脑洞大开的机器视觉多领域学习模型结构 | CVPR 2018论文解读

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @jsh0123。本文来自牛津大学 VGG 组,论文模型结构比较有特点,改变了以往的阶段性参数获取模式,采用压缩方式适应性获取,对预训练的模型参数有记忆性,保留先前的领域知识。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:姜松浩,中国科学院计算技术研究所硕士生,研究方向为机器学习和数据挖掘。
■ 论文 | Efficient Parametrization of Multi-domain Deep Neural Networks
■ 链接 | https://www.paperweekly.site/papers/1800
■ 源码 | http://github.com/srebuffi/residual_adapters
论文亮点
这篇论文来自于牛津大学 VGG 组,该研究小组在机器视觉和迁移学习领域发表多篇重磅论文并且都被各类顶会录用,作者之一的 Andrea Vedaldi 就是轻量级视觉开源框架 VLFeat 的主要作者。
平常工程中或者参加过 Kaggle 比赛的都知道迁移学习对模型效果提升、训练效率提升的好处。这篇文章认为人类可以很快地处理大量不同的图像进行不同的任务分析,所以模型也能够经过简单的调整适应不同的场景。
本文提出了一种适合多领域、多任务、可扩展的学习模式,尽管当前阶段多领域学习有很大突破,但效果相比于专有模型略有差距。
作者提出一种参数获取模式——Parametric Family(图a),这种模式改变了以往的阶段性的参数提取(图b),需适应的参数更少,并且在参数较少的基础上使用了参数压缩方法依然可以保证模型的效果。
模型介绍
论文中提出了两种残差适配器,顺序残差适应器(Series Residual Adapters)和平行残差适应器(Parallel Residual Adapters)。两种模型的结构如下所示。

本文作者在 2017 年的 NIPS 上发表了一篇关于残差适应器(Residual Adapters)的论文 Learning multiple visual domains with residual adapters [1],这篇论文中将残差适应器定义为:
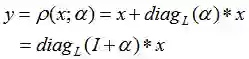
公式中 α 为适应参数,这样做法的好处是当 α 为 0 时,f 就恢复到曾经的状态,这样就保证了记忆性。当参数 α 进行强正则项时, α 会接近于 0(L1 正则和 L2 正则都会令参数接近于 0)。
这里作者们利用一种操作将 C×D 维的矩阵 A 进行重塑(Reshape)。

1. 顺序残差适应器(Series Residual Adapters)在前残差适应器(Residual Adapters)进行了改进。
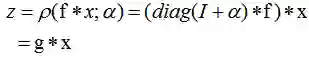
公式中 f 是标准的 filter,新的 filter g 可以看作是用 f 做为标准的低质的矩阵组合。
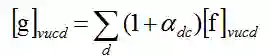
这样适应器相当于对卷积层 filter 加入了“保险”机制。并且适应参数 α 维度较小是 filter f 的 1/L^2 大小。
2. 平行残差适应器(Parallel Residual Adapters)和它的名字一样适应参数 α 采用一种平行的方式。
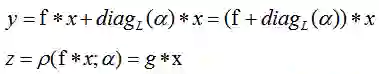
新的 filter g 可以按照如下公式定义:
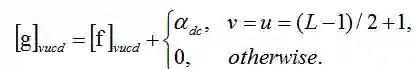
论文选择 RestNet [2] 作为两种残差适应器(Residual Adapters)的应用网络结构。论文中利用 SVD 矩阵分解将适应参数进行降维处理使得存储的参数变得更加低维。
模型实验效果
模型通过不同数据集,取 RestNet 的不同阶段应用残差适应器(Residual Adapters),并同常见的 Finetuning 以及两种不同的多领域学习模型 [1,3] 进行比较,得出实验结果如下所示。

平行残差适应器(Parallel Residual Adapters)进行参数压缩后的平均结果最佳,相较于 Finetuning 以及两种不同的多领域学习模型 [1,3] 都有很好的提升。
论文还验证了不同规模的数据集的效果和 fine-tuning 进行比较,得出小规模数据和中等规模数据上两种残差适应器的效果都比较好,特别是小规模数据集中表现总是优于 fine-tuning,但是在大量数据集中 fine-tuning 效果就要领先了。
论文评价
这篇论文的模型结构比较有特点,改变了以往的阶段性参数获取模式,采用压缩方式适应性获取,对预训练的模型参数有记忆性,保留先前的领域知识。
本文在效果上也相对不错,开拓了新的迁移学习模型结构,是多领域学习的一大突破,同时也是迁移学习领域的一个较为突出的进展。
参考文献
[1] S. Rebuffi, H. Bilen, and A. Vedaldi. Learning multiple visual domains with residual adapters. In Proc. NIPS, 2017.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In Proc. ECCV, pages 630–645. Springer, 2016.
[3] A. Rosenfeld and J. K. Tsotsos. Incremental learning through deep adaptation. arXiv preprint arXiv:1705.04228, 2017.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:


我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot02)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文




