李飞飞团队新作 - 有限标签的场景图预测
到目前为止,所有场景图模型都仅限于在一小部分视觉关系上进行训练,这些关系中每个都只有数千个训练标签。在本文中,作者从一个小的有限集合中自动生成缺失的关系标签,并使用这些自动生成的标签来训练下游场景图模型。
编译 | Xiaowen
链接:https://arxiv.org/abs/1904.11622

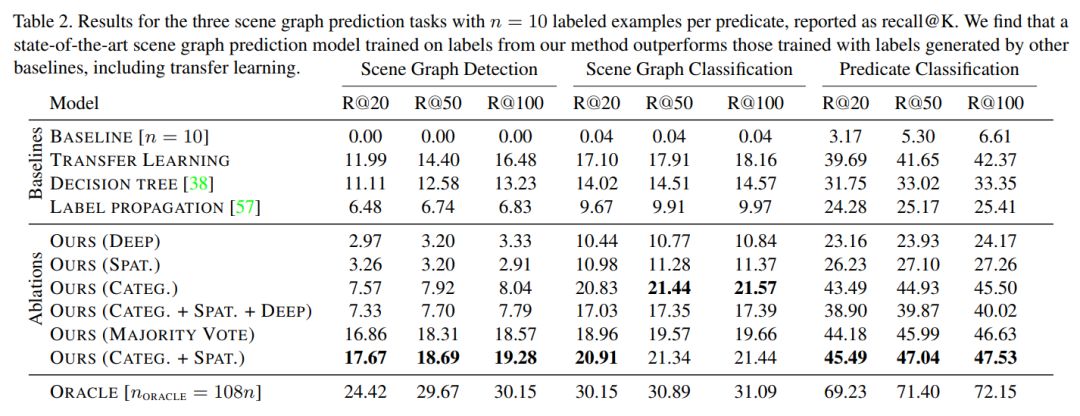
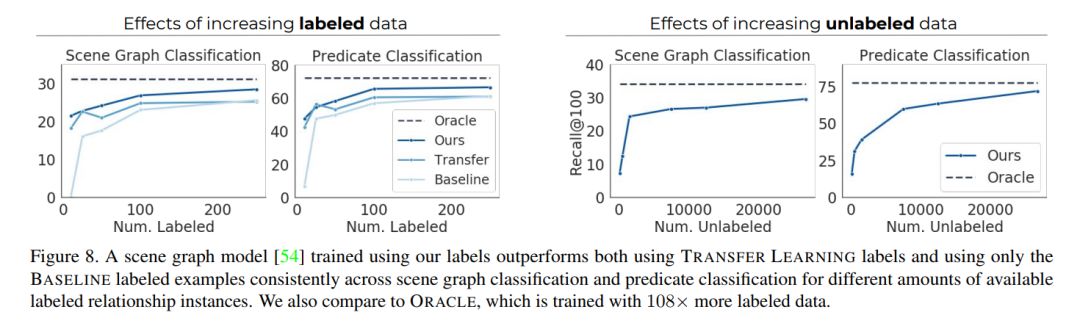
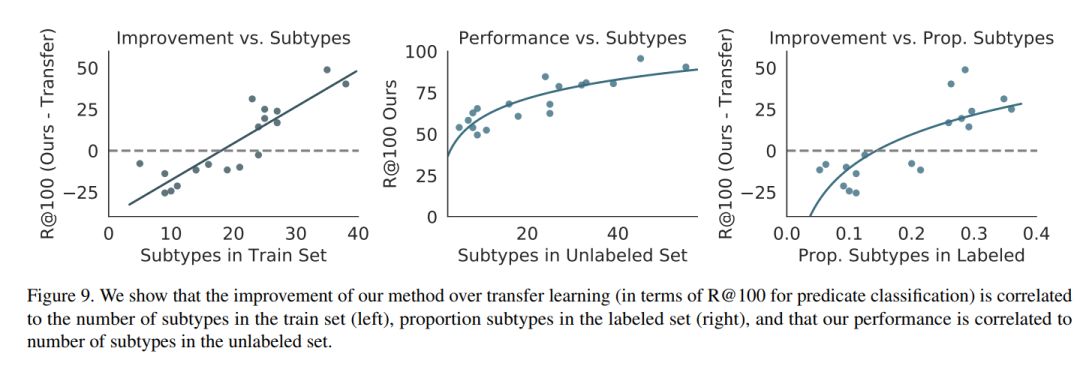
视觉知识库(如Visual Genome)为计算机视觉领域的众多应用提供了动力,包括视觉问答和captioning等,但它们之间存在着稀疏、不完全的关系。到目前为止,所有场景图模型都仅限于在一小部分视觉关系上进行训练,这些关系中每个都只有数千个训练标签。 雇用人工来进行标注的代价是非常昂贵的,而使用文本知识库来补全方法与可视化数据不兼容。本文介绍了一种半监督的方法,利用少量的标注实例,对大量的无标注图像打上概率关系标签。我们通过分析视觉关系,提出两种与图像无关的特征,它们被用来产生有噪声的启发式算法,它们的输出使用基于因子图的生成模型(a factor graph-based generative model)进行聚合。利用只有10个标注的关系示例,生成模型创建了足够的训练数据来训练任何现有的最先进的场景图模型。 实验证明,我们生成训练数据的方法比所有Baseline方法的性能都要好。由于我们只使用极少数标签,所以我们为关系定义了一个复杂性度量(R^2=0.778),作为表示我们的方法在什么条件下成功地超过了迁移学习的一个指标。
论文PDF获取方式:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“SGP”就可以获取李飞飞团队《Scene Graph Prediction with Limited Labels》论文PDF的下载链接~
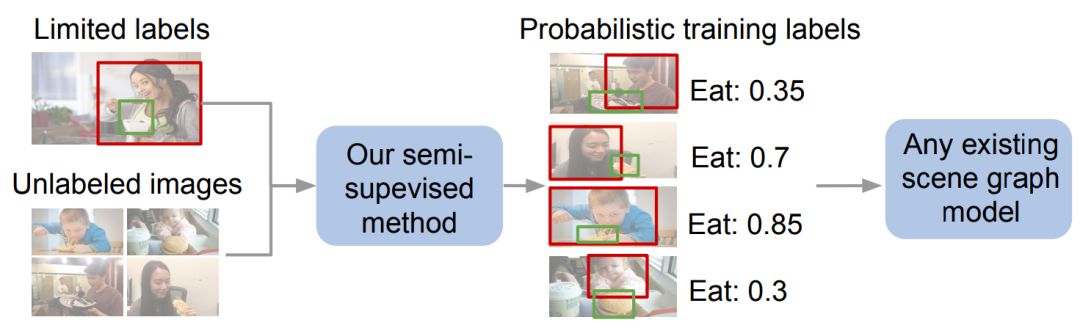
我们的半监督方法自动生成概率关系标签来训练任何场景图模型。
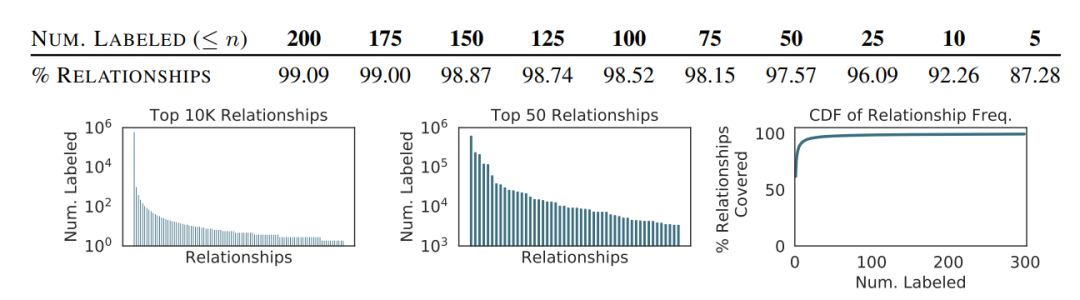
视觉关系有一个长尾的关系(左图),不经常出现。目前的模型只关注Visual Genome数据集中的前50种关系(中间图),它们都有数千个标签实例。其实这会忽略98%以上的关系,比如很少有标签的实例(右图,顶部表)。

有些关系,比如“fly”,“eat”,"sit"等关系可以通过它们的分类或空间特征来有效地描述。

我们定义了一些关系的子类型作为它的变形的度量。子类型可以是categorical,比如说其中一个子类型“ride”可以表示为<person-ride-bike>,或者<dog-ride-surfborad>。子类型也可以是spatial,比如“carry”有一个子类型是携带一个小物体再侧,另一个是扛个大物体举过头顶。
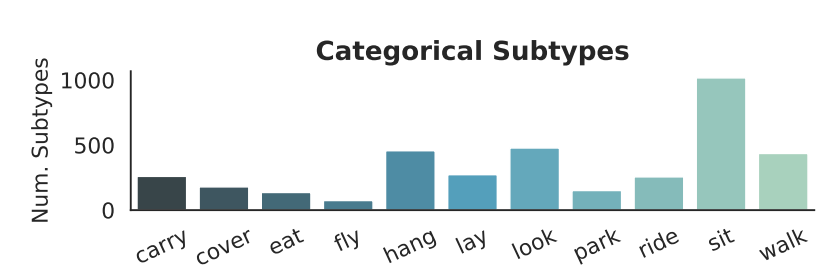
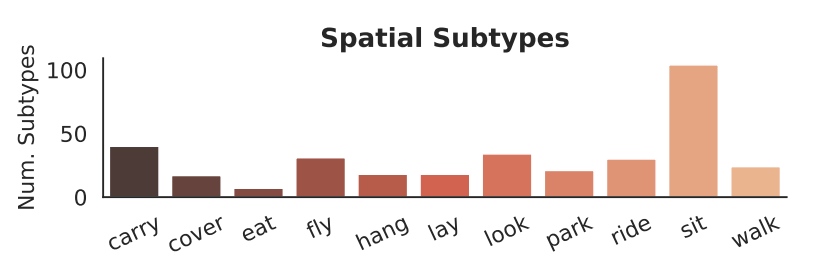
由空间和分类子类型定义的具有不同复杂程度的视觉关系的子集。
算法:

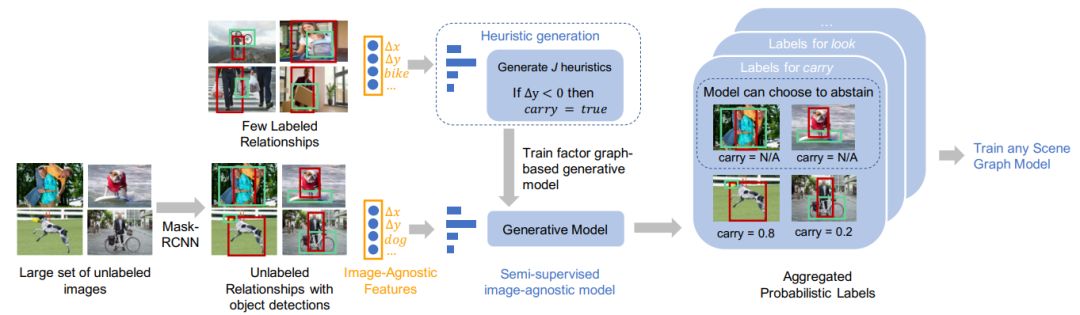
对于关系(例如carry),我们使用与图像无关的特征自动创建启发式,然后使用生成模型将概率标签分配给一大组未标记的图像。然后可以使用这些标签来训练任何场景图预测模型。

基于空间特征的启发式方法有助于预测<man-fly-kite>

我们的模型学习到look和phone高度相关

我们过分重视椅子(chair)的重要性,认为它是sit的一种绝对特征,而不能将悬挂(hang)视为正确的关系。

我们过分重视ride的空间位置特性

鉴于我们没有使用图像特征,我们生成了一个合理的标签<glass-cover-face>,但是,我们的模型不正确,因为两个典型的不同谓词(sit和cover)在上下文<glasses- ? -face>中共享一个语义。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!530+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




