CVPR 2018 最佳论文解读:探秘任务迁移学习


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @jindongwang。本次我们介绍刚刚在计算机视觉顶会 CVPR 2018 摘得最佳论文奖的文章:Taskonomy: Disentangling Task Transfer Learning。本文是继 2017 年 Open Set Domain Adaptation 在 ICCV 摘得 Marr prize 后,迁移学习在计算机视觉领域的又一次获奖。文章作者团队来自斯坦福大学和加州大学伯克利分校。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:王晋东,中国科学院计算技术研究所博士生,研究方向为迁移学习和机器学习。
■ 论文 | Taskonomy: Disentangling Task Transfer Learning
■ 链接 | https://www.paperweekly.site/papers/1876
■ 源码 | https://github.com/StanfordVL/taskonomy
论文介绍
文章题目其实有点难理解:Taskonomy 是一个什么东西,它可以“disentangle”任务迁移学习?“Disentangle”这个词,中文有“解耦、分清、解脱”等意思。但我个人觉得都太抽象了,所以我给了一个更好的名字:“探秘”。
这样,文章的主题就基本上定了:探索任务迁移学习。从题目中我们也可以知道,既然要探索,就必然要做大量的科学实验,这也是科研的必经之路。因此,我们可以管中窥豹:本文通过做大量的实验,来揭示任务迁移学习中的一些现象。
这篇论文插图、表格太多,我们不一一列举。
动机
文章的方法概括起来就叫做 Taskonomy (Task taxonomy),这是一个计算图,它定义了任务之间的可迁移性。图中的节点表示任务,节点之间的边就表示迁移性,边的权重表示从一个任务迁移到另一个任务的可能表现。这个方法是文章的核心。它一共由下图所示的 4 个步骤构成。
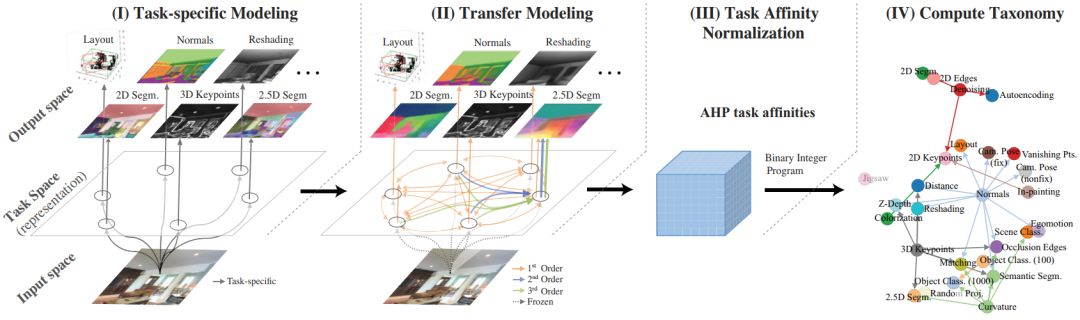
这 4 个步骤从逻辑上非常好理解。首先我们要对不同任务进行建模,然后让它们两两之间进行迁移并获取迁移的表现。接着为了构建一个统一的字典,我们对这些迁移结果进行归一化。最后,我们构建可迁移图。
在迁移实验开始前,最重要的是,需要一个可用的超大型数据集,要包含不同的任务。然而目前没有。怎么办?很简单,作者构建了一个!这个数据集有从 600 个建筑物内拍摄的 400 万张图片。每张图片都针对不同的任务做了标注,也就是说都适用于每个任务。就问你怕不怕?单凭这一个数据集就足够发一篇文章了,更别说这只是实验基础。
1. 针对目标的建模
这部分就是一个有监督学习,用的是编码-解码机制。目的是让神经网络针对特定的任务提取到强表征力的特征。
2. 迁移学习建模
这部分是整个方法的基础。给定一张图片 I,我们从上一步中学习到的特征表达表示为 E(I),那么迁移学习的目标就是要最小化以下损失:
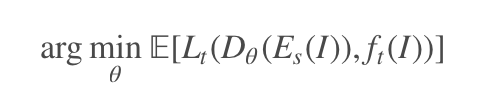
这个式子很好理解:Dθ 是学习到的模型,ft(I) 是 ground truth,Lt 是损失函数。
这里作者考虑了以下几种情况:
首先是 accessibility。用于迁移的网络不能太复杂,不然特征不具有可迁移性,会使问题难以继续。因此,作者选用了一个浅层的卷积网络,用少量的数据去训练。
然后是高阶的迁移。不同于简单地对一个 source 任务的一种特征表达的迁移,作者在这里考虑了高阶任务,即多个不同任务共同进行迁移。也就是我们在迁移学习中说的 multi-source domain。如果有 k 阶,则需要迁移的任务就有个。
最后是 transitive transfer,就是可传递式的迁移。作者也考虑到了这一点,做 A→B→C 的迁移。不过文章说在实验中并没有发现传递迁移对效果的提升。
3. 任务相似性标准化
这一步的目标很明确,就是构建一个迁移学习的相似度矩阵,从中我们可以很清楚地知道哪两个任务迁移效果最好。如何构建?我们本能地想到,可以把上一步中训练的损失函数拿来用。然而,不同任务下的损失函数不具有可比性,因此不能用。自然地,我们又想到了归一化,把所有的结果归一化到 [0,1] 之间。这也是通常用的办法。但是问题又来了,通常来说,神经网络的损失函数具有很大的震荡幅度,直接拿来用是不可行的。
作者提出了一种基于序列的方法,使得训练的表现和损失函数的值呈正相关。对于目标任务 t,用矩阵 Wt 来表示可迁移到 t 的源域任务的表现。矩阵中的元素 wij 就表示:在同一个分出来的测试集上,源域 si 迁移到 t,比 sj 迁移到 t 的表现好的百分比。比如 s1 到 t 要比 s2 到 t 好 15%。这个矩阵表示的是两两之间的比较,因此作者形象地把它叫做 tournament matrix(锦标赛矩阵)。
得到这个矩阵以后,还想知道到底一个源域比另一个要好多少,也就是说,打败了对方多少次?作者又做了一些小操作,比较简单。详细步骤可以参考原文。
最后作者对得到的新矩阵进行了特征分解,则 si 到 t 的迁移表现就是第 i 个特征向量。把所有目标域 t 的特征向量组合起来就得到了一个相似度矩阵。这个矩阵是归一化过的。
这个方法不是作者发明的,是之前有人发明的,叫做 Analytic Hierarchy Process。
4. 计算可迁移图
得到任务相似度矩阵后,我们的事情就简单了。我们需要在这个矩阵里找一条路,选择从多个源域到 t 的这条路上,迁移表现最好。这可以被看作是一个子图选择(subgraph selection)的问题。在这个图中,任务是节点,迁移性和迁移效果是边。
作者使用了之前的 Boolean Integer Programming 的方法来解决来个寻找子图的问题。具体过程不再详细描述。
实验
实验部分是本文的重点。作者收集的数据集共包含 26 个计算机视觉的通用任务。在这些任务上,作者进行源领域训练、单一迁移、高阶迁移,一共构建了大约 3000 个学习任务,一共需要 47886 个 GPU 小时来进行计算。读到这里,我们基本可以洗洗睡了:有钱真的可以为所欲为!
实验所用的所有编码器都是相同的,都基于 ResNet-50,去掉了 pooling 层。所有的迁移网络用的都是包含 2 个卷积的网络。损失函数和解码器就相应地根据不同任务进行调整。调整方式可见文章。
作者在一部分数据上进行实验,把这部分数据进行了如下的划分:训练集 120k,验证集 16k,测试集 17k。主要进行了以下方面的实验:
目标网络的性能
作者首先比较了不迁移情况下,目标网络的性能,也就是方法部分中的第 1 步。对比两个最近的方法可以看出,文章的网络性能不错。
领域相似度情况
作者验证了根据构建出的相似度矩阵进行相似度挖掘的实验,对不同的任务都画出了迁移性能图。从图中就可以清楚地知道哪些任务是对目标任务的迁移效果好坏。
作者又进一步对这些结果进行了更好的图示。
新任务上的泛化能力
将一个任务作为目标任务,其他 25 个任务作为源领域任务,考察模型在新任务上的泛化能力。实现效果显示这种迁移会比当前一些最好的非迁移深度方法还要好。从中我们得出的结论是,如果能够选择好源域任务,那么通常来说迁移学习的表现都要比直接从目标领域训练要好。
模型的扩展性
另外,作者还在 MIT Place 和 ImageNet 两个大型图像数据集上测试了方法的可扩展性。并且根据迁移效果,构建了迁移树用于进一步分析迁移表现。
局限性
作者还在文章花费很多篇幅讨论了自己方法的局限性。主要有以下几点:
方法可能依赖于特定的数据和模型:尽管作者在不同的大型数据集上做了大量实验,作者依然担心,方法可能会依赖于特定的数据和网络。这么实诚的人不多了。
任务的通用性:作者只是在一些认为定义的任务上进行了实验。但有没有可能有更复杂更高级的任务?
任务空间限制:可能还需要更多的实验。迁移到非视觉和机器人任务。这是一个值得考虑的问题。
终身学习:此方法目前还是离线的。如何实现在线终身学习?
总结
本文最大的亮点是,构建了非常多的迁移学习任务,详尽地探索了不同任务之间进行迁移的效果,为以后的研究提供了宝贵的基础。方法比较朴素,但是实现完备,很值得我们学习。作者在探索之外,还专门提供了一个数据集,这种精神值得钦佩!我们在今后的研究中,也要学习这种实验精神,多做,少说,慢慢积累。 迁移到非视觉和机器人任务。这是一个值得考虑的问题。
终身学习。此方法目前还是离线的。如何实现在线终身学习?
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

AI活动推荐
中国人工智能大会 CCAI 2018
AI领域规格最高、规模最大
影响力最强的专业会议之一
热点话题√核心技术√科学问题√
活动时间
2018年7月28日-29日
中国·深圳
长按识别二维码,查看大会简介
▼


神经网络与深度学习
作者:吴岸城 著
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



