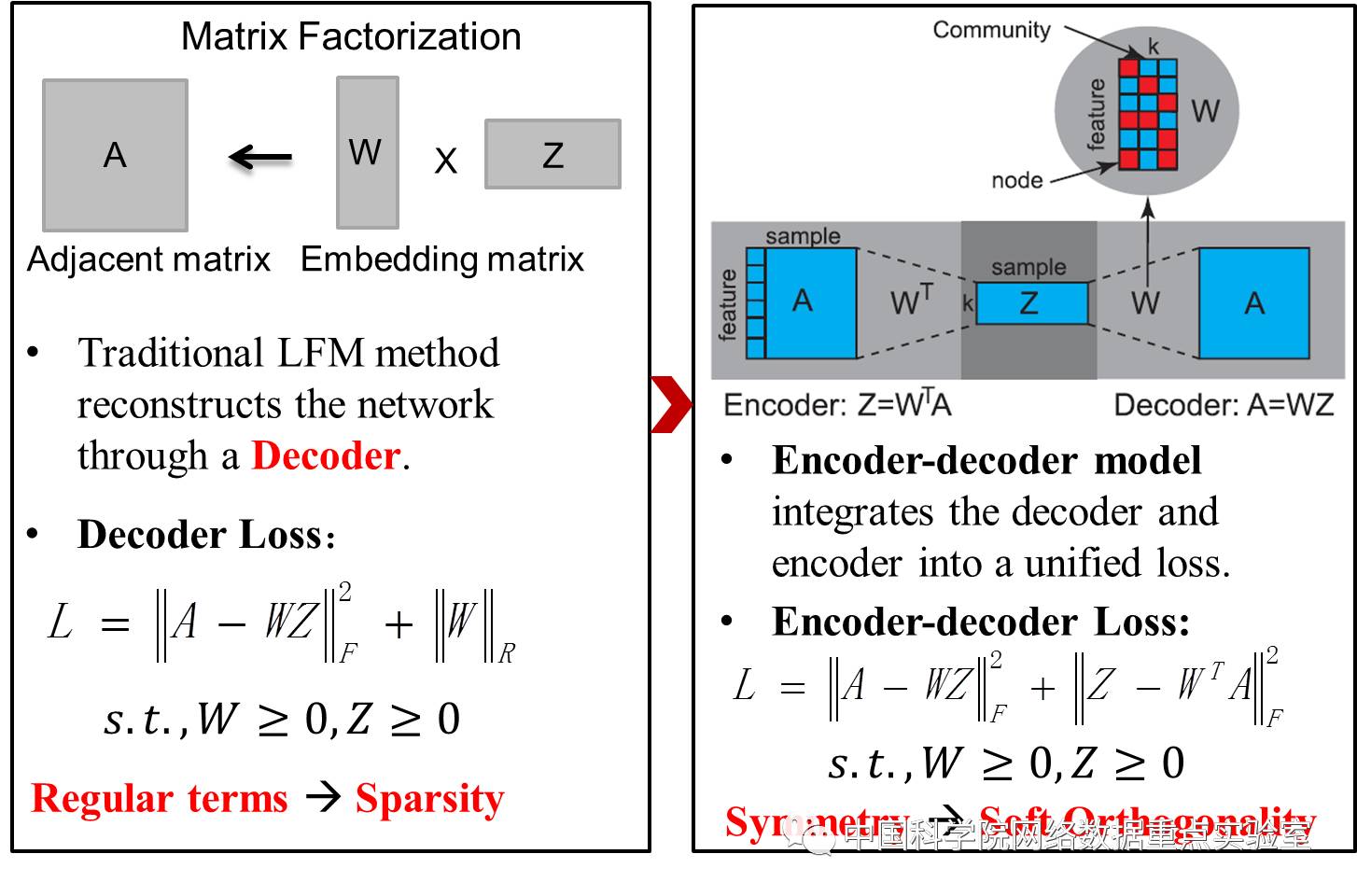
“A Non-negative Symmetric Encoder-Decoder Approach for CommunityDetection”(作者:孙冰杰,沈华伟,高金华,欧阳文涛,程学旗)
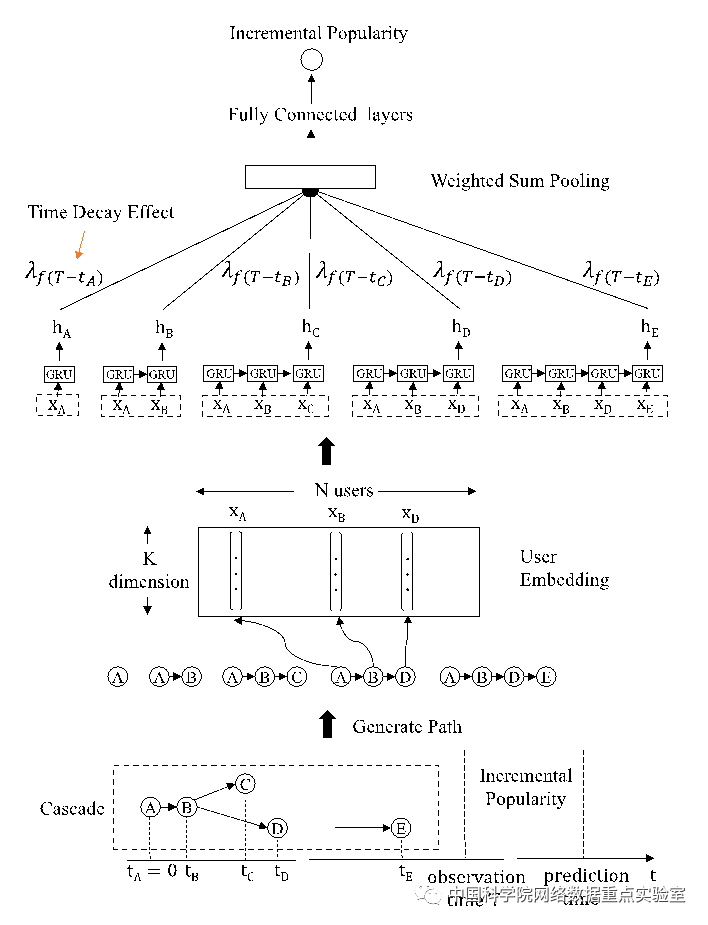
“DeepHawkes: Bridging the Gap between Prediction and Understandingof Information Cascades”(作者:曹婍,沈华伟,岑科廷,欧阳文涛,程学旗)
“Truth Discovery by Claim and Source Embedding”(短文,作者:吕珊珊,欧阳文涛,沈华伟,程学旗)
三篇论文分别致力于解决重叠社区发现、流行度预测以及真相发现这三个问题,弥补了之前研究方法的不足,同时在方法上也有一定的新颖性,并且在多个真实数据集上验证了方法的有效性。下图为NASC研究组在会议上汇报的情况,受到了其他研究人员的一致认可。


现将三篇论文的内容简要介绍如下:
A Non-negative Symmetric Encoder-Decoder Approach for CommunityDetection
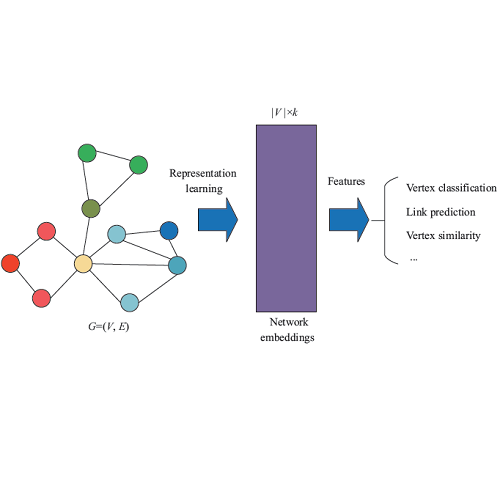
传统的社区发现工作寻找节点关于社区的表示,因此是一种典型的网络节点表示方法。然而社区发现中的节点表示除了指示性作用之外,无法应用于其他任务。Network Embedding方法(如,DeepWalk和LINE等),得到的节点表示可以很好的还原原始空间中的数据相似性,可以支持多种下游任务,但是节点表示本身可解释性很差。很自然的,我们可以想到将两者结合一下,这就是基于隐因子模型(Latent Factor Model, LFM)的方法,这类方法得到的节点表示既可以指示节点的重叠社区归属也可以在一定程度上反映节点在原空间中的相似性,因此成为目前比较流行的方法。
然而,基于LFM的方法只是在对原始数据进行重构,相当于一个解码过程(Decoder)。因为LFM优化目标函数中缺少了编码过程(Encoder)导致整个模型容易陷入局部最优并且无法处理新样本数据。因此本文提出了同时优化编解码过程的方法,这就是我们将Community detection和Network Embedding融合在一起,我们站在更高的层次上,反思之后看到的问题。
通过编解码过程的对称性使得整个模型可以简单的实现隐式稀疏性约束。增加了编码过程,带来的好处是模型可以快速准确的编码新样本数据,得到的节点表示可以精确支持多种类型输入(邻接矩阵、节点序列等)下的多种类的任务(社区发现、连边预测等)。
我们工作的意义在于站在网络化数据表示学习之上,为Community detection和Network embedding都注入了新的血液,可以容纳更多可以研究的问题,或许我们只是在一个新的靶子上射了一箭,但即使是抛砖引玉能让大家有所思考和收获,也不虚此次CIKM 2017之行了。(详细请参考具体的论文)
DeepHawkes: Bridging the Gap between Prediction and Understanding ofInformation Cascades
随着诸如新浪微博、推特、脸书等社交平台的兴起,信息的发布和传播变得前所未有的方便。每天有成千上万的消息在这些平台上产生,竞争着所有用户有限的关注度。如何能在如此大的消息体量下预测出未来的热门消息,对于用户和平台方而言都是一件意义重大的事情,而这也正是本工作旨在解决的问题。
传统的消息流行度预测的方法或者是基于特征提取的机器学习方法——监督于未来要预测的流行度,具有较好的预测性能,但缺乏对于信息传播机制的理解;或者是基于生成式的点过程建模方法——旨在建模信息传播的机制,但每条消息单独建模,预测性能较差。换句话说,现有的方法在信息传播的预测性和理解性之间还存在着一条鸿沟,这也就启发我们设计一个在端到端框架下建模信息传播机制的模型,即DeepHawkes模型。该模型通过端到端的方式自动学习了用户的影响力表达,同时建模了传播路径在流行度预测中的作用。此外,我们还用了一种非参的方式来灵活地学习不同场景下的影响力衰减函数。模型的整体框架如下图所示。基于微博数据集以及论文数据集的实验结果证明,我们提出的DeepHawkes模型在有效提升模型预测性能的同时,也深层次地对信息传播的机制进行了理解建模,填补了流行度预测问题中预测性和理解性之间的鸿沟。
该工作的模型代码目前已经公开发布在了Github上,项目的访问地址为https://github.com/CaoQi92/DeepHawkes。同时,我们还在该项目中提供了论文中使用的微博数据集的下载链接。由于该数据集包含有转发路径的信息,可以供感兴趣的研究者用于进一步探索转发路径在流行度预测中所起的作用。
Truth Discovery by Claim and Source Embedding
真相发现(TruthDiscovery)技术,不明思议,就是一种自动的、可以从互相矛盾的信息中找到正确信息的一种技术。
随着信息时代的到来,人们从网络上获取信息的频率不断增加,然而不同网站提供的信息总是存在差异。这就需要人们去分辨哪部分信息是正确的。真相发现技术应运而生。
下图为此篇论文的poster。

现有的真相发现方法主要可以分为两类:迭代方法和概率方法。在迭代方法中,通过人工定义的某种迭代规则,最后可以得到不同信息的可信度,可信度最高的信息会被认定为正确的信息;然而这类方法中的迭代规则是人工定义的,没有准确的依据而且难以进行分析。另一种概率方法建模信息源提供信息的过程,认为多种因素会影响这个过程;然而这些因素也是人工定义的,并不能准确反映数据的真实分布。
为了弥补之前的不足,我们提出了一种基于表达学习的无监督方法(Claim and Source Embedding),该方法不需要任何人工定义的部分,因为它可以自动的从数据中学到信息的可信度,从而更真实的反映了数据的分布。该方法把数据中信息源和信息的关系以及信息源之间的关系建模到一个异质网络中,然后把这个异质网络映射到低维空间,得到信息源和信息的表达。在低维空间中,可靠的信息源与可信的信息之间距离相近,同时与不可靠的信息源和不可信的信息距离相距较远。实验表明,所提出的基于表达学习的方法,在真相发现问题中超过了基于迭代规则的方法和基于概率的方法。