Face++ 论文解读:一种新的行人重识别度量学习方法 | PaperDaily #20

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @LUOHAO,他也是这篇论文的作者之一。本文提出了一种新的度量学习方法 Margin sample mining loss, MSML。
Triplet loss 是一种非常常用的度量学习方法,Quadruplet loss 和 Triplet hard batch loss(TriHard loss)是它的两个改进版本,而 MSML 是吸收了 Quadruplet loss 和 TriHard loss 两个优点的综合体。
实验证明 MSML 能够在 person ReID 的公开数据集上取得很好的结果。 这个方法不止可以应用于 person ReID,而是一种通用的度量学习方法,进一步可以延伸到图像检索等相关的各个领域。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:罗浩,浙江大学博士研究生,研究方向为计算机视觉和深度学习,现为旷视科技(Face++)research intern。
■ 论文 | Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
■ 链接 | https://www.paperweekly.site/papers/1069
■ 作者 | LUOHAO
1. 摘要
Person re-identification (ReID) is an important task in computer vision. Recently, deep learning with a metric learning loss has become a common framework for ReID. In this paper, we propose a new metric learning loss with hard sample mining called margin smaple mining loss (MSML) which can achieve better accuracy compared with other metric learning losses, such as triplet loss. In experiments, our proposed methods outperforms most of the state-ofthe-art algorithms on Market1501, MARS, CUHK03 and CUHK-SYSU.
行人重识别是一个计算机视觉领域非常重要的一个任务。基于度量学习方法的深度学习技术如今成为了 ReID 的主流方法。在本论文中,我们提出了一种新的引入难样本采样的度量学习方法,这种方法叫做 MSML。实验表明,我们提出的方法击败了目前大多数的方法,在 Market1501,MARS,CUHK03 和 CUHK-SYSU 数据集上取得了 state-of-the-arts 的结果。
2. 方法
Triplet loss 是一种非常常用的度量学习方法,而 Quadruplet loss 和 TriHard loss 是它的两个改进版本。Quadruplet loss 相对于 Triplet loss 考虑了正负样本对之间的绝对距离,而 TriHard loss 则是引入了 hard sample mining 的思想,MSML 则吸收了这两个优点。
度量学习的目标是学习一个函数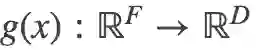
空间上语义相似度反映在
空间的距离上。
通常我们需要定义一个距离度量函数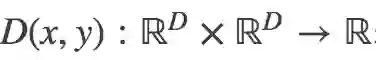
在国内外研究现状里面介绍的三元组损失、四元组损失和 TriHard 损失都是典型度量学习方法。给定一个三元组 {a,p,n},三元组损失表示为:
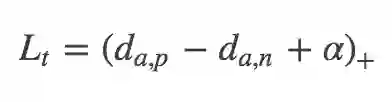
三元组损失只考虑了正负样本对之间的相对距离。为了引入正负样本对之间的绝对距离,四元组损失加入一张负样本组成了四元组 {a,p,n1,n2},而四元组损失也定义为:
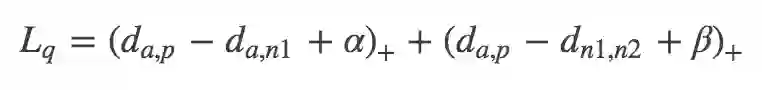
假如我们忽视参数 α 和 β 的影响,我们可以用一种更加通用的形式表示四元组损失:
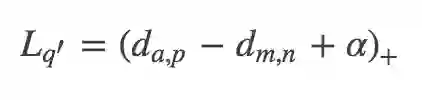
其中 m 和 n 是一对负样本对,m 和 a 既可以是一对正样本对也可以是一对负样本对。但是直接使用 Lq′ 并不能取得很好的结果,因为随着数据量的上升,可能四元组组合数量急剧上升。绝大部分样本对都是比较简单的,这限制了模型的性能。
为了解决这个问题,我们采用了 TriHard 损失使用的难样本采样思想。TriHard 损失是在一个 batch 里面计算三元组损失对于 batch 中的每一张图片 a,我们可以挑选一个最难的正样本和一个最难的负样本和 a 组成一个三元组。我们定义和 a 为相同 ID 的图片集为 A,剩下不同 ID 的图片图片集为 B,则 TriHard 损失表示为:
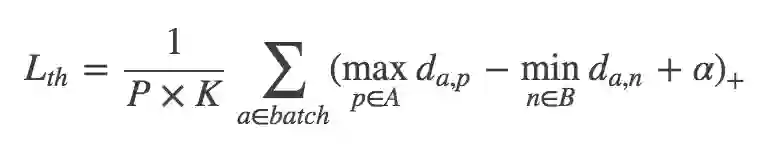
而 TriHard 损失同样只考虑了正负样本对之间的相对距离,而没有考虑它们之间的绝对距离。于是我们把这种难样本采样的思想引入到 Lq′,可以得到:
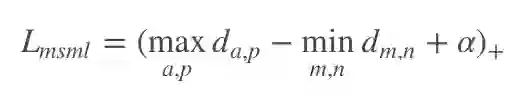
其中 a,p,m,n 均是 batch 中的图片,a,p 是 batch 中最不像的正样本对,m,n 是batch 中最像的负样本对,a,m 皆可以是正样本对也可以是负样本对。
概括而言 ,TriHard 损失是针对 batch 中的每一张图片都挑选了一个三元组,而 MSML 损失只挑选出最难的一个正样本对和最难的一个负样本对计算损失。所以,MSML 是比 TriHard 更难的一种难样本采样。
此外,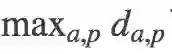
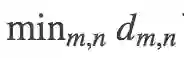
MSML 只用了两对样本对计算损失,看上去浪费了很多训练数据。但是这两对样本对是根据整个 batch 的结果挑选出来了,所以 batch 中的其他图片也间接影响了最终的损失。并且随着训练周期的增加,几乎所有的数据都会参与损失的计算。
总的概括,MSML 是同时兼顾相对距离和绝对距离并引入了难样本采样思想的度量学习方法。
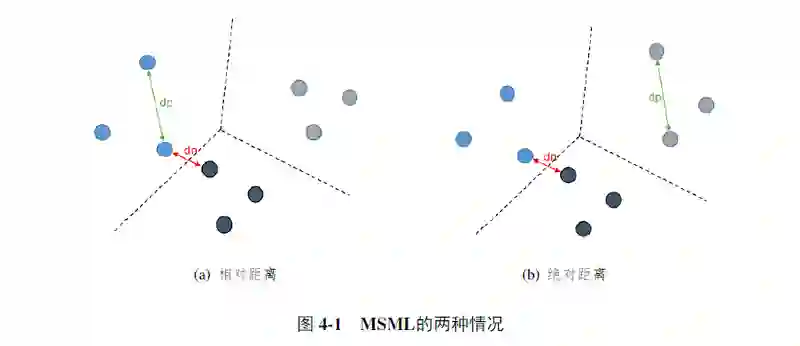
如果用一张图概括这几个 loss 之间的关系的话,可以表示为下图。
3. 结果
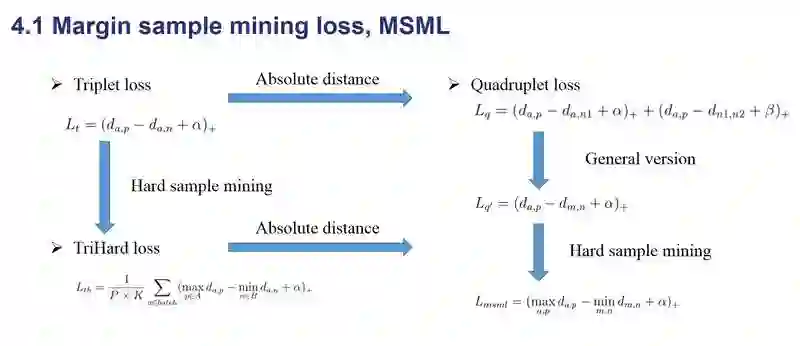
论文里在 Market1501,MARS,CUHK03 和 CUHK-SYSU 数据集都进行了对比实验,为了减少实验数量,并没有在每个数据集上都做一次实验,而是用所有数据集的训练集训练一个模型。
为了增加结果的可信度,使用了 Resnet50、inception-v2、Resnet-Xecption 三个在 ImageNet 上 pre-trained 的网络作为 base model,和 classification、Triplet loss、Quadruplet loss、TriHard loss 四个损失函数进行了对比。结果如下表,可以看出 MSML 的结果还是很不错的。
简评
MSML 是一种新的度量学习方法,吸收了目前已有的一些度量学习方法的优点,能过进一步提升模型的泛化能力。本文在行人重识别问题上发表了这个损失函数,但是这是一个在图像检索领域可以通用的度量学习方法。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



