社区分享 | 在物联网设备中运行 TensorFlow


发布人:王玉成,ML/IoT GDE,现就职于涂鸦智能


随着物联网与 AI 技术的不断发展,在物联网的设备上用 AI 技术处理数据成为了必然。
Google 关于 AI 的框架 TensorFlow 近几年来,也逐渐演化出来一个新的分支,嵌入式系统与机器学习。经过 TensorFlow Lite 的发展,在低功耗的微处理器领域,又形成了另外一个解决方案,即 TensroFlow Lite Micro(以下简称 TFLM),主要用于碎片化领域相当严重的嵌入式领域,针对跨平台操作的通用性,以及资源限制的场景。
首先拉出 Google 在 AI 中的产品时间线。
●
2011 年,Google 在内部孵化出 DistBelief 项目,为深度学习网络构造出的一个深度学习系统,用于 Google 的许多内部产品中,从这一年开始,有相当多的技术相关的论文发表出来。
●
2015 年 11 月,推出了 TensorFlow 0.1 版本。
●
2017 年 2 月,推出 TensorFlow 1.0 版本。
●
2018 年 5 月,推出 TensorFlow Lite。
●
2019 年 5 月,推出 TensorFlow Lite Micro。
从时间线可以看出,TFLM 应该是 TensorFlow 的亲孙子,极好的继承了 TensorFlow 与 TensorFlow Lite 的衣钵。
如果说 TensorFlow Lite 是为移动端,嵌入式设备开发的机器学习推理框架,那么 TFLM 是 TensorFlow Lite 的子集,主要应用场景在 DSP, 微处理器和其它一些内存受限的设备上。也就是说 TensorFlow Lite (Micro) 全方位覆盖了物联网的的网关,端点设备。那我们有必要去理一理这些硬件对 TensorFlow 的支持情况如何?Google 自家的产品及发方案包括但不限于 Edge TPU,Coral, 以及 TFLM 包含哪些功能,如何去使用呢?
支持 TensorFlow Lite 运行的硬件包括 CPU、 GPU、 DSP 等,Google 自主研发的硬件解决方案为 Edge TPU 和 Coral,它们采用同样的芯片。
1. Edge TPU
官网地址:
https://cloud.google.com/edge-tpu
Edge TUP 为 Google 专门设计的一款的 ASIC, 旨在运行边缘端的推理。
那么 Edge TPU 有哪些功能呢?
●
端到端的 AI 基础架构,协助客户部署端侧的 AI 解决方案。
●
体型小,功耗低,但是性能出色。
●
将硬件,软件,AI 算法结合在一起的解决方案。
●
众多工业使用场景。
Edge TPU 是端侧的 AI 解决方案。Edge TPU 对 CPU、GPU、FPGA 以及其他在边缘运行 AI 的 ASIC 解决方案构成了有益的补充。
由于现有物联网的解决方案,通常有云管端的叫法,那么在 AI 方案中,云侧与端侧又提供了哪些基础设施呢。
|
|
Edge(设备/节点/网关/服务) |
Cloud |
|
任务 |
ML 推理 |
ML 的训练及推理 |
|
软件与服务 |
Linux, Windows |
AI 平台, Kubernetes 引擎,计算引擎,Cloud IoT Core |
|
ML 框架 |
TensorFlow Lite, NN API |
TensorFlow, scikit-learn, XGBoost, Keras |
|
硬件加速器 |
Edge TPU, GPU, CPU |
Cloud TPU, GPU, 以及 CPU |
我们这时候再来理解 Edge TPU,在整个云管端解决方案中 Edge TPU 可以理解为 AI 在端侧的硬件资源。如果要用 Google 的硬件资源完成 AI 的整个解决方案。我们需要用 TensorFlow 的框架,在 Google Cloud(可以利用Cloud TPU)去做 ML 的训练,然后再将模型部署到 Edge TPU 进行 AI 推理。
Edge TPU 的硬件性能如下:用于加速 AI 推理的专用芯片,以 8 位整理的格式运算,硬件接口支持 PCIE 和 USB。
如果说 Edge TPU 是 AI 端解决方案的原型,那么这个原型能承载的实际的物理设备便是 Coral。
2. Coral
官网地址:
https://coral.ai/
Coral 是一个完整的工具包,可以使用本地 AI 构建产品。它的设备端推理功能能够方便的构建高效、私密、快速和离线的产品。所有的硬件都完全支持 TensorFlow Lite 框架。
首先来一张 Coral 的全家福

device
1. Coral 的 USB 加速器,可以做为 Windows,Linux 和 Macos 的配件来使用,支持 TensorFlow Lite 推理。
2. Coral 开发板:支持的操作系统为 Mendel Linux(Debian 的衍生版本)。
3. System-on-Module (SoM),可以理解为核心板。
4. 基于 Mini PCIE 接口的加速器,仅支持主机为 Debian Linux 系统。
5. 基于 M.2 的 A+E Key 加速器。
6. 基于 M.2 的 B+M Key 加速器。
7. 支持 Edge TPU 的芯片模块。
8. 支持双 Edge TPU 的 E Key 的加速器。
9. Coral 开发板,即 2 号板的迷你版。
其中 M.2 的这几种 Key 仅仅只是插槽的不同
●
A 支持 PCIE (x2) 和 USB 接口
●
E 支持 PCIE (x2) 和 USB 接口
●
B 支持 SATA 接口
●
M 支持 PCIE (x2/4) 接口
A+E 表示 A 和 E 都支持。这些信息有些绕,大概知道是 PCIE 和 USB 两种接口都支持就差不多了。
需要提注意的是,Edge TPU 在各种硬件原型中,最主要是功能是 AI 协处理器 (Co-processor),可以以配件的形式与 PC 机等搭配使用,也可以自成一体,以开发板的形式提供独立的硬件支持。
利用 Edge TPU 方案生成的的第三方产品为华硕的两款产品:
●
ASUS AI Accelerator PCIe Card, 以 PCIe 加速卡的形式提供 Edge TPU 支持,最高支持 8 个 Coral M.2 加速卡。
●
ASUS Tinker Edge T:以开发板的形式提供 Edg TPU 支持,基于 Coral SoM 板进行扩展。
Coral 硬件支持的算子如下:
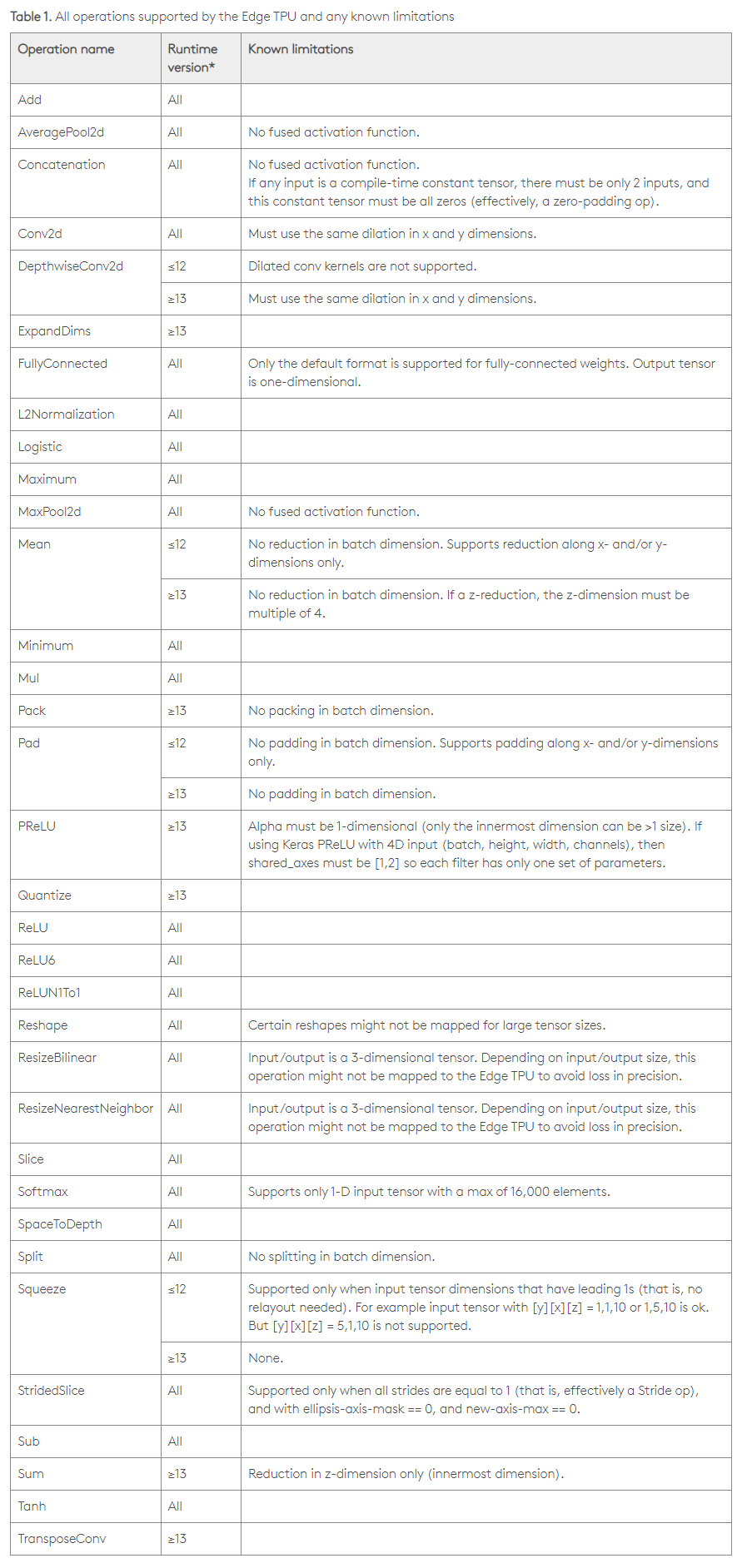
coral operation
TensorFlow Lite 模型的整个编译流程如下:
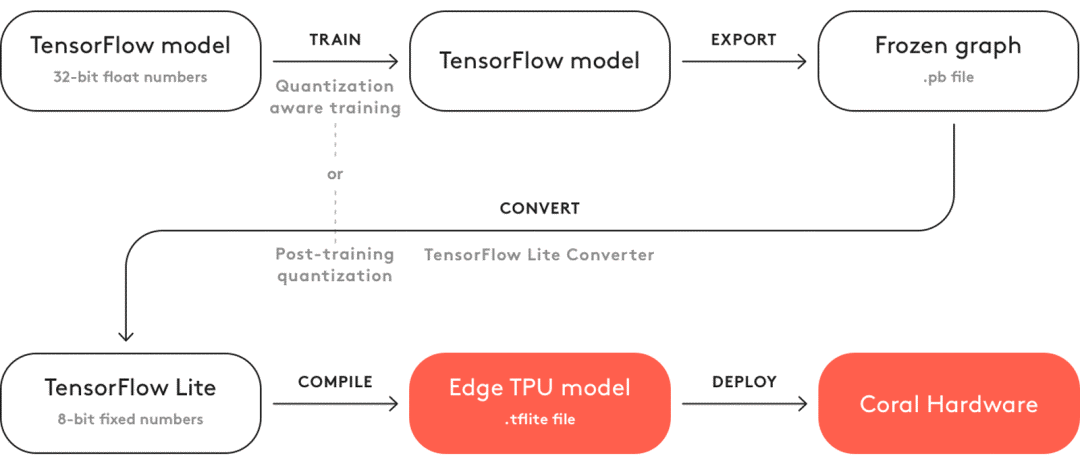
编译流程
从 TensorFlow 模型到 TensorFlow Lite 模型转化的过程中,也伴随着各种优化的过程。
1. 特性
●
缩短延迟:数据无需往返服务器
●
保护隐私:任何数据都不会离开设备
●
减少连接/降低功耗:不需要互联网连接
2. 优化方向
●
针对设备端机器学习进行了解释器的调整,对设备端的一组核心操作符进行了优化,生成较小的二进制。所支持的算子详见:
http://tensorflow.google.cn/mlir/tfl_ops
●
支持多种平台(涵盖 Android 和 iOS 设备、嵌入式 Linux 和微控制器),并利用平台 API 执行加速推断。
●
提供多种语言的 API,包括 Java、Swift、Objective-C、C++和 Python。
●
高性能,在支持的设备上执行硬件加速,其中对内核,以及激活函数都做了硬件层面的优化。
●
模型优化工具(包括量化),可在不影响准确率的情况下减小模型并提高其性能。
●
高效的模型格式,在大小和可移植性方面优化了 FlatBuffer。
优化方向涉及到了解释器,转换器以及量化的一些新名词。我们先看看模型编译的各个阶段所做的工作:
3. 转换器
完成 TensorFlow 模型到 TensorFlow Lite 模型的转换过程。
TensorFlow Lite 转换器执行流程如下:
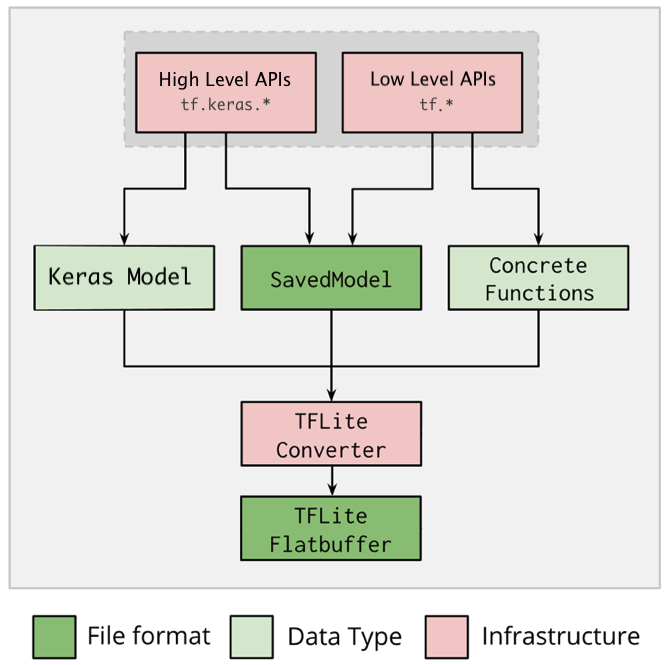
转换器
有两种方式可以完成转换的过程:
●
Python API(推荐):可以更轻松地在模型开发流水线中转换模型、应用优化、添加元数据 (metadata)。
●
命令行:仅支持基本模型转换。
代码转换:
SavedModel 转成 TensorFlow Lite 的代码如下:
# (输入参数为SavedModel的路径)
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
tflite_model = converter.convert()
# (生成tflite模型文件)
with open('model.tflite', 'wb') as f:
f.write(tflite_model)Keras 模型转成 TensorFlow Lite 模型
import tensorflow as tf
# (运用高阶的tf.keras API创建一个模型)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1]),
tf.keras.layers.Dense(units=16, activation='relu'),
tf.keras.layers.Dense(units=1)
])
model.compile(optimizer='sgd', loss='mean_squared_error') # compile the model
model.fit(x=[-1, 0, 1], y=[-3, -1, 1], epochs=5) # train the model
# (下一行代码可以把Keras保存为SavedModel,仅做功能提示)
# tf.saved_model.save(model, "saved_model_keras_dir")
# (转换模型)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
# (保存模型)
with open('model.tflite', 'wb') as f:
f.write(tflite_model)内置工具转换 如果用 TensorFlow 内置的工具转换,请使用如下转换命令:
# 转换为SavedModel
tflite_convert \
--saved_model_dir=/tmp/mobilenet_saved_model \
--output_file=/tmp/mobilenet.tflite# 转换为Keras的H5模型
tflite_convert \
--keras_model_file=/tmp/mobilenet_keras_model.h5 \
--output_file=/tmp/mobilenet.tflite只用转换器还不行,如果自己写了一个 TensorFlow 的算子,现在想把它转成 TensorFlow Lite 支持的算子,该怎么办呢?
目前只支持单个的算子的转换
import tensorflow as tf
# (用tf.* API来创建一个模型)
class Squared(tf.Module):
@tf.function
def __call__(self, x):
return tf.square(x)
model = Squared()
# (运行模型)
result = Squared(5.0) # This prints "25.0"
# (产生SavedModel)
tf.saved_model.save(model, "saved_model_tf_dir")
concrete_func = model.__call__.get_concrete_function()
# (转换模型)
converter = tf.lite.TFLiteConverter.from_concrete_functions([concrete_func])
tflite_model = converter.convert()
# (保存模型)
with open('model.tflite', 'wb') as f:
f.write(tflite_model)上述代码仅仅解决掉了 TensorFlow 的算子如何转化为 TensorFlow Lite 的算子。
如果我写的算子,TensorFlow 支持,但是 TensorFlow Lite 不支持,该怎么办?
●
算子支持 TensorFlow,但是不支持 TensorFlow Lite:如果模型有尺寸限制的话,需要直接创建 TensorFlow Lite 操作符,否则直接在TensorFlow Lite模型中直接使用 TensorFlow 操作符即可。
●
算子不支持 TensorFlow,同时也不支持 TensorFlow Lite,也就意味着,需要在 TensorFlow Lite 中自定义算子了。
代码如下:
import tensorflow as tf
#(以y=sin(x)为例自定义算子)
def TFLiteAwesomeCustomOp(x):
return tf.sin(x, name="TFLiteAwesomeCustomOp")
# (自定义算子描述输入输出描述)
custom_opdef = """name: 'TFLiteAwesomeCustomOp' input_arg:
{ name: 'In' type: DT_FLOAT } output_arg: { name: 'Out' type: DT_FLOAT }
attr : { name: 'a1' type: 'float'} attr : { name: 'a2' type: 'list(float)'}"""
# (在调用转换器相关的API之前,注册自定义的opdefs)
tf.lite.python.convert.register_custom_opdefs([custom_opdef])
converter = tf.lite.TFLiteConverter.from_saved_model(...)
converter.allow_custom_ops = True
更多的自定义 TensorFlow Lite 算子的详细步骤,请参考:
https://tensorflow.google.cn/mlir/tfl_ops
关于元数据
使用代码进行转换的另一个好处是,可以通过代码去添加元数据。
元数据一般包括两部分,一部分是人可读的部分,一部分是设备可以操作的代码,示意如下:
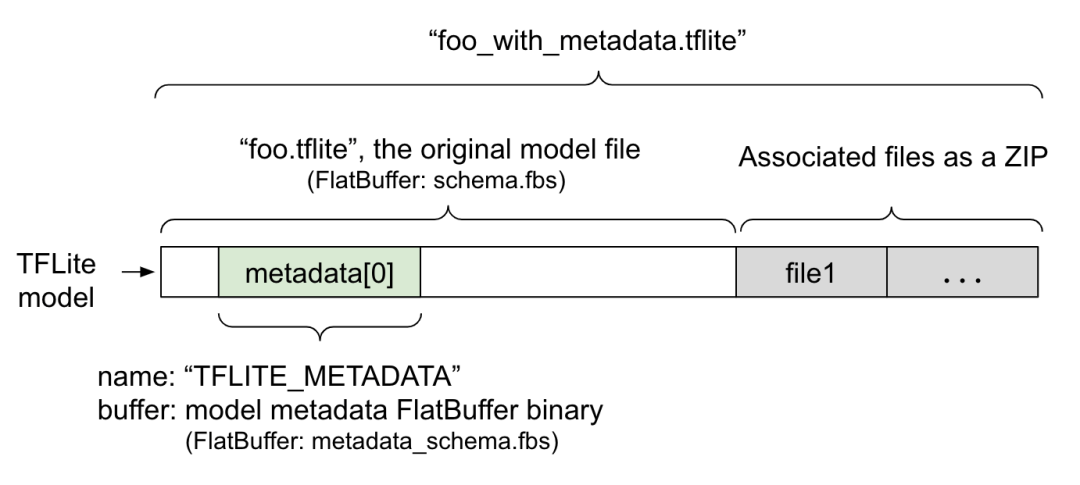
元数据格式
关于元数据的更多信息,请参考:
https://tensorflow.google.cn/lite/convert/metadata
如果用 TensorFlow 内置的工具转换,请使用如下转换命令:
# (转换为SavedModel)
tflite_convert \
--saved_model_dir=/tmp/mobilenet_saved_model \
--output_file=/tmp/mobilenet.tflite# (转换为Keras的H5模型)
tflite_convert \
--keras_model_file=/tmp/mobilenet_keras_model.h5 \
--output_file=/tmp/mobilenet.tflite4. 量化
TensorFlow Lite 的一个关键技术是量化,把浮点数转换为 int8 类型的整数,用于压缩模型,并且在推理阶段获得速度上的提升。量化一般是在模型转换阶段进行的,也就是在模型完成训练之后才进行的量化。
一般来说,在模型转换阶段,会做一些基本的量化工作,但是,TensorFlow 也提供了一些量化选项,通过以下的量化方法,可以获得更好的 TensorFlow Lite 模型。
|
技术 |
收益 |
硬件 |
|
动态范围量化 |
原始尺寸 1/4,2~3 倍的提速 |
CPU |
|
全整型量化 |
原始尺寸 1/4,3 倍提速 |
CPU, Edge TPU, 微处理器 |
|
16 位浮点量化 |
原始尺寸 1/2,GPU 加速 |
CPU,GPU |
实际上在 TensorFlow 的量化过程中,量化感知训练是在生成模型之前,可参考:
http://tensorflow.google.cn/model_optimization/guide/quantization/training
由于量化感知训练是属于 TensorFlow 模型建立时进行的,不属于单独的 TensorFlow Lite 的优化,我们就只关心模型转换阶段的量化过程。
量化的流程如下:
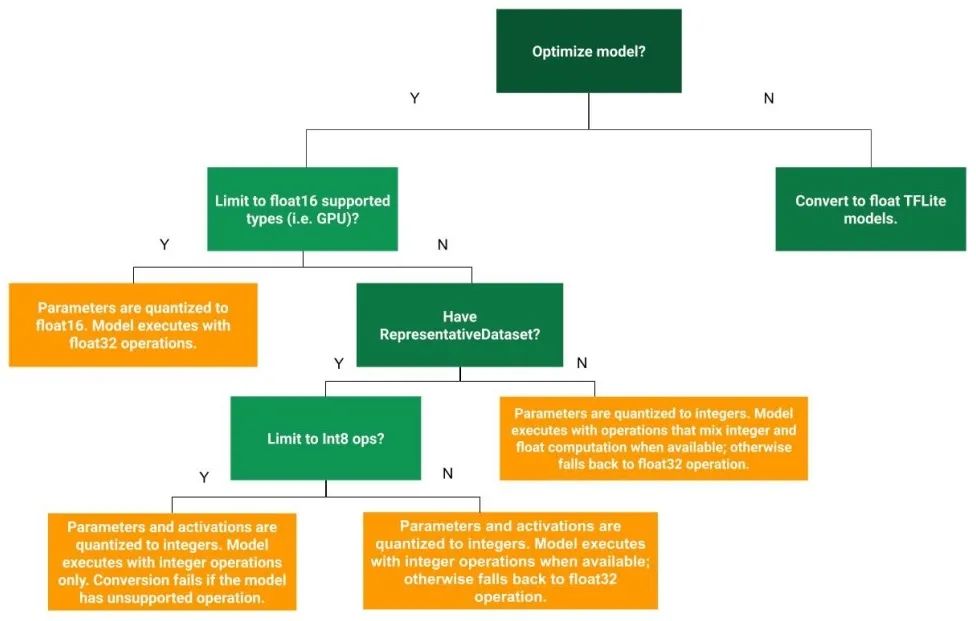
量化
如果选择量化的情况下,首先进行 16 位浮点量化。然后再检查是否有数据需要量化,如果有,则量化为 8 位整型。如果没有的话,还是按照 32 位浮点做支持。
动态范围量化相关代码
# (动态范围量化,只是在生成模型时,把浮点转为8位精度的整形,但是在推理阶段,仍然从8位精度转换成浮点,并且使用硬件的浮点计算单元完成计算,输出仍然用浮点存储。)
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()全整型量化
# (产生数据)
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
# (量化数据)
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
tflite_quant_model = converter.convert()
# (有可能导致输出结果仍然是浮点数,会与Edge TPU,以及8位的微处理器不兼容。如果要确保输入和输出都与上述的硬件兼容的话,需要采用以下的代码:)
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_quant_model = converter.convert()16 位浮点量化
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()16 位浮点量化,也会带来一些副作用
●
优点:减少模型尺寸,精度损失最小,并且直接对 16 位的浮点进行运算。
●
缺点:比定点的延迟多,在没有浮点运算单元的设备上会进行量化的逆操作。
有关量化的完整信息,请参考:
http://tensorflow.google.cn/lite/performance/post_training_quantization
5. 解释器
用于加载转换之后的模型到内存中,并且执行推理。
执行流程:
●
将模型加载到内存中。
●
基于现有模型构建一个解释器。
●
设置输入张量值。(如果不需要预定义的大小,可以选择调整输入张量的大小。)
●
调用推理。
●
读取输出张量值。
直接上代码
加载模型
class FlatBufferModel {
// 基于文件加载模型,如果创建失败,则返回nullptr
static std::unique_ptr<FlatBufferModel> BuildFromFile(
const char* filename,
ErrorReporter* error_reporter);
// 基于预加载的 flatbuffer 创建模型。 调用函数保留缓冲区的所有权并且保持它的活动直到返回的对象被销毁。 失败时返回 nullptr。
static std::unique_ptr<FlatBufferModel> BuildFromBuffer(
const char* buffer,
size_t buffer_size,
ErrorReporter* error_reporter);
// 备注: 如果 TensorFlow Lite 检测到Android NNAPI的存在 ,它会自动尝试使用共享内存来存储FlatBufferModel.
};运行模型
// 注意: 不能在并发线程中调用解释器。
// 加载模型
std::unique_ptr<tflite::FlatBufferModel> model =
tflite::FlatBufferModel::BuildFromFile(filename);
// 创建解释器
tflite::ops::builtin::BuiltinOpResolver resolver;
std::unique_ptr<tflite::Interpreter> interpreter;
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
// 如果需要的话,重定义输入张量
// 一旦调整完张量大小,就必须调用AllocateTensors来触发输入和输出张量的内存分配。
interpreter->AllocateTensors();
// 张量由整数表示,以避免与字符器进行比较
// 填充`input`.
float* input = interpreter->typed_input_tensor<float>(0);
interpreter->Invoke();
float* output = interpreter->typed_output_tensor<float>(0);最终完整的例子可参考以下网页:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/examples/minimal/minimal.cc
首先来看运行流程
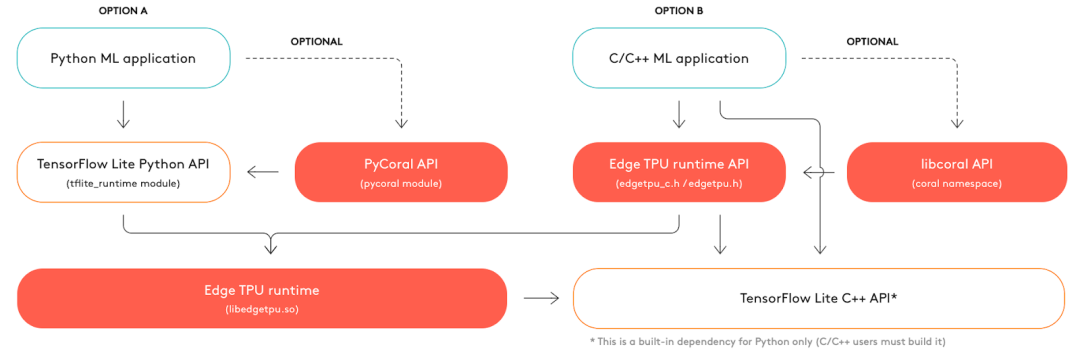
流程
详细的步骤可参考:
https://coral.ai/docs/edgetpu/inference/
需要提到的是,Edge TPU 的整套运行方案已支持
●
基于 Python 或 C++在 Edge TPU 进行模型部署
●
在多个 Edge TPU 运行多个模型
●
在多 Edge TPU 的流水线上运行单个模型
●
也可以在自己的架构上编译并运行 libedgetpu
方便性与灵活性充分展现出来了。
上代码
### 利用pycoral库运行推理
import os
import pathlib
from pycoral.utils import edgetpu
from pycoral.utils import dataset
from pycoral.adapters import common
from pycoral.adapters import classify
from PIL import Image
# 导入TensorFlow Lite库,标签以及要识别的图片
script_dir = pathlib.Path(__file__).parent.absolute()
model_file = os.path.join(script_dir, 'mobilenet_v2_1.0_224_quant_edgetpu.tflite')
label_file = os.path.join(script_dir, 'imagenet_labels.txt')
image_file = os.path.join(script_dir, 'parrot.jpg')
# 初始化TensorFlow解释器
interpreter = edgetpu.make_interpreter(model_file)
interpreter.allocate_tensors()
# 重新定义图片尺寸
size = common.input_size(interpreter)
image = Image.open(image_file).convert('RGB').resize(size, Image.ANTIALIAS)
# 运行推理
common.set_input(interpreter, image)
interpreter.invoke()
classes = classify.get_classes(interpreter, top_k=1)
# 打印结果
labels = dataset.read_label_file(label_file)
C++代码完成相同的任务
int main(int argc, char* argv[]) {
absl::ParseCommandLine(argc, argv);
// 加载模型
const auto model = coral::LoadModelOrDie(absl::GetFlag(FLAGS_model_path));
auto edgetpu_context = coral::ContainsEdgeTpuCustomOp(*model)
? coral::GetEdgeTpuContextOrDie()
: nullptr;
auto interpreter = coral::MakeEdgeTpuInterpreterOrDie(*model, edgetpu_context.get());
CHECK_EQ(interpreter->AllocateTensors(), kTfLiteOk);
// 读取图片到输出张量
auto input = coral::MutableTensorData<char>(*interpreter->input_tensor(0));
coral::ReadFileToOrDie(absl::GetFlag(FLAGS_image_path), input.data(), input.size());
CHECK_EQ(interpreter->Invoke(), kTfLiteOk);
// 读取标签
auto labels = coral::ReadLabelFile(absl::GetFlag(FLAGS_labels_path));
for (auto result : coral::GetClassificationResults(*interpreter, 0.0f, /*top_k=*/3)) {
std::cout << "---------------------------" << std::endl;
std::cout << labels[result.id] << std::endl;
std::cout << "Score: " << result.score << std::endl;
}
return 0;
}将多个模型运行在多个 Edge TPU 上。如果有多个模型,多个 Edge TPU,多个模型会默认在一个 Edge TPU 上运行,这将会极大的影响 Edge TPU 的性能。需要对不同的模型指定不同的 Edge TPU
# USB接口的Edge TPU设备
interpreter_usb1 = make_interpreter(model_1_path, device='usb:0')
# PCIE接口的Edge TPU设备
interpreter_pcie1 = make_interpreter(model_2_path, device='pci:0')如果要基于源码编译 libedgetpu,请移步
https://github.com/google-coral/libedgetpu
1. 在 Edge TPU 运行 Model
所需外设摄像头
所需外设开发板


camera
coral board
注意:
●
供电接口与数据线接口的区分,两个接口都是用的 type-c 接口。
●
供电电压 2v~3v,小于 2V 将无法正常启动开发板。
●
如果有显示需求,请外接 HDMI。
开发主机配置
#安装开发工具
$ pip3 install --user mendel-development-tool
#获取设备网址(网址为USB转网口产生的内部IP,不用关注)
$ mdt devices
device-name (192.168.100.2)
#下载源码,包含两个文件夹
#classifier-start为初始化代码
#classifier-end为最后结果的代码
$ git clone https://github.com/googlecodelabs/edgetpu-classifier代码流程
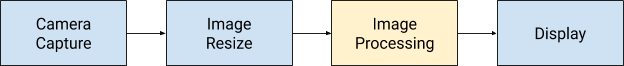
edge tpu
部署并运行
#将模型及相关库拷贝到Edge TPU上
$ cd classifier-start/
$ mdt exec mkdir /home/mendel/lib
$ mdt push lib/* /home/mendel/lib
$ mdt push models/* /home/mendel
$ mdt push main.py /home/mendel
# 获取设备终端,查看已拷贝内容
$ mdt shell
...
mendel@device-name:~$ ls
imagenet_labels.txt inception_v2_224_quant.tflite lib main.py
# 运行模型
mendel@device-name:~$ python3 main.py \
--model=inception_v2_224_quant.tflite \
--labels=imagenet_labels.txt如果自己创建模型,并且加载到 Edge TPU 上运行,步骤如下在刚才的 classifier-start 代码上做如下更改:
# main.py
# 初始化推理引擎
from edgetpu.classification.engine import ClassificationEngine
def init_engine(model):
"""返回Edge TPU当前模型对像"""
return ClassificationEngine(model)
# 确定张量形状
def input_size(engine):
"""返回模型的输入大小"""
_, h, w, _ = engine.get_input_tensor_shape()
return w, h
# 分析推理
def inference_time(engine):
"""返回推理时间"""
return engine.get_inference_time()
# 分类
def classify_image(tensor, engine, labels):
"""返回推理时间及推理结果,推理结果包含标签索引以及置信度得分这两个参数"""
results = engine.ClassifyWithInputTensor(
tensor, threshold=0.1, top_k=3)
return [(labels[i], score) for i, score in results]使用 Edge TPU 编译器生成 Edge TPU 所需的模型
# 添加源,并且安装相关软件
$ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
$ sudo apt-get update
$ sudo apt-get install edgetpu-compiler
# 优化模型
$ edgetpu_compiler model_A.tflite model_B.tflite# 更新后的脚本部署到设备
$ mdt push main.py /home/mendel
#重新运行脚本
mendel@device-name:~$ python3 main.py \
--model=inception_v2_224_quant.tflite \
--labels=imagenet_labels.txt
# 利用摄像头识别图片之后的结果
Inference time: 655.08 ms (1.53 fps) goldfish, Carassius auratus (0.96)Edge TPU 的另一个优化方向是,总共有 8M 的 SRAM, 它可以用一段 SRAM 来缓存模型的参数,这样如果模型参数不变的化,第一次运行较慢,后面运行速度很快,缓存模型参数的流程如下:
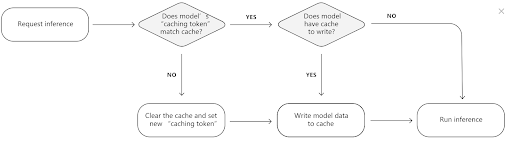
cache
Edge TPU 会为每一个模型分配一个缓存令牌,如果当前的模型与缓存令牌一致,则不用更改 cache 中的数据,如果当前模型与缓存令牌不致,则需要重新加载 cache,这样做的好处时,当一个模型长时间运行时,只需要第一次写入缓存即可,加快后续的模型推理速度。
到此,关于 TensorFlow Lite 相关的硬件软件的实现原理及流程,就告一段落了。
2. TensorFlow Lite Micro (TFLM) 硬件
官网地址:
https://tensorflow.google.cn/lite/microcontrollers+
代码地址:
https://github.com/tensorflow/tflite-micro
lab 地址:
https://experiments.withgoogle.com/collection/tfliteformicrocontrollers
所有的微处理器都是基于 Arm Cortex M 系列的 CPU,但是现在也在往其它处理器上做扩展,比如 Exp32 系列。
从这个角度来说,Google 并没有对 Microcontroller 做自家的芯片,而是现有的芯片上做软件的支持。
现有的部分硬件支持列表如下:
●
Arduino Nano 33 BLE Sense
●
SparkFun Edge
●
STM32F746 Discovery kit
●
Adafruit EdgeBadge
●
Adafruit TensorFlow Lite for Microcontrollers Kit
●
Adafruit Circuit Playground Bluefruit
●
Espressif ESP32-DevKitC
●
Espressif ESP-EYE
●
Wio Terminal: ATSAMD51
●
Himax WE-I Plus EVB Endpoint AI Development Board
●
Synopsys DesignWare ARC EM Software Development Platform
需要注意的是,Nano 33 BLE Sensor 这块开发板,分为带颜色拾取传感器,与不带颜色拾取传感器的硬件版本,如果训练的模型中包含颜色拾取相关的功能,一定要购买带颜色拾取传感器的开发板。各种开发板,或者开发平台,有不同的开发环境,需要严格按照对应的步骤来进行开发。
3. TensorFlow Lite Micro (TFLM) 软件
3.1 算子
从软件角度来说,现有的 TFLM 支持以下 ops:
通过:
https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/kernels/micro_ops.h
可以清楚的看到 TensorFlow Lite 与 TLFM 支持的算子的对比。
3.2 实例
建立模型的整个过程,有一份特别好的示例代码:
https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb
示例代码的训练流程如下:
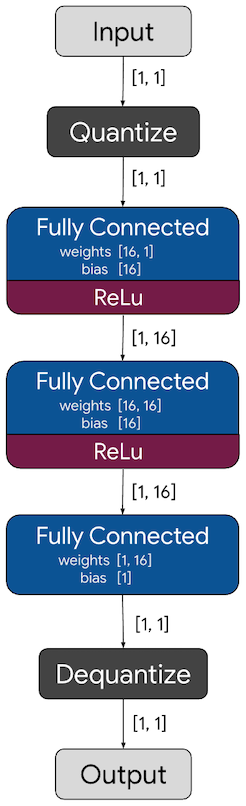
训练模型
首先通过之前的生成 TensorFlow Lite 的方法生成 TensorFlow Lite 的模型。但我们更关心的是,当前的模型编译成 TensorFlow Lite 的模型之后,如何转换成 TFLM 的模型。
上代码
# MODEL_TFLITE: TensorFlow Lite模型的路径, *.tflite格式的文件
# MODEL_TFLITE_MICRO: TFLM模型的路径,*.cc格式的文件
# 安装xxd工具
apt-get update && apt-get -qq install xxd
# 把TensorFlow Lite文件转换成c的源文件
xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}
# 更新变量名
REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')
!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}在 Linux 环境下,用 xxd 命令,把 TFLITE 的模型生成 C 语言数组即可。
这时候比较一下 TensorFLow 的模型到 TFLM 模型的一些差异。
|
名称 |
格式 |
目标框架 |
目标设备 |
|
model. pb |
Keras SavedMo del |
TensorFl ow |
云/服务器 |
|
model. tflite (2.5 kB) |
TensorFl ow Lite 模型,做过整型量化 |
TensorFl ow Lite |
移动/嵌入式设备 |
|
model. cc |
C 源码 |
TFLM |
微处理器 |
模型出来之后:接下来便是如何运行推理了。
我们依据 Hello World 的模型,把步骤完整的再现一下:
1. 加载头文件
// 提供运行模型所需要的算子
#include "tensorflow/lite/micro/all_ops_resolver.h"
// 输出调试信息
#include "tensorflow/lite/micro/micro_error_reporter.h"
// 加载并且运行模型
#include "tensorflow/lite/micro/micro_interpreter.h"
// TensorFlow Lite Flatbuffer模型的格式文件的架构
#include "tensorflow/lite/schema/schema_generated.h"
// TensroFlow Lite的版本信息
#include "tensorflow/lite/version.h"// 需要在整个C代码中,包含以下测试框架
TF_LITE_MICRO_TESTS_BEGIN
TF_LITE_MICRO_TEST(LoadModelAndPerformInference) {
. // add code here
.
}
TF_LITE_MICRO_TESTS_END2. 加载模型
代码的主要作用是用来检查我们生的模型是否与 TensorFlow Lite 的模型的版本架构兼容。
const tflite::Model* model = ::tflite::GetModel(g_model);3. 声明解析器
tflite::AllOpsResolver resolver;4. 分配内存 内存大小取决于实际的模型大小,我们也可以使用 arena_used_bytes 方法来获取真实的模型大小,用于后续分配相应的内存。
const int tensor_arena_size = 2 * 1024;
uint8_t tensor_arena[tensor_arena_size];5. 实例化解析器
tflite::MicroInterpreter interpreter(model, resolver, tensor_arena,
tensor_arena_size, error_reporter);6. 为张量分配内存
interpreter.AllocateTensors();7. 验证张量形状
// 首先拿到指向张量的指针,0表示第一个,也是唯一一个输入张量。
TfLiteTensor* input = interpreter.input(0);
// 检查当前的张量形状是我们所预期的
// dims方法表示张量的形状。每个维度都有一个元素,在这个例子中,我们的输入是2D的张量,包括一个元素,所以dims的值应该为2
TF_LITE_MICRO_EXPECT_EQ(2, input->dims->size);
// 每个元素的值表示相应张量的长度,我们这个例子中包括两个单元素张量。
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);
// 输入的类型是32位的浮点值
TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, input->type);
// KTfLiteFloat32 表示值的类型,完整的列表如下:https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/c/common.h8. 提供输入
input->data.f[0] = 0.;9. 运行模型
// 调用invoke方法运行模型
TfLiteStatus invoke_status = interpreter.Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed\n");
}
// 断言
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);10. 获取输出
TfLiteTensor* output = interpreter.output(0);
TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);
TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, output->type);
// 获取张量的输出
float value = output->data.f[0];
// 在示例代码中,判断值是否在0.05之内
TF_LITE_MICRO_EXPECT_NEAR(0., value, 0.05);11. 再次运行推理
input->data.f[0] = 1.;
interpreter.Invoke();
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(0.841, value, 0.05);
input->data.f[0] = 3.;
interpreter.Invoke();
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(0.141, value, 0.05);
input->data.f[0] = 5.;
interpreter.Invoke();
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(-0.959, value, 0.05);完代码可参考:
-
https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/examples/hello_world
3.3 编译模型
下载 git 仓库:
https://github.com/tensorflow/tflite-micro.git
1. 创建项目
可按自己的目标板设定,来选择相应的 TARGET。
make -f tensorflow/lite/micro/tools/make/Makefile \
TARGET=arc_emsdp \
OPTIMIZED_KERNEL_DIR=arc_mli \
generate_hello_world_make_project2. 编译
cd tensorflow/lite/micro/tools/make/gen/arc_emsdp_arc_default/prj/hello_world/make
make app
make flash接下来,可以按照不同的目标板的 flash 加载方法,把程序加载到相应的目标板,至少,我们完成了 TFLM 的完整的代码运行。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




