如何处理多种退化类型的卷积超分辨率
本文介绍了 CVPR 2018 的一篇 Poster 论文《Learning a Single Convolutional Super-Resolution Network for Multiple Degradations》

论文地址:http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_SRMD.pdf
1. 摘要
近年来,深度卷积神经网络(CNN)方法在单幅图像超分辨率(SISR)领域取得了非常大的进展。然而现有基于 CNN 的 SISR 方法主要假设低分辨率(LR)图像由高分辨率(HR)图像经过双三次 (bicubic) 降采样得到,因此当真实图像的退化过程不遵循该假设时,其超分辨结果会非常差。此外,现有的方法不能扩展到用单一模型解决多种不同的图像退化类型。为此,提出了一种维度拉伸策略使得单个卷积超分辨率网络能够将 SISR 退化过程的两个关键因素(即模糊核和噪声水平)作为网络输入。归因于此,训练得到超分辨网络模型可以处理多个甚至是退化空间不均匀的退化类型。实验结果表明提出的卷积超分辨率网络可以快速、有效的处理多种图像退化类型,为 SISR 实际应用提供了一种高效、可扩展的解决方案。
2.引言
单幅图像超分辨率(SISR)的目的是根据单幅低分辨(LR)图像输入得到清晰的高分辨率(HR)图像。一般来说,LR 图像 y 是清晰 HR 图像 x 由下面的退化过程得来,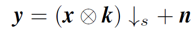
其中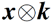
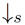
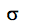
SISR 方法主要分为三类:基于插值的方法、基于模型的方法以及基于判别学习的方法。基于插值的方法(例如:最近邻插值、双三次插值)虽然速度快,但是其效果比较差。基于模型的方法通过引入图像先验,例如:非局部相似性先验、去噪先验等,然后求解目标函数得到视觉质量较好的 HR 图像,然而速度较慢。虽然结合基于 CNN 的去噪先验可以在某种程度上提升速度,但仍然受限于一些弊端,例如:无法进行端对端的训练,包含一些比较难调的参数等。基于判别学习的方法尤其是基于 CNN 的方法因其速度快、可以端对端的学习因而效果好等在近几年受到了广泛关注,并且逐渐成为解决 SISR 的主流方法。
自从首个用 CNN 解决 SISR 的工作 SRCNN 在 ECCV(2014)发表以来,各种不同的改进方法相继提出。例如,VDSR 在 PSNR 指标上取得了非常大的提升;ESPCN 和 FSRCNN 分别在速度上进行了改进;SRGAN 在放大倍数较大情况下针对视觉效果的改善提出了有效的方法。然而这些方法都存在一个共同缺点,也就是它们只考虑双三次 (bicubic) 降采样退化模型并且不能灵活的将其模型扩展到同时(非盲)处理其它退化类型。由于真实图像的退化过程多种多样,因而此类方法的有效实际应用场景非常有限。一些 SISR 工作已经指出图像退化过程中的模糊核的准确性对 SISR 起着至关重要的作用,然而并没有基于 CNN 的相关工作将模糊核等因素考虑在内。为此引出本文主要解决的问题:是否可以设计一个非盲超分辨率(non-blind SISR)模型用以解决不同的图像退化类型?
3.方法
本文首先分析了在最大后验(MAP)框架下的 SISR 方法,借此希望可以指导 CNN 网络结构的设计。由于 SISR 问题的不适定性,通常需要引入正则项来约束解空间。具体来说,LR 图像 y 对应的 HR 图像 x 可以通过求解下述问题近似,
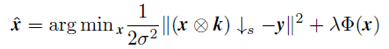
其中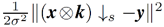
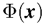
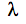
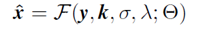
1) 由于数据保真项对应着 SISR 的退化过程,因此退化过程的准确建模对 SISR 的结果起着至关重要的作用。然而现有的基于 CNN 的方法其目标是求解下面的问题,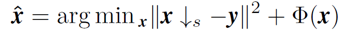
2) 为了设计更加有效的基于 CNN 的 SISR 模型,应该将更多的图像退化类型考虑在内,一个简单的思路就是将模糊核 k 和噪声水平
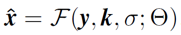
3) 由于 MAP 估计中大部分的参数都对应着图像先验部分,而图像先验是与图像退化过程不相关的,因此单一的 CNN 模型具有处理不同退化类型的建模能力。
通过上述分析可以得出非盲 SISR 应该将退化模型中的模糊核和噪声水平也作为网络的输入。然而 LR 图像、模糊核和噪声水平三者的维度是不同的,因此不能直接作为 CNN 的输入。为此本文提出了一种维度拉伸策略。假设 LR 图像大小为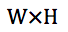
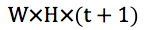
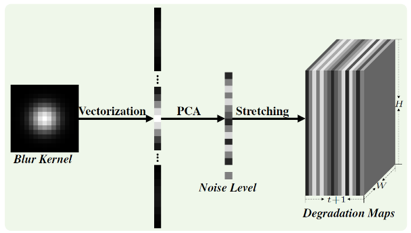
图 1:维度拉伸示意图。
至此,我们可以将退化图和 LR 图像合并在一起作为 CNN 的输入。为了证明此策略的有效性,选取了快速有效的 ESPCN 超分辨网络结构框架。值得注意的是为了加速训练过程的收敛速度,同时考虑到 LR 图像中包含高斯噪声,因此网络中加入了 Batch Normalization 层。
图 2 给出了提出的超分辨率网络(简称 SRMD)结构框架。
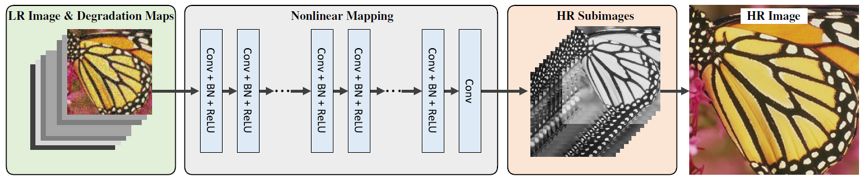
图 2:提出的超分辨率网络结构框架(卷积层数为 12,每层通道数为 128)。
4.实验
在训练阶段,SRMD 采用了各向同性和各向异性的高斯模糊核、噪声水平在 [0, 75] 之间的高斯白噪声以及 bicubic 降采样算子。需要指出的是 SRMD 可以扩展到其它降采样算子,甚至其它退化模型。
在测试阶段,SRMD 比较了不同方法在同为 bicubic 降采样退化下的 PSNR 和 SSIM 结果(如表 1 所示)。可以看出虽然 SRMD 是用来处理各种不同的退化类型,但是仍然在 bicubic 降采样退化下取得不错的效果。需要指出的是 SRMD 在速度上也有很大的优势,在 Titan Xp GPU 上处理 512 × 512 的 LR 图像仅需 0.084 秒,是 VDSR 超分辨率两倍所用时间的一半。表 2 给出了不同退化类型下的 PSNR 和 SSIM 结果比较,可以看到 SRMD 同样取得了不错的效果。图 4 举例说明了 SRMD 可以设定非均匀退化图,进而可以处理退化空间不均匀的 LR 图像。最后,图 5 展示了不同方法在真实图像上的视觉效果比较,可以看到 SRMD 复原的 HR 图像在视觉效果上明显优于其它方法。
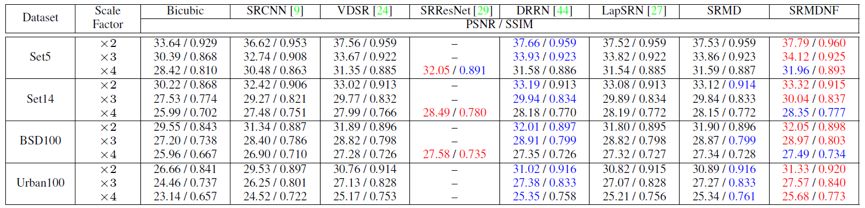
表 1:不同方法在 bicubic 降采样退化下的 PSNR 和 SSIM 结果比较(其中 SRMDNF 表示不考虑噪声情况下训练得到的模型)。

图 3:不同方法在 bicubic 降采样退化下超分辨率四倍的视觉效果比较。
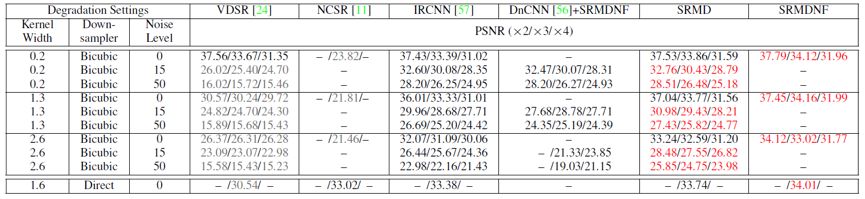
表 2:不同方法在不同退化类型下的 PSNR 和 SSIM 结果比较。
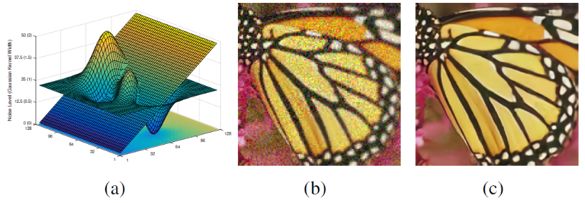
图 4:举例说明 SRMD 可以处理退化空间不均匀的情形。(a)噪声水平以及模糊核宽度的空间分布;(b)LR 图像(最近邻插值放大);(c)复原得到的 HR 图像(放大两倍)。

图 5:不同方法在 SISR 经典测试图像「Chip」上超分辨率四倍的视觉效果比较。
5.结论
最后总结一下,本文的主要贡献有三个方面:
提出了一种简单、有效、可扩展的超分辨率模型,其不仅可以处理 bicubic 降采样退化模型,并且可以处理多个甚至是退化空间不均匀的退化类型,为 SISR 实际应用提供了一种解决方案。
提出了一种简单有效的维度拉伸策略使得卷积神经网络可以处理维度不同的输入,此策略可以扩展到其他应用。
通过实验展示了用合成图像训练得到的超分辨网络模型可以有效的处理真实图像复杂的退化类型。
∑编辑 | Gemini
来源 | 数学与人工智能

算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com


