[深度学习] 我理解的循环神经网络RNN
本来今天在写毕业论文,就不打算更新了,但是写毕业论文挺痛苦的,因为我发现毕业论文的文字不能像公众号这样比较随意,随意的文字不是说不严谨,而是为了便于大家理解,这里就是想吐槽一下,国内写论文的“八股文”现状,反正大家都是一个抄一个的,真的想搞个深度学习模型,把国内的中文论文按照写作风格做个分类,估计最多只能分两类吧,猜猜是那两类?
说到循环神经网络,其实我印象是比较深的,因为循环神经网络是我接触的第一个深度学习模型,大概在一年半前吧,那时候我还没有深度学习的概念,算是刚入门机器学习。偶然一个机会,听某位老师给我说,用RNN来做文本生成,当时我觉得很有意思,并不懂这里面的坑有多大,然后就开始稀里糊涂的查文献。现在才发现,那时候RNN还是挺新的东西,知道的人比较少,大概过了半年左右,研究RNN的人感觉一下多了,但是我当时就做了半个多月,最后基本概念大概懂了,然后找到了一份Keras的代码,因为之前有位老师给了 份Keras做验证码识别的代码,稍微懂一点Keras,(PS:当初搭Keras的这个环境,把我坑惨了,身边也没人懂,也不知道问谁,虽然现在看起来是那么简单,当时也没人给我讲,第一次听说Keras,Theano,Cuda等等,查了各种安装教程,然后从Windows切到了Ubuntu,这也是我第一次接触Ubuntu,装系统的坑也不少,也可能是自己太笨了,反正就是进度很慢很慢,各种问题,不知道大家都是怎么入门的,不过我想说,还好我没放弃~.~,做研究有时间是寂寞的,如果你没有一个好的平台,希望你能守的住寂寞,坚持住自己的梦想)所以把RNN的这个代码最后也算是调通了,但是生成的效果我就不想说了,简直就是火星文,完全不通顺,当时也不懂怎么去改进,就再没做了,然后现在又开始做自然语言处理的东西,想着RNN以后肯定是少不了要了解的,所以最近重新看了一遍相关的内容,今天给大家做个简单的介绍。这里要提醒大家,做这个公众号,只是想减轻信息的不平衡性,就是有些东西可能没人告诉你,你永远接触不到。并不能代替大家学习,当然我也没那么厉害。。。所以真正做研究的话,还是要靠自己多钻研。
做文本生成的RNN,英文名叫RecurrentNeural Networks, 中文名叫循环神经网络。还有一个也叫RNN,英文名叫Recursive Neural Networks,中文名叫递归神经网络。这个两个是有区别的,但是一般说的RNN应该都是指的第一个,这个需要清楚一下,开始的时候,这个也把我坑了一把,没搞清楚是那个。百度上的解释是一个叫时间递归神经网络,一个叫结构递归神经网络,这个解释也说的过去,因为循环神经网络一般就是处理的带有时序性质的数据,也就是存在时间的先后关系。好,今天只说时间递归神经网络,另外一个不做解释。
神经网络大家应该都比较清楚了,一般有输入层,隐藏层,输出层。也就是有一个输入,会给出一个输出,由于中间隐藏层加入了一些非线性的函数,所以神经网络是一个非线性模型。刚才说了RNN主要处理的时序数据,就是存在前后关系的数据,比如说文本,语音,视频等等。什么是前后关系呢,举个栗子,“我爱北京天安门”,当出现“北京”的时候,“天安门”出现的概率就很多,至少比“我爱北京大熊猫”,出现的概率要大。但是也有可能是“我爱北京烤鸭”,是吧,这个就是词语和词语之间的关系,也就是word level,文本也存在词和词之间的联系,就是英文中character level。那么RNN就是试图找到word或者character之间的关系,然后建模,进而做出预测,这就是RNN的用途。
当有了第一个word或者character的时候,可以用RNN去预测下一个词,那么一直预测下去,就是文本生成。文本生成的研究已经很多了,有人用RNN去模仿韩寒写作,也有人用RNN去生成音乐,如果感兴趣,可以去看具体的文献。

然后你去查RNN的资料,肯定有这个图,这个图我最先是15年9月份出来在一个英文博客中看到的,当时博主的第一句话就是RNN非常火,但是资料很少,所以他想写一个系列,来j介绍RNN,听了以后感同身受,资料真的很少,看着英文资料,当时也是挺头疼的。
好,不说废话了,介绍一点干货。
从左到右看一下这个,首先一个输入x,经过U,U应该是weights,到达隐藏层,隐藏层的输出分为2部分,一部分经过V到输出层,另一部分经过W重新输入到隐藏层的神经元当中。这就是所谓的循环,从哪里来然后回到那里去。然后右边是Unfold的样子,注意看的是下标t,这有xt-1, xt,xt+1三个状态,每一个状态的结构是一样的,区别在于代表的时间点不一样,看一下st,这个是介于t-1和t+1时刻的中间状态,他的输入就包括了当前时间t和t-1的隐藏层输出,RNN把这个隐藏层的输出叫做“记忆单元”,就是说这一部分记住了上一个时间的一部分内容,所以叫“记忆单元”。

f就是常用的激活函数,比如tanh,relu,leaky-relu等等。
输出层就和普通的神经网络一样了
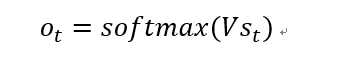
这里可以思考一下,既然t-1时刻的“记忆单元”可以记住t-1时刻的内容,那么因为t的取值是无限的,所以每个时刻都可以保留前面所有时刻的内容,理论上是这样的,但是实际情况是RNN并没有那么强大,他可能只能记住前面2,3个时刻的内容,过一会儿它就“忘记了”距离比较远的信息(所以后来才有了LSTM)。
然后再看两个图

这个是双向的RNN,就是除了前一个时刻传递到当前时刻的“记忆单元”,还有当前时刻传回去的“记忆”。

这个是深度双向RNN,这里的隐藏层是三层,其实我想这个应该就和深度卷积神经网络一样了吧,你想加多少层都可以。在Keras里面,这个都有实现。
好,到这里RNN的概念就算基本完了,剩下的就是RNN的学习方法和应用场景。RNN的训练算法是BPTT(Backpropagation through time),基本原理和BP算法差不多的,只是这个这个用来训练RNN隐藏层的方法。RNN存在的问题的梯度消失和梯度爆炸,简单说一下解决办法,主要是我这方面没有实际经验,不敢多说。。对于梯度爆炸,爆炸的意思其实就是梯度太大了,那么我们就给他设个范围,超过这个范围的就不要了,就不会爆炸了。对于梯度消失,比梯度爆炸要难处理一些,因为梯度消失不好检测,但是方法也是有的,可以通过初始化方法,激活函数和使用类似LSTM或者GRU之类的循环神经网络。RNN的应用场景包括文本生成,机器翻译,图像打标签,语音识别等。不管是那个方向,文献都很多的,想做这方面,只要选择一个方向,都够做好久的了。。





