ICCV2017 论文解读:基于图像检索的行人重识别 | PaperDaily #13

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期内容是由 PaperWeekly 社区用户 @LUOHAO 带来的 ICCV2017 行人重识别论文解读。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:罗浩,浙江大学博士研究生,研究方向为计算机视觉和深度学习,现为旷视科技(Face++)的 research intern。
■ 论文 | Neural Person Search Machines
■ 链接 | http://www.paperweekly.site/papers/1088
■ 作者 | LUOHAO
1. 摘要
作者调查了一下室外真实场景下的 Person ReID 工作,大部分相关工作都是 detection+ReID 分成两步来做的,这篇文章提出 NPSM 方法来实现一步到位。
NPSM 主要借助 LSTM 和 attention的思想,逐步衰减原图中所应该关注的 ROI 区域,直到最后得到一个很精确的 ROI 区域,这个区域就是应该搜索的 person 目标。实验结果表明,在 CUHK-SYSU 和 PWR 数据集上都取得了 State-of-the-arts 的结果。
2. Detection & ReID

上图给出了目前 Person ReID 的主流做法和本文做法的对比。(a) 是主流做法,先会用一个 detection 的模型检测图片中的行人图片,可能存在错误检测的 bounding box,然后用一个训练好的 ReID 模型把所有 bounding box 的图片和带检索的 Query 图片进行相似度比较,之后按照相似度进行一个排序,排名最靠前的就是检索的结果。
而 NPSM 则把两个结合起来,每次输入 ROI 区域图片,根据 Query 图片生成 attention map,然后选择 attention 比较大的区域作为新的 ROI 区域。所以新的 ROI 区域是之前输入 ROI 区域的子集,进过 LSTM 反复衰减这个 ROI,最终就可以得到一个比较精确的搜索结果。
当然这里不负责任的吐槽一下,这个插图很可能是为了体现这篇工作的一个“摆拍”。因为提供原图的 ReID 数据集比较少,论文里使用了 CUHK-SYSU 和 PWR 两个数据集,但是这幅图根据我的经验应该不属于这两个数据集,也许是为了体现主流方法失效而本文方法有效的一个摆拍吧。
因为在着装非常类似的情况下,比如都穿黄衣服的两个行人主流方法确实很难区分,所以不是很清楚这个是不是为了写论文自己去拍的或者从数据集里面特意挑选的。不过这都没关系,作为一副插图,很明白的展现自己工作的创新点,一图胜千言,所以这幅插图是非常合格的。
3. Neural Search Networks
这篇论文的模型以 seq2seq 为背景,主要在三个点上做改进。(1)在 embedding 上加情感信息(2)改进 loss function(3)beam search 时考虑情感。

Neural Search Networks (NSN) 主要的核心就是一个 Conv-LSTM 网络,CNN 网络采用的是 Resnet50。Resnet50 被分成了两部分,前面几层浅层特征用来提取 attention map,后面几层高层网络用来提取 ReID 所需要的 feature。
如上图所示,输入一张 query 图片,经过 Resnet50(Primitive Memory)之后会输出两个,一个是 ROI pooling 得到的 feature map,这个 feature map 用来输入到 NSN 里进行 attention map 的计算。另外一个就是输出的就行高层的 ReID feature,这个 feature 将会输入到 IDNet 进行 ReID 的识别任务。
Query 图片经过 Primitive Memory 网络的 part1 部分会得到一个 attention map q,之后 q 将会输入到 NSN 的 LSTM 单元里进行计算,传统的 LSTM 的 cell 是考虑隐状态和当前的输入
,在 NSN 中进一步增加了 query 图片的特征 q,最终改进后的 LSTM 的公示如下所示:

可以看出就是把 q 引入到 LSTM 里面去计算三个门的值而已。LSTM 单元的状态一直在变,但是输入的 q 是一直不变的,因为需要用新的 ROI 区域和 Query 图片比较来得到新的 attention map。不过 LSTM 的时间步长论文没有提及。
4. Region Shrinkage with Primitive Memory
上一个小节介绍了如何更新 attention map,但是得到 attention map 之后要如何得到 ROI 区域?
首先作者使用一个无监督的 object proposal 模型(例如 Edgeboxes)来产生很多个 proposal,很多 detection 的任务都是这样做的。之后每个 proposal 我们都可以得到其矩形的中点,之后利用中点的坐标来对这些 proposal 进行聚类。而作者使用最简单的欧氏距离来进行距离的衡量,假设 aa 和 bb 是两个 proposal 框的中点坐标,则它们的距离定义为:
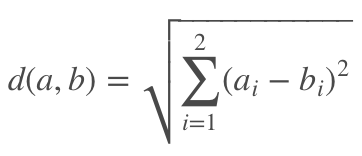
之后利用聚类算法可以将所有的 proposal 聚为 C 类,聚类细节论文没有提及。每一类的子区域由区域覆盖,所有
区域的父区域定义为
。这一块不是很看懂,可能
也是覆盖所有
区域的意思。很明显第 t 时刻的
区域是从 t−1 时刻的
中产生。
另外由于每次 NSN 输出的 ROI 区域大小都是不一样的,这对于后续计算 ReID 的 feature 是不好处理的,于是作者自己设计了一个 ROI pooling,保证不管输出多大的 ROI 区域,进过 ROI pooling 之后都可以得到一个固定大小 K×K×D 的 feature map 输入到后面的网络。
当然这个 pooling 的细节论文里也没透露。之后对于 K×K 的 feature map,我们可以计算它们的 attention 得分,其实就是很简单的做了一个二维的 softmax,公示如下:
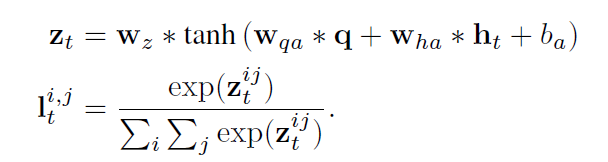
是每个像素点坐标的 attention 得分,加起来整幅图的总分就是 1。前面我们通过聚类得到了一些 proposal,现在我们就要计算每个 proposal 的重要性得分。实现方式就是计算每个 proposal 中所有像素重要性得分的平均值,那个 proposal 的平均值更高,就认为这个框的更重要,最终选择分最高的那个作为 ROI 区域输入到下一个时刻。
5. Training Strategy
LSTM 最后一个时刻输出的 ROI 区域进过 ROI pooling 进入到网络的 part2 计算 ReID feature,然后这个 feature 用来计算 ReID 的损失,作者在论文中使用 IDNet,也就是说把 ReID 当做分类问题来看待,计算分类损失。
另外还有一部分损失时输出的 bounding box 的损失,计算方法就是 grand truth 的 bounding box 中的像素如果落在 Rt 中就认为 ok,否则就算一个损失,就是一个很简单的 0-1 损失问题。这个损失会强迫 grand truth 落在网络的预测的 ROI 里面,并且随着 ROI 的衰减这个 ROI 会越来越接近 grand truth。
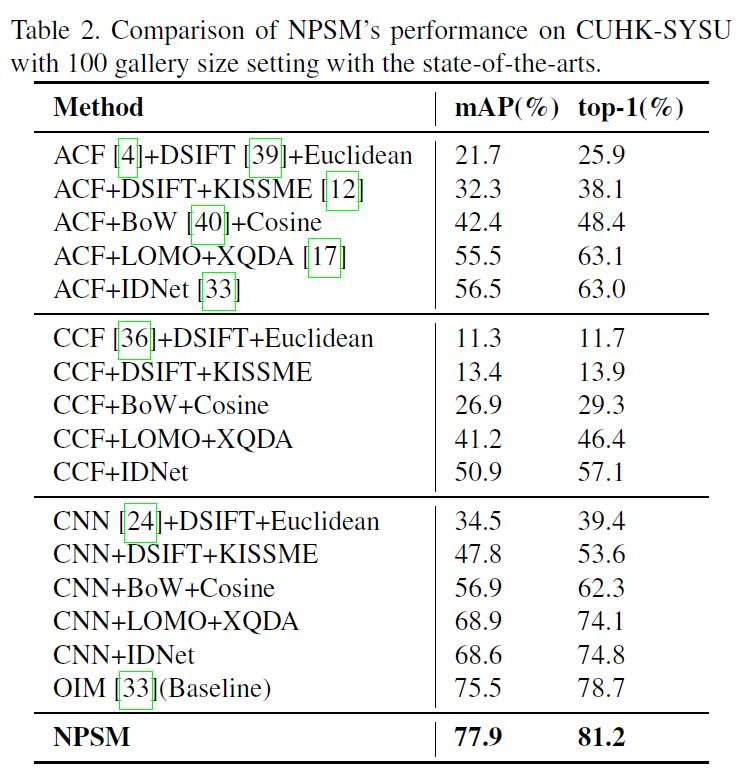
6. 结果
作者使用 CUHK-SYSU 和 PWR 两个数据集来验证算法的有效性,因为和一般 detection+ReID 的方法不同,所以计算 mAP 和 top-1 的方法有点不一样。mAP 和标准的 detection 任务的计算方法一样,使计算 bounding box 的坐标,而 top-1 计算是认为网络预测的 ROI 和 grand truth 重合度超过 50% 就认为识别正确。因此本论文也只能和自己思路一样的方法进行比较,最后结果是本文方法比 baseline 高了两个点左右。
从展现出来的 attention map 来看,方法还是比较不错的:

7. 简评
这篇论文的工作和主流的 ReID 工作不大一样,把 detection+ReID 结合在一起做,方法还是比较新颖的,不过有太多论文细节没有透露,除非作者公布源码否则复现起来基本不可能。另外除了 ReID 任务,我觉得这篇文章扩展成 tracking 可能更加有意义。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
我是彩蛋
解锁新姿势:用微信刷论文!
PaperWeekly小程序上线啦
今日arXiv√猜你喜欢√热门资源√
随时紧跟最新最热论文
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文





