ECCV 2020 Oral | 可逆图像缩放:完美恢复降采样后的高清图片
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:Shuxin Zheng
https://zhuanlan.zhihu.com/p/150340687
本文已由原作者授权,不得擅自二次转载
不知道同学们平日里上网有没有遇到过这种情况:自己精心拍摄的高清照片/视频,想发给朋友or分享到朋友圈/微博/抖音/知乎,结果上传文件之后,直接被无良服务器压成超低分辨率渣画质。甚至有些图片/表情包在经过多次传播之后,画质已经糊到惨不忍睹。
其实,图片的降采样(缩放)可以说是对数字图像最常见的操作了,它的用处多种多样:压缩图片尺寸、节省服务器存储or带宽、适配不同分辨率的屏幕等等。像现在服务器资源这么贵,大家发微博/知乎也不交钱,顶多给各位多塞点广告,所以高清图片和视频自然是能压则压,能分得清张一山和夏雨就可以了。
如何恢复降采样后的图片是图像处理中一个非常有挑战的问题,一直没有被很好的解决。今天给大家介绍一篇我们在ECCV2020上最新的Oral工作,巧妙地尝试从本质上解决这个问题。

论文地址:https://arxiv.org/abs/2005.05650
代码和预训练模型:github (最后清理阶段,很快放出)
https://github.com/pkuxmq/Invertible-Image-Rescaling
对降采样后图片的原图求解是一个典型的病态(ill-posed)问题:
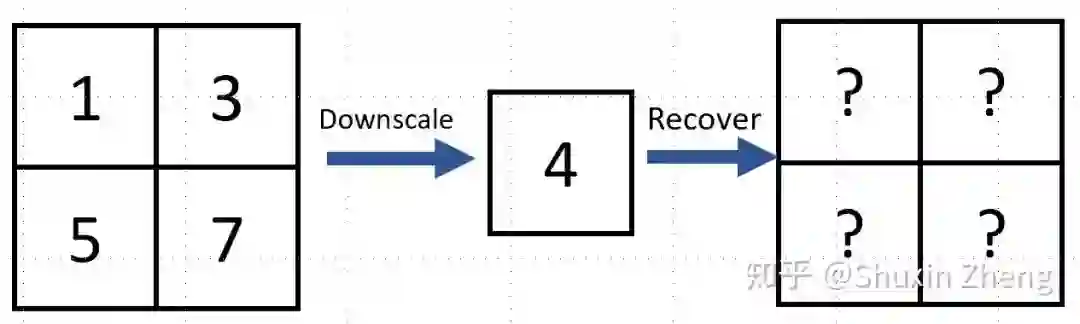
现在有一张图片有4个像素,值分别为1,3,5,7。假设对原图进行双线性插值降采样(Bilinear Interpolation),得到像素值为4的低分辨率图片。那么,如何从这一个像素还原出原图呢?
这个问题太难了,有太多种4个像素取值的组合都可以得到同样一张低分辨率图片。如果是4x降采样,则会有16个像素被采样成一个点。。想要精确地从一个像素还原出原图?你看看那些像素上的"?"眼熟不。。。

为什么这是一个病态问题?这是因为在降采样的过程中存在着信息的丢失(information loss), 以至于无法很好地还原回原图。而前人的做法一般是使用一个超分辨率的卷积神经网络,尝试从大量的数据中强行学习低分辨率到高分辨率的映射关系;或者使用encoder网络对原图进行降采样,同时使用decoder网络还原图片,二者进行联合训练(jointly training)达到更好的效果。但以上这些方法都没有从本质上解决病态问题,效果也不尽如人意。因此我们需要更聪明的方法来解决病态问题。
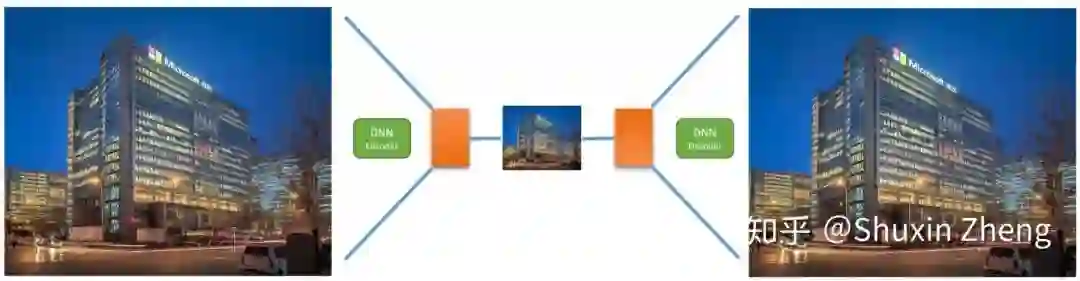
刚才提到了病态问题的产生是由于信息的丢失,那么具体是什么信息被丢失了呢?
“ High-frequency content will get lost during sample rate conversion.”
--Nyquist-Shannon Sampling Theorem
正是由于高频信息的丢失导致了我们无法很好的还原高清原图,那么如果我们“保留”这些高频信息呢?
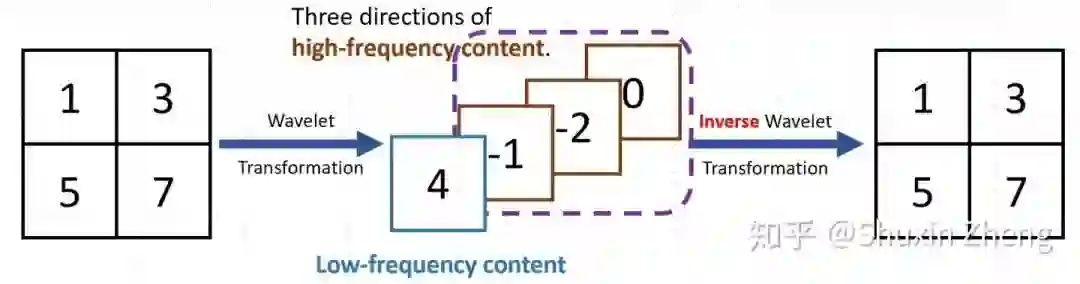
为了可以显式地保留高频信息,我们将降采样的过程替换为小波变换:由小波变换我们可以得到原图的一个低频分量和三个不同方向的高频分量。这里的低频分量与双线性插值降采样得到的低分辨率结果是一样的,而高频分量则是在降采样过程中被丢失的信息。
当我们选择保留全部信息时,我们可以使用小波变换的逆变换(即反函数,如果 

对于深度学习模型这样一种复杂的非线性函数,它的反函数是什么呢?这里我们要用到可逆神经网络(Invertible NN, INN)模型。对可逆神经网络模型不熟悉的同学,推荐阅读Lilian Weng的博客:Flow-based Generative Model. 我们采用了最简单的Normalizing Flow的形式。这里需要注意,flow-based模型是严格可逆的。从另一个角度来思考这个问题,降采样和升采样本来就是一对逆任务,是否便应当使用可逆神经网络?
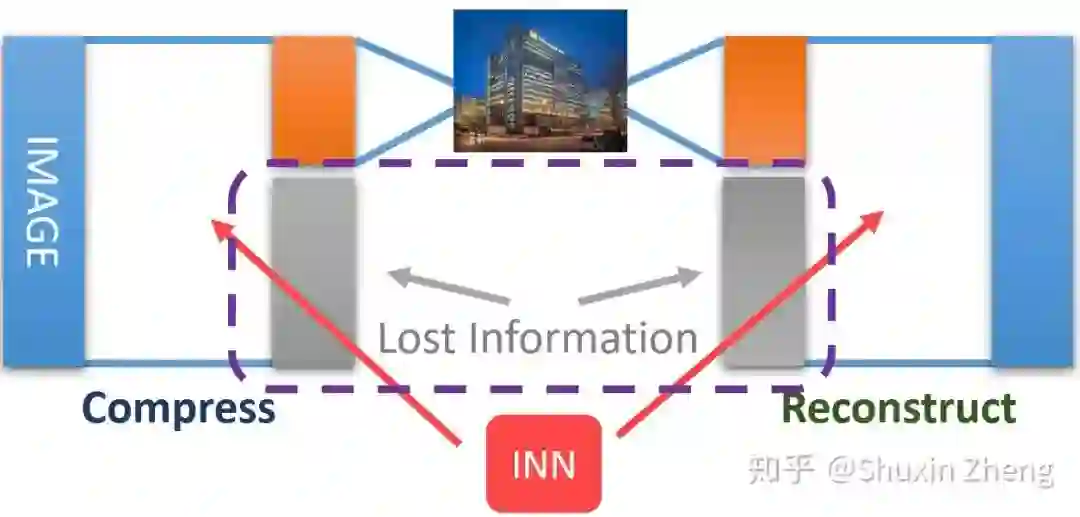
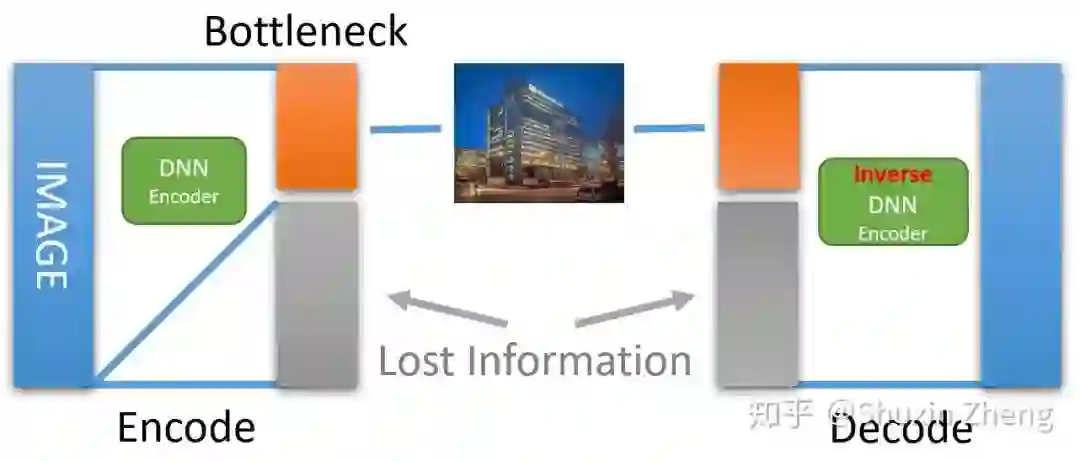
有了可逆神经网络模型,我们可以把之前的Encoder-Decoder网络换成INN和它的反函数,这样,如果我们可以保留全部信息,就能完美地恢复出原始高清图片。然而,我们显然无法在存储、传输低分辨率图片时还附带这些本应被丢失的信息(低分辨率图片的维度+丢失信息的维度=原始图片的维度),而丢弃这些信息又让我们无法使用INN来恢复出原图。所以,折腾了半天又把这条路堵死了?

别急,我们再来回顾一下前面的简单例子:
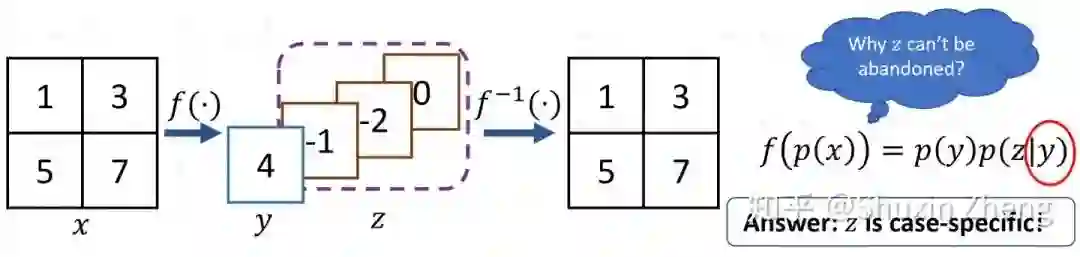
我们令 







此时,轮到我们的INN出场了。我们引入变量 





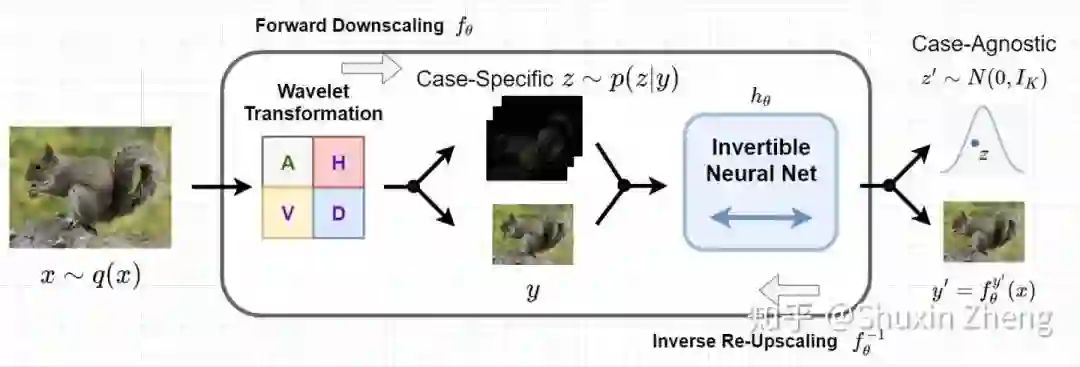
对于case-agnoistic的 

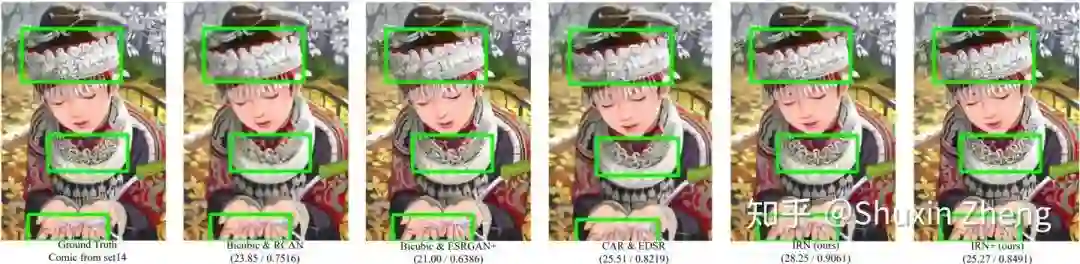
除了性能的大幅提升,更重要的是,得益于建模方法尝试直接解决任务的本质问题,模型所需参数量只需前人方法的1/10~1/30。下面是效果的可视化,请注意绿色框中对原图的还原程度。
更多的细节可以参考论文,包括具体的训练方法、不同采样的
最后总结一下:其实Image Rescaling任务是一个很有挑战、同时在实际场景中应用广泛且商业价值巨大的任务。本文使用可逆神经网络对解决这一对逆任务进行了初步的尝试,沿着这条思路仍有很多值得发掘的点。同时,信息丢失(Information Loss)所导致的ill-posed问题在现实中也大量存在,本文提供的对Lost Information进行建模的视角,相信可以对类似任务有一定的参考价值。
参考
^Nonlinear independent component analysis: Existence and uniqueness results. https://www.sciencedirect.com/science/article/abs/pii/S0893608098001403
下载
在CVer公众号后台回复:ECCV2020,即可下载上述内容
https://github.com/amusi/ECCV2020-Code
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!




