Google论文解读:轻量化卷积神经网络MobileNetV2 | PaperDaily #38

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @chenhong。
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,其同样是一个轻量化卷积神经网络。目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:陈泰红,小米高级算法工程师,研究方向为人脸检测识别,手势识别与跟踪。
■ 论文 | Inverted Residuals and Linear Bottlenecks: Mobile Networks forClassification, Detection and Segmentation
■ 链接 | https://www.paperweekly.site/papers/1545
■ 源码 | https://github.com/Randl/MobileNet2-pytorch/
论文动机
很多轻量级的 CNN 模型已经在便携移动设备应用(如手机):MobileNet、ShuffleNet 等,但是效果差强人意。
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,实现分类/目标检测/语义分割多目标任务:以 MobileNetV2 为基础设计目标检测模型 SSDLite(相比 SSD,YOLOv2 参数降低一个数量级,mAP 无显著变化),语义分割模型 Mobile DeepLabv3。
MobileNetV2 结构基于 inverted residual。其本质是一个残差网络设计,传统 Residual block 是 block 的两端 channel 通道数多,中间少,而本文设计的 inverted residual 是 block 的两端 channel 通道数少,block 内 channel 多,类似于沙漏和梭子形态的区别。另外保留 Depthwise Separable Convolutions。
论文模型在 ImageNet classification,COCO object detection,VOC image segmentation 等数据集上进行了验证,在精度、模型参数和计算时间之前取得平衡。
Preliminaries, discussion and intuition
1. Depthwise Separable Convolutions
首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道 feature maps 之后,这时再对这批新的通道 feature maps 进行标准的 1×1 跨通道卷积操作。
标准卷积操作计算复杂度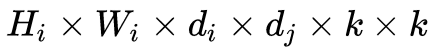
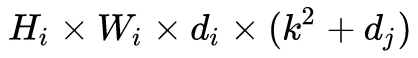
2. Linear Bottlenecks
本篇文章最难理解的是这部分,论文中有两个结论:
If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
感兴趣区域在 ReLU 之后保持非零,近似认为是线性变换。
ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
ReLU 能够保持输入信息的完整性,但仅限于输入特征位于输入空间的低维子空间中。
对于低纬度空间处理,论文中把 ReLU 近似为线性转换。
3. Inverted residuals
inverted residuals 可以认为是 residual block 的拓展。在 0<t<1,其实就是标准的残差模块。论文中 t 大部分为 6,呈现梭子的外形,而传统残差设计是沙漏形状。
模型结构
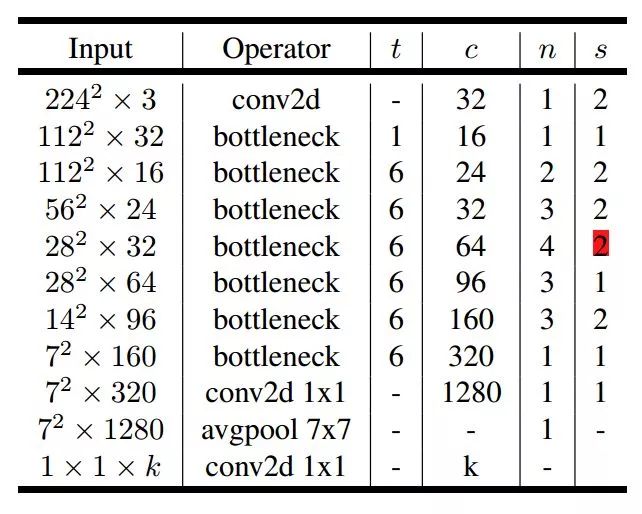
论文提出的 MobileNetV2 模型结构容易理解,基本单元 bottleneck 就是 Inverted residuals 模块,所用到的 tricks 比如 Dwise,就是 Depthwise Separable Convolutions,即各通道分别卷积。表 3 所示的分类网络结构输入图像分辨率 224x224,输出是全卷积而非 softmax,k 就是识别目标的类别数目。
1. MobileNetV2
MobileNetV2 的网络结构中,第 6 行 stride=2,会导致下面通道分辨率变成14x14,从表格看,这个一处应该有误。
2. MobileNetV1、MobileNetV2 和 ResNet 微结构对比
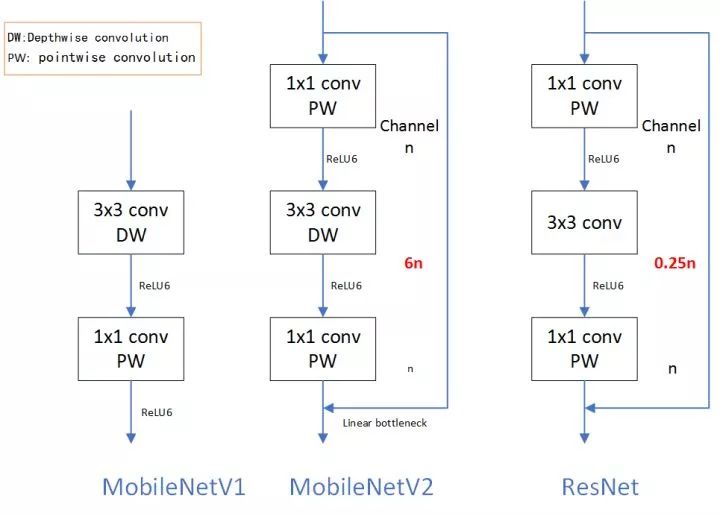
可以看到 MobileNetV2 和 ResNet 基本结构很相似。不过 ResNet 是先降维(0.25 倍)、提特征、再升维。而 MobileNetV2 则是先升维(6 倍)、提特征、再降维。
实验
1. ImageNet Classification
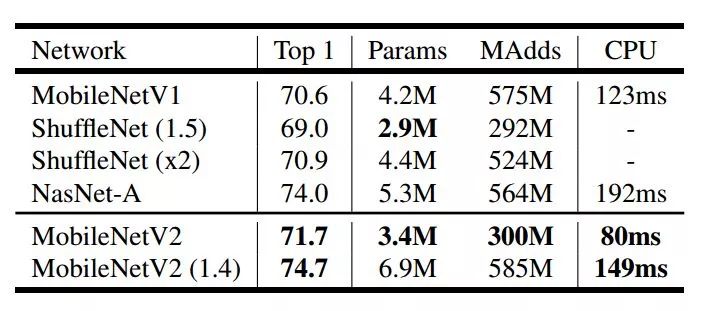
表 3 在 ImageNet 数据集对比了 MobileNetV1、ShuffleNet,MobileNetV2 三个模型的 Top1 精度,Params 和 CPU(Google Pixel 1 phone)执行时间。MobileNetV2 运行时间 149ms,参数 6.9M,Top1 精度 74.7。
在 ImageNet 数据集,依 top-1 而论,比 ResNet-34,VGG19 精度高,比 ResNet-50 精度低。
2. Object Detection
论文以 MobileNetV2 为基本分类网络,实现 MNet V2 + SSDLite,耗时 200ms,mAP 22.1,参数只有 4.3M。相比之下,YOLOv2 mAP 21.6,参数50.7M。模型的精度比 SSD300 和 SSD512 略低。
3. Semantic Segmentation
当前 Semantic Segmentation 性能最高的架构是 DeepLabv3,论文在 MobileNetV2 基础上实现 DeepLabv3,同时与基于 ResNet-101 的架构做对比,实验效果显示 MNet V2 mIOU 75.32,参数 2.11M,而 ResNet-101 mIOU80.49,参数 58.16M,明显 MNet V2 在实时性方面具有优势。
结论
CNN 在 CV 领域突破不断,但是在小型化性能方面却差强人意。目前 MobileNet、ShuffleNet 参数个位数(单位 M)在 ImageNet 数据集,依 top-1 而论,比 ResNet-34,VGG19 精度高,比 ResNet-50 精度低。实时性和精度是一对欢喜冤家。
本文最难理解的其实是 Linear Bottlenecks,论文中用很多公式表达这个思想,但是实现上非常简单,就是在 MobileNetV2 微结构中第二个 PW 后无 ReLU6。对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!


2017年度最值得读的AI论文 | NLP篇 · 评选结果公布
2017年度最值得读的AI论文 | CV篇 · 评选结果公布
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文


