使用 TensorFlow-Agents Bandits 库开展推荐活动


发布人:Google Research 的 Gábor Bartók 和 Efi Kokiopoulou
本文默认您在强化学习和/或 Multi-Armed Bandits 方面有一定的经验。如果您对这个主题不甚了解,最好从维基百科条目:Bandits 开始了解,或者阅读此书,更深入了解技术方面的介绍。
此书
https://arxiv.org/abs/1904.07272
在本文中,我们介绍了 TensorFlow-Agents Bandits 库。这个库提供了热门博弈算法,以及可供各种算法运行的测试问题。这些测试问题(称为博弈环境)包括一些合成环境以及从现实生活(分类或推荐)数据集转换而来的环境。
TensorFlow-Agents
https://github.com/tensorflow/agents
Bandits 库
https://github.com/tensorflow/agents/tree/master/tf_agents/bandits
MovieLens 环境就是利用了这个数据集的转换环境之一。在本文中,我们将指导您在 MovieLens 环境的帮助下使用 TF-Agents Bandits 库。


Multi-Armed Bandits 是一个机器学习框架,智能体 (Agents) 会从一组操作中反复选择操作,并通过与环境互动来收集奖励。智能体的目标是在给定的时间范围内,尽可能多地积累奖励。“Bandits”这个名字取自说明性示例,即从一组具有不同回报的机器中找到回报最丰富的机器 (one-armed bandit)。这些操作也被称为“臂 (arms)”。

图源:维基百科 (Las Vegas slot machines.jpg)
有两个更重要的概念需要加以注意,即“上下文背景”和“遗憾”。在许多现实生活场景中,仅仅找到平均情况下能提供最高奖励的最佳操作是不够的:我们要根据情况/背景找到最佳操作。为了在这个方向上扩展该框架,我们引入了“背景”的概念。在智能体必须选择操作之前,它会收到提供当前轮次信息的背景。然后,智能体的目标是找到一个策略,在给定背景下选择回报最高的操作。
在相关文献资料中,“遗憾”这个概念非常重要。遗憾的非正式定义是最优策略和所学策略之间的性能差异。通常情况下,性能是以累积奖励(即几轮奖励的总和)来衡量的;另外,也可以参考“瞬时遗憾”,即智能体在某一轮所遭受的遗憾。博弈算法通常有性能保证,即在给定的博弈问题系列中,存在遗憾上限。
想象以下场景。您的任务是向电影在线媒体服务的用户推荐电影。您会在每一轮中收到关于用户的信息。您的任务是从几部电影中为用户做出选择,而目标是选择一部用户会喜欢并给予高分评价的电影。
1. 推荐数据集
为了进行说明,我们会把著名的 MovieLens 数据集变成一个博弈问题。该数据集包含来自 943 个用户对 1682 部电影的大约 10 万个评分。把这个数据集变成一个结合背景的博弈问题,我们首先要构建用户/电影评分的矩阵“A”,其中“A_ij”是用户“i”对电影“j”的评分。由于我们只有每个用户对几部电影的评分,所以评分矩阵“A”存在一个问题,它非常稀疏,即只有几个条目“A_ij”可用;所有其他条目都是未知的。为了解决这个稀疏问题,我们构建了一个低秩 SVD 分解“A ~= U*V'”(推荐系统中的低秩矩阵分解是协作过滤的热门方法之一,具体可参阅 Koren et al. 2009)。这样一来,“U”行就是背景特征。然后,要推荐给用户的电影是操作集合,用“V”行表示。向用户“i”推荐电影“j”的奖励可以计算为“U_i”和“V_j”相应行的内积。因此,通过使用低秩 SVD 分解来计算奖励,我们可以近似计算奖励,即使是那些没有推荐给用户的电影也囊括在列;所以,它们的评分是未知的。
Koren et al. 2009
https://datajobs.com/data-science-repo/Recommender-Systems-%5BNetflix%5D.pdf
2. TF-Agents 博弈
现在让我们看看上述问题在 TF-Agents Bandits 库的帮助下得到建模和解决的过程。TF-Agents 是一个模块化的库,其中包含强化学习和博弈各个方面的构建模块。问题可以用“环境”的形式来表达。环境是一个生成观察结果(又称背景)的类,并会在系统实施操作后输出奖励。在 MovieLens 环境中,观察结果是矩阵“U”的随机行,而系统会在算法选择操作(即矩阵“V”的行,在我们的示例中是一部电影)后给出奖励。有关 MovieLens 环境的实现,请参见此处。这里值得注意的是,在 TF-Agents 中实现博弈环境相当简单。有关演示,请读者参阅我们的博弈教程。
TF-Agents
https://github.com/tensorflow/agents/tree/master/tf_agents
此处
https://github.com/tensorflow/agents/blob/master/tf_agents/bandits/environments/movielens_py_environment.py
教程
http://tensorflow.google.cn/agents/tutorials/bandits_tutorial
3. 算法
TF-Agents 中的博弈算法有两个主要的构建模块:“策略”和“智能体”。策略是一个函数,会在给定观察结果的条件下选择操作。智能体负责学习出色策略:在给定(观察结果、操作、奖励)元组示例的条件下训练策略,以便选择更好的操作。TF-Agents Bandits 库提供了大热算法的详细列表,其中包括线性方法以及非线性方法(例如,那些基于神经网络的价值函数)。让我们看看 LinUCB 会如何解决 MovieLens 问题!
4. LinUCB 算法
简而言之,LinUCB 算法会跟踪所有操作的运行平均奖励,以及估计值周围的置信区间。在每一轮中,该算法都会选择对其奖励估计值具有最高置信度上限的操作。
LinUCB 算法
https://arxiv.org/abs/1003.0146
在 TF-Agents 库中,LinUCB 算法是由具有“乐观探索策略”的 LinearBanditPolicy 和负责更新估计值的 LinearBanditAgent 构建而成。请注意,探索策略可以从“乐观”改为“采样”,在这种情况下,算法变成了线性汤普森采样。
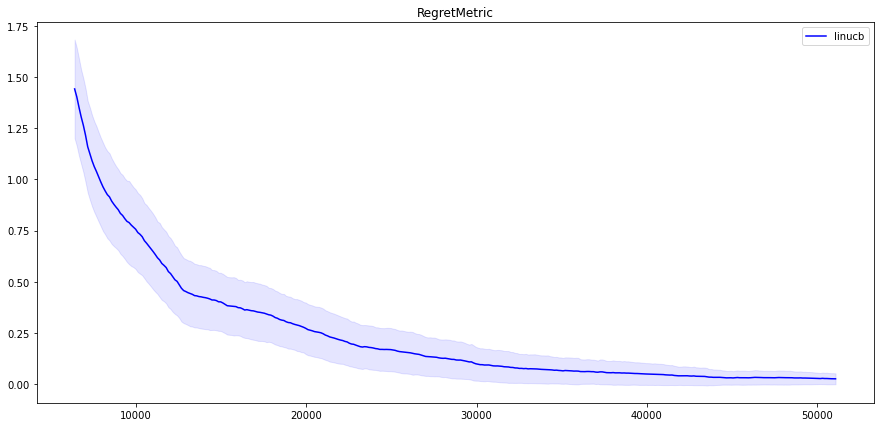
那么,让我们看看 LinUCB 在 MovieLens 环境中的表现吧!我们在 MovieLens 环境中运行了 LinUCB(其中有 100 个操作,且 SVD 分解排名为 20),并在 TensorBoard 上得到了结果:
(注意,以下所有图表都是基于五次运行的平均值,阴影显示的是标准偏差。曲线还应用了滚动平均值平滑法。)
5. 线性汤普森采样
如上所述,通过对 LinUCB 稍加修改,我们就实现了线性汤普森采样 (LinTS)。如果我们针对同一个问题运行 LinTS(参见此处,了解实施情况),我们得到与 LinUCB 非常相似的结果(见下文的联合图)。
此处
https://github.com/tensorflow/agents/blob/master/tf_agents/bandits/agents/linear_thompson_sampling_agent.py
6. NeuralEpsilonGreedy
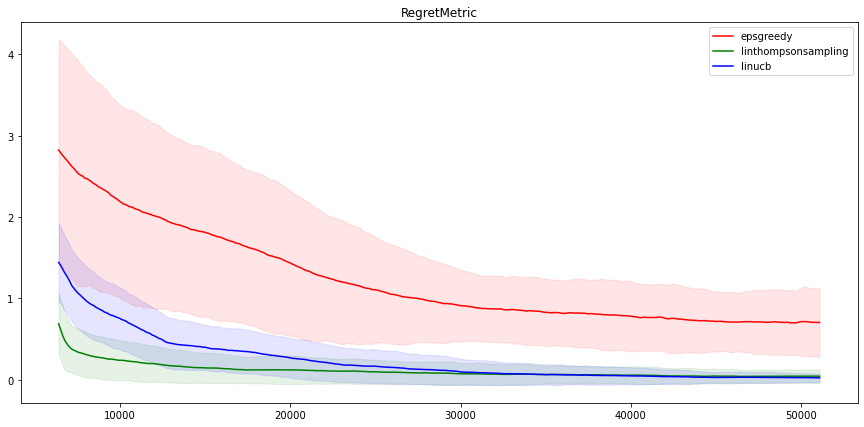
我们把这些结果与另一个智慧体进行比较,例如,NeuralEpsilonGreedy 智能体。顾名思义,这个智能体使用神经网络来估计奖励,并增加了概率为“epsilon”的统一探索。这种探索策略被称为“epsilon-greedy”,因为该方法在大多数时候都比较“贪心”,但在概率为“epsilon”的情况下,它会随机地统一挑选一个操作,以此进行探索。如果我们运行 Neural Epsilon Greedy,并把三种算法的结果放在一起,我们会得到:
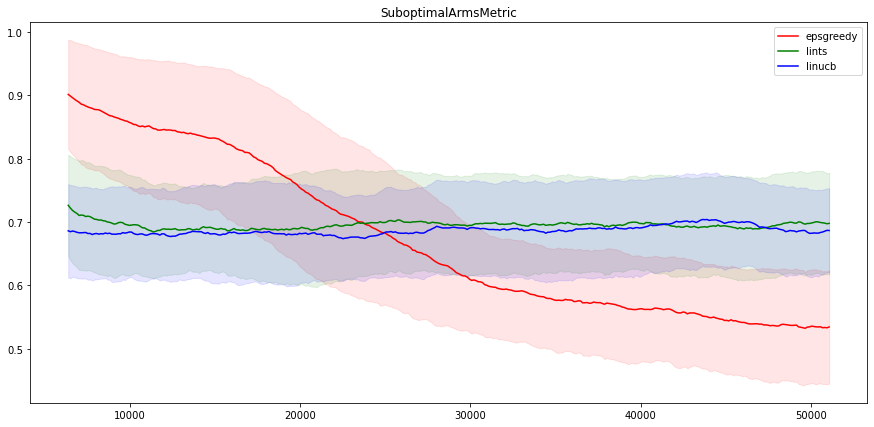
有趣的是,我们还可以看到这些方法选择次优操作的频率如何。结果如下所示:
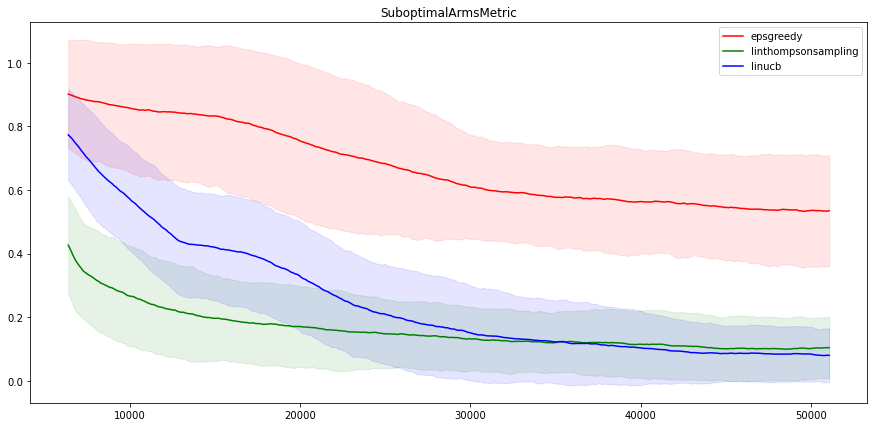
不出意料,LinUCB 和 LinTS 的性能非常相似,因为它们是非常相似的算法。另一方面,Neural epsilon-Greedy 在这个问题上表现得不是很好。经过五万次的迭代,其指标仍然与线性方法的指标相差甚远。不过,请注意,即使是 epsilon-Greedy 算法,找到最好电影的概率也达到了百分之五十(在 100 次操作中),性能还是不错的!
平心而论,在这个问题上,线性算法的性能优于非线性算法是意料之中的,因为就奖励计算结构而言,这个问题是线性的。
至于两个线性算法之间的差异,LinUCB 在开始时似乎有点不太顺利,但从长远来看,它要稍稍优于 LinTS(差距并不明显)。
上述 MovieLens 示例存在一些缺点:其操作是选择电影,算法必须为每部电影学习独特的模型,而且难以在系统中引入新电影。为此,我们对环境稍加修改:不把每部电影当作一个独立的操作,而是利用特征对电影进行建模,就像用户一样,使用“V”行代表电影特征。然后模型只需要学习一个奖励函数即可,其输入是用户特征“u”和电影特征“v”。这样,我们的系统就可以接受不限数量的电影,而且可以实时引入新的电影。点击这里,了解此版本环境的相关详情。
这里
https://github.com/tensorflow/agents/blob/master/tf_agents/bandits/environments/movielens_per_arm_py_environment.py
1. 在每臂特征环境中运行的智能体
在我们库中实现的大多数智能体都具有这样一种功能,可以在具有其操作特征的环境中运行(我们称这些环境为“每臂环境”)。
现在让我们看看不同的算法在 MovieLens 环境的每臂版本中表现如何。我们运行了三种算法的臂特征版本:LinUCB、LinTS 和 eps-Greedy。结果与上一节所述完全不同:在这种版本中,线性方法似乎无法找到操作和奖励之间的关系,而神经方法得出的结果则与非臂特征问题的结果类似。
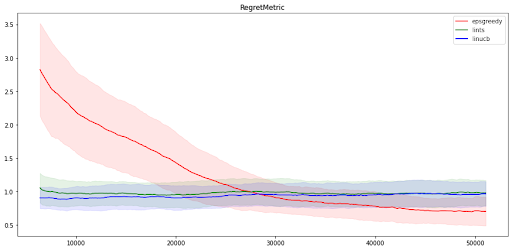
神经算法找到最佳操作的概率仍有约 45%,而线性算法只有约 30%。
2. 新博弈算法
如果您在库内的智能体列表中没有找到合适的算法,则可以实现您自己的算法,但这并不复杂。您需要:
子类
tf_agents.policies.TFPolic和子类
tf_agents.agents.TFAgent。
3. TFPolicy
要定义一个策略,需要实现其私有成员函数 _distribution(...)。简而言之,这个函数会接收观察结果并输出操作分布情况(或者在具有确定性策略的情况下只输出一个操作)。
4. TFAgent
如上所述,智能体会负责训练策略。为此,TF 智能体的子类 TFAgent (sorry) 必须实现私有成员函数 _train()(除此之外,为了清晰起见,还省略了一些细节)。这个函数会接收成批的训练数据,并训练策略。
5. 新博弈环境
如果您想测试(新)算法,并且有关于环境的想法,也可轻松地在 TF-Agents 中加以实现。博弈环境有两个主要作用:(i) 生成观察结果,以及 (ii) 在智能体选择操作后返回奖励。通过定义这两个功能,可以很容易地创建环境类。
在本文中,我们介绍了 TF-Agents Bandits 库,并展示了借此如何解决推荐问题。如果您想了解一下本篇文章中使用的环境和智能体,则可以直接使用这个可执行文件来运行这些智能体及更多内容。如果您想探索这个库或者只是想阅读更多相关信息,我们建议从这个教程开始。如果您有兴趣学习利用 MovieLens 数据集进行推荐的更多相关知识,您也可以查看另一个具有出色效果的库,其名为 TensorFlow Recommenders。
这个可执行文件
https://github.com/tensorflow/agents/blob/master/tf_agents/bandits/agents/examples/v2/train_eval_movielens.py
教程
http://tensorflow.google.cn/agents/tutorials/bandits_tutorial
TF-Agents Bandits 库由 Jesse Berent、Tzu-Kuo Huang、Kishavan Bhola、Sergio Guadarrama、Anoop Korattikara、Oscar Ramirez、Eugene Brevdo,以及 TF-Agents 团队的许多其他成员共同构建而成。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看



