TensorFlow 模型优化工具包:协作优化 API


发布人:Arm 的 Mohamed Nour Abouelseoud 和 Elena Zhelezina
本文介绍了用于边缘设备中机器学习模型优化的协作技术(由 Arm 公司提出并贡献给 TensorFlow 模型优化工具包),自 v0.7.0 版本起可用。
模型优化工具包
https://tensorflow.google.cn/model_optimization
v0.7.0
https://github.com/tensorflow/model-optimization/releases/tag/v0.7.0
协作优化流水线的主要理念是逐个应用 TensorFlow 模型优化工具包中不同的优化技术,同时在部署所需的压缩和准确率之间保持平衡。这会使模型大小显著减小,并且可以在特定的框架和硬件支持下提高推理速度,如 Arm Ethos-N 和 Ethos-U NPU 提供的支持。
Ethos-N
https://developer.arm.com/ip-products/processors/machine-learning/arm-ethos-n
Ethos-U
https://developer.arm.com/ip-products/processors/machine-learning/ethos-u55
这是工具包路线图的一部分,用于支持开发更小更快的 ML 模型。您可以查看先前关于训练后量化、量化感知训练、稀疏性和聚类的文章,进一步了解工具包的背景和功能。
工具包路线图
https://tensorflow.google.cn/model_optimization/guide/roadmap

一般来说,协作优化背后的发展动力与模型优化工具包 (TFMOT) 背后的发展动力是相同的,即实现模型的调节和压缩,以改善对边缘设备的部署。对边缘计算和面向端点 AI 的推进,促成了对此类工具和技术的较高需求。协作优化 API 叠放了所有可用的模型优化技术,以利用其累积效应,在实现最佳模型压缩的同时保持所需的准确率。
面向端点 AI
https://community.arm.com/iot/b/internet-of-things/posts/endpoint-ai-the-road-to-a-trillion-intelligent-endpoints
以下是我们现有的优化技术,可将其组合为各种部署组合:
训练后量化
量化感知训练 (QAT)
换言之,我们可以在部署前应用剪枝和聚类中的一种或两种技术,然后再进行训练后量化或 QAT。
要将这些技术结合起来,其挑战性在于 API 不考虑之前的技术,每个优化和微调流程都不会保留前一项技术的结果。这破坏了同时应用这些技术的整体效益;即聚类不能保留剪枝流程引入的稀疏性,而 QAT 的微调流程无法保留剪枝和聚类的优势。为了克服这些问题,我们提出了以下协作优化技术:
保留稀疏性的聚类:确保零集群的聚类 API,可保留模型的稀疏性。
保留稀疏性的聚类
https://tensorflow.google.cn/model_optimization/guide/combine/sparse_clustering_example
保留稀疏性的量化感知训练 (PQAT):保留模型稀疏性的 QAT 训练 API。
保留稀疏性的量化感知训练
https://tensorflow.google.cn/model_optimization/guide/combine/pqat_example
保留集群的量化感知训练 (CQAT):能够进行重新聚类并保留相同数量质心的 QAT 训练 API。
保留集群的量化感知训练
https://tensorflow.google.cn/model_optimization/guide/combine/cqat_example
保留稀疏性和集群的量化感知训练 (PCQAT):QAT 训练 API 保留了用保稀聚类法训练的模型的稀疏度和集群数。
保留稀疏性和集群的量化感知训练
https://tensorflow.google.cn/model_optimization/guide/combine/pcqat_example
综合考虑,再加上选择了训练后量化而不是 QAT,这些都为部署提供了几条路径,如下方部署树所示,叶子节点是准备部署的模型,表示这些模型已完全量化并采用 TFLite 格式。绿色方块表示需要重新训练/微调的步骤,红色虚线边框突出显示了协作优化的步骤。在给定节点上用于获取模型的技术将用相应的标签表示。
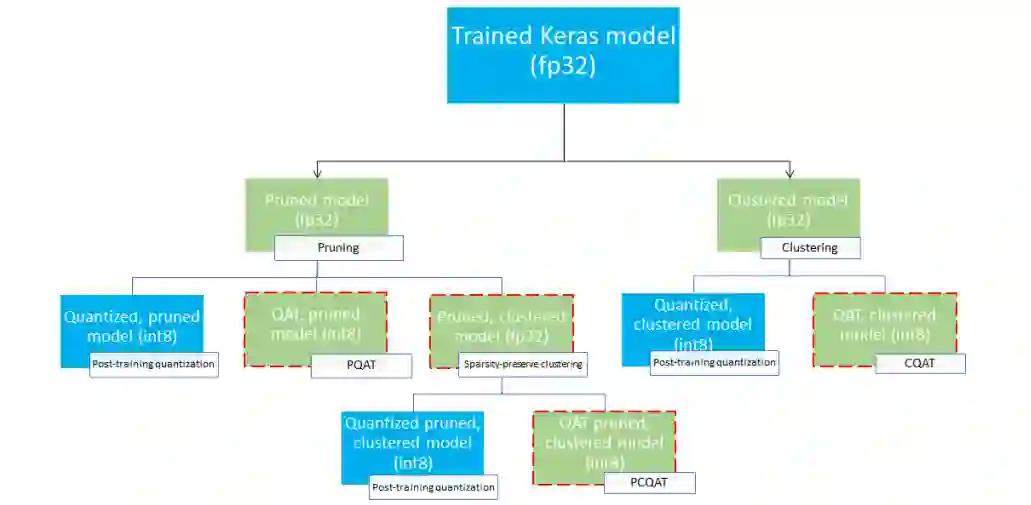
上图省略了只进行量化(训练后或 QAT)的直接部署路径
我们的思路是在上述部署树的第三层实现完全优化的模型;然而,其他任何层的优化都有可能产生令人满意的效果,并达到所需的推理延迟、压缩和准确率目标,在这种情况下,不需要进一步优化。建议的训练过程是迭代遍历适用于目标部署场景的部署树的各个层级,查看模型是否满足优化要求,如不满足,则使用相应的协作优化技术进一步压缩模型,如果需要的话,重复进行这一操作,直到模型完全优化(剪枝、聚类和量化)。
为了进一步改进协作优化相关推理时的内存使用量和速度,需要专用的运行时或编译器软件以及专用的机器学习硬件。以 Ethos-N 处理器的 Arm ML Ethos-N 驱动栈和 Ethos-U 处理器的 Ethos-U Vela 编译器为例。目前,这两个示例都需要先将优化的 Keras 模型量化并转换到 TensorFlow Lite。
Ethos-N 处理器
https://developer.arm.com/ip-products/processors/machine-learning/arm-ethos-n
Arm ML Ethos-N
https://github.com/ARM-software/ethos-n-driver-stack
Ethos-U
https://developer.arm.com/ip-products/processors/machine-learning/arm-ethos-u/ethos-u55
Ethos-U Vela
https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u-vela
下图为一个样本权重内核的密度图,该内核经历了整个协作优化流水线。
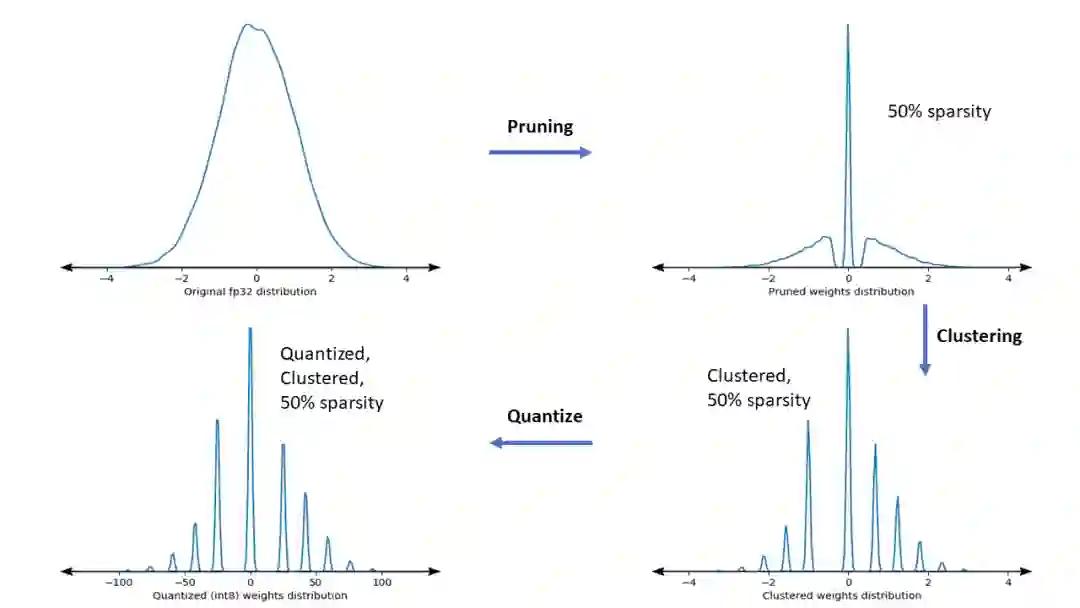
其结果将得到量化部署模型,该模型具有较少的唯一值以及大量的稀疏权重(取决于在训练时指定的目标稀疏度)。这提供了很大的模型压缩优势,并大大减少了专用硬件上的推理延迟。
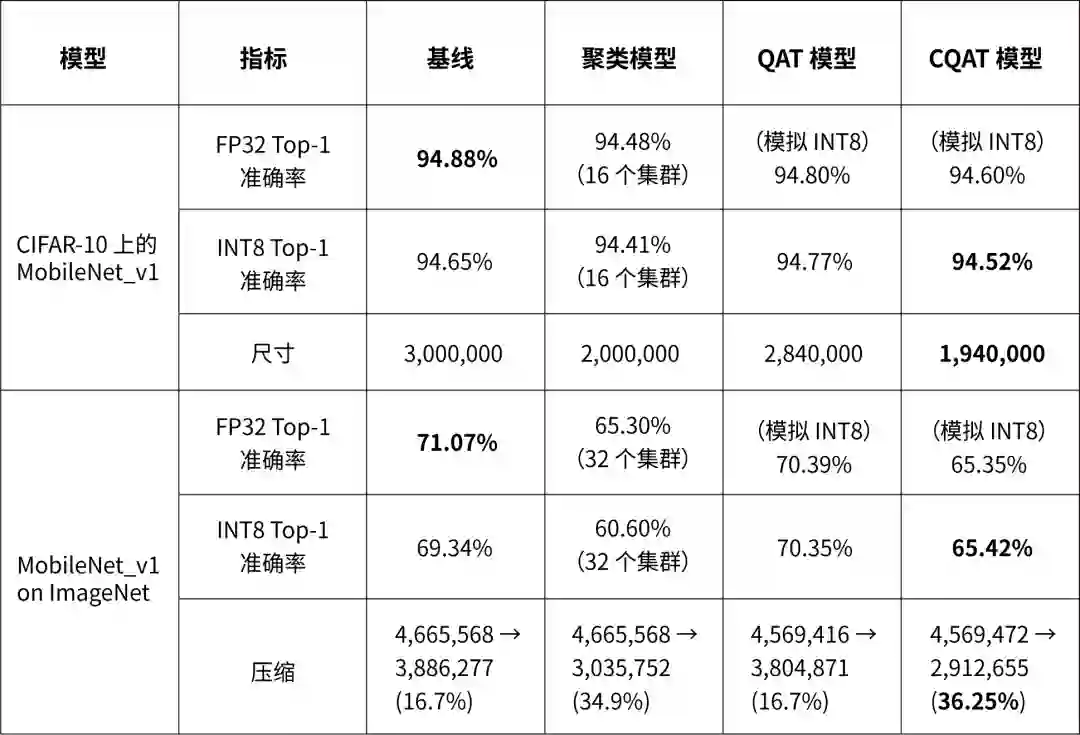
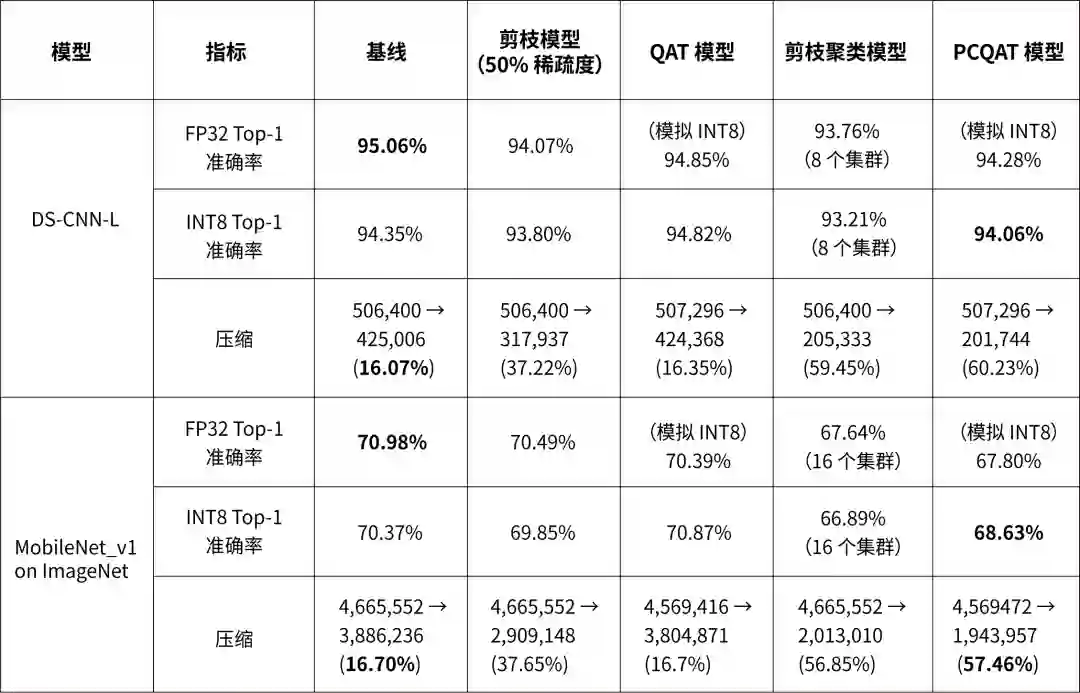
以下表格显示了在主流模型上进行的几个实验结果,展示了应用这些技术所带来的压缩优势与准确率损失。还可以应用更主动的优化,但会牺牲准确率。虽然下表包含 TensorFlow Lite 模型的测量结果,但对于其他序列化格式也观察到了类似的优势。
保留稀疏性的量化感知训练 (PQAT)
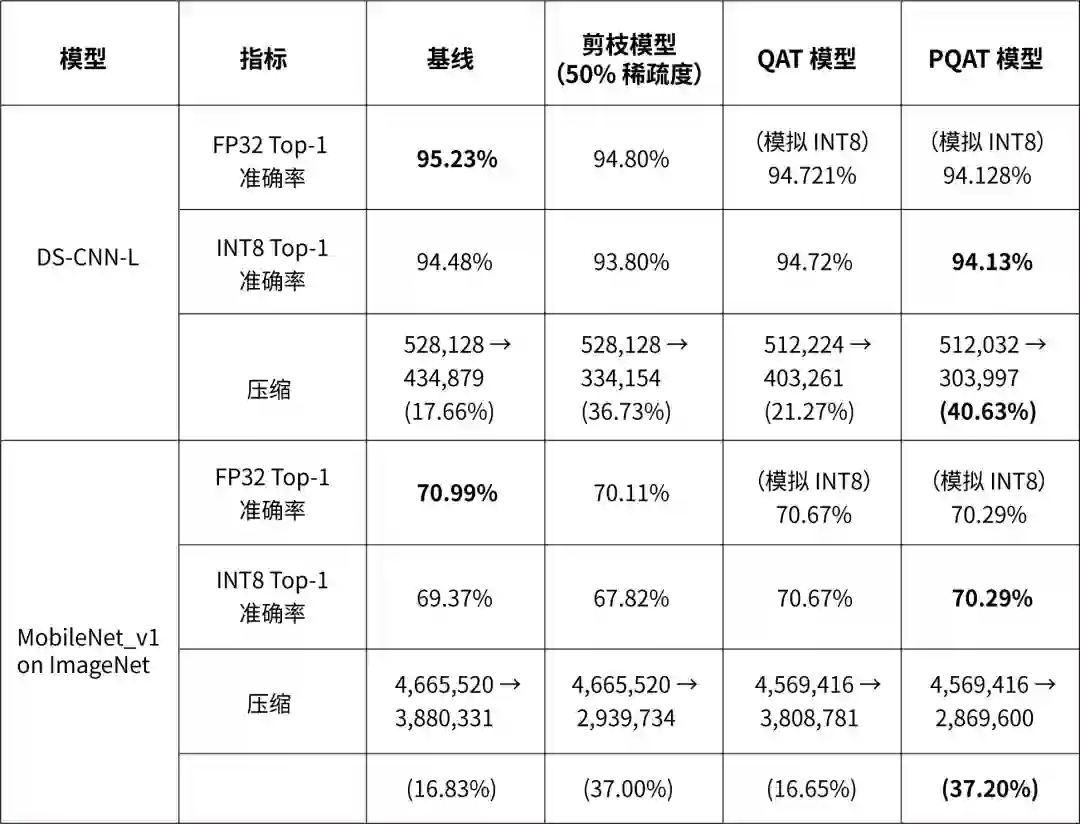
请注意:DS-CNN-L 是为边缘设备设计的关键字发现模型。详情请参见 Arm 的 ML 示例代码库。
ML 示例
https://github.com/ARM-software/ML-examples/tree/master/tflu-kws-cortex-m
保留集群的量化感知训练 (CQAT)
保留稀疏性和集群的量化感知训练 (PCQAT)
要应用 PCQAT,需要首先使用剪枝 API 来对模型进行剪枝,然后使用保稀聚类 API 将其与聚类联系起来。之后,在自定义协作优化量化方案中使用 QAT API。请参看以下示例。
import tensorflow_model_optimization as tfmot
model = build_your_model()
# prune model
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, ...)
model_for_pruning.fit(...)
# pruning wrappers must be stripped before clustering
stripped_pruned_model = tfmot.sparsity.keras.strip_pruning(pruned_model)将剪枝后的模型按以下方式进行聚类和拟合。
# Sparsity preserving clustering
from tensorflow_model_optimization.python.core.clustering.keras.experimental import (cluster)
# Specify your clustering parameters along
# with the `preserve_sparsity` flag
clustering_params = {
...,
'preserve_sparsity': True
}
# Cluster and fine-tune as usual
cluster_weights = cluster.cluster_weights
sparsity_clustered_model = cluster_weights(stripped_pruned_model_copy, **clustering_params)
sparsity_clustered_model.compile(...)
sparsity_clustered_model.fit(...)
# Strip clustering wrappers before the PCQAT step
stripped_sparsity_clustered_model = tfmot.clustering.keras.strip_clustering(sparsity_clustered_model)然后应用 PCQAT。
pcqat_annotate_model = quantize.quantize_annotate_model(stripped_sparsity_clustered_model )
pcqat_model = quantize.quantize_apply(quant_aware_annotate_model,scheme=default_8bit_cluster_preserve_quantize_scheme.Default8BitClusterPreserveQuantizeScheme(preserve_sparsity=True))
pcqat_model.compile(...)
pcqat_model.fit(...)以上示例展示了实现完全优化的 PCQAT 模型的训练流程,关于其他技术,请参考 CQAT、PQAT 和保稀聚类的示例笔记。请注意,PCQAT 和 CQAT 使用的 API 相同,唯一的区别是 PCQAT 使用了 preserve_sparsity 标志,以确保在训练流程中保留零集群。PQAT API 的用法类似,但使用了保留稀疏性的不同量化方案。
CQAT
https://www.tensorflow.google.cn/model_optimization/guide/combine/cqat_example
PQAT
https://www.tensorflow.google.cn/model_optimization/guide/combine/pqat_example
保稀聚类
https://www.tensorflow.google.cn/model_optimization/guide/combine/sparse_clustering_example
本篇文章中介绍的特征和结果是许多人合作的成果,包括 Arm ML Tooling 团队和我们在 Google TensorFlow 模型优化工具包团队的协作者。
Arm 成员:Anton Kachatkou、Aron Virginas-Tar、Ruomei Yan、Saoirse Stewart、Peng Sun、Elena Zhelezina、Gergely Nagy、Les Bell、Matteo Martincigh、Benjamin Klimczak、Thibaut Goetghebuer-Planchon、Tamás Nyíri、Johan Gras。
Google 成员:David Rim、Frederic Rechtenstein、Alan Chiao、Pulkit Bhuwalka

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看



