性能优越!李飞飞团队首次提出一种补全视觉信息库的半监督方法

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)

为了使图像表征形式化,Visual Genome 定义了 场景图(Scene Graph)。 场景图是一种结构化的形式,它与广泛用于知识库的表示方法具有相似的形式。场景图将多个目标(例如:狗,飞盘)编码为节点,这些节点之间通过成对的关系作为边相连接(例如:在玩)。这种形式化的表达促进了图像标注、图像检索、视觉问答、关系模型和图像生成等方面的发展。然而,对于没有充分标注的实例,目前为止所有的场景图模型都忽略了超过 98% 的关系类别(图 1),这些模型主要侧重于解决具有上千个标注信息的实例的关系。

图 1:视觉关系的统计表示,目前大多数模型主要集中于解决 Visual Genome 数据集中的前五十种关系,这些关系包含上千个已标记的实例。这导致超 98% 种仅包含少量标注实例的视觉关系被忽略了。
为了对人工标注进行补充,通过使用半监督学习或弱监督(远监督)学习方法,许多基于文本知识补全的算法应运而生。但这类方法对于视觉关系不具有良好的泛化能力,这使得针对视觉知识的特殊方法成为急需解决的问题。
本文提出了一种自动化生成缺失关系类标的方法,该方法使用少量的标注数据集自动化地生成类标用来训练下游的场景图模型(图 2)
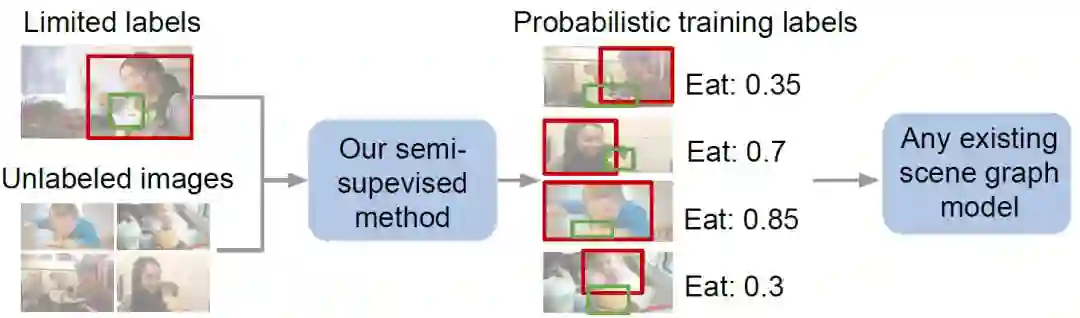
图 2:本文提出的半监督方法可以生成无标签数据的概率标签然后用于训练下游的场景图模型
本文的作者首先从如何定义 图像无关 特征(2.2 部分)对图像中的实例关系展开探索。例如,“吃” 这一行为通常由一个正在吃东西的目标和另一个比前者小的被吃的物体组成。再比如说 看 这个动作,该实例关系中通常包含手机、笔记本和窗口(图 3)。在视觉关系中,这些规则不需要原始的像素值并且可由 图像无关 特征推断而来,如物体类别、空间关系。尽管这些规则简单明确,但它们对于寻找丢失的视觉关系中的潜力 尚未被挖掘。
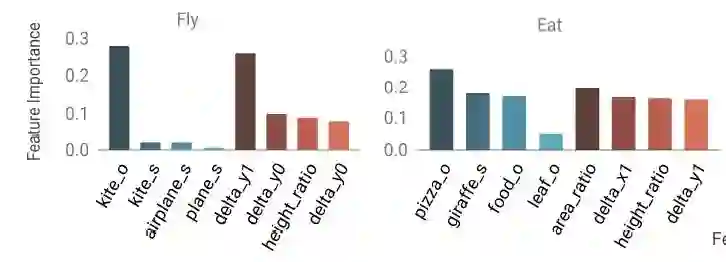
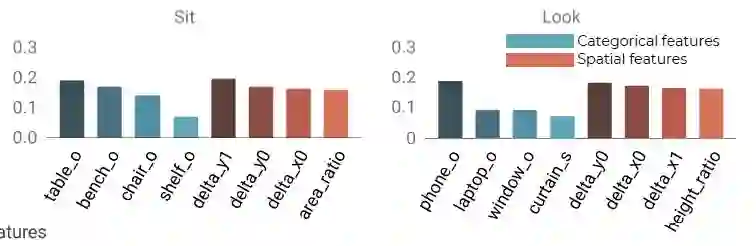
图 3:视觉关系,如“飞”、“吃”和“坐”可以有效地被形象化表示为他们的类别(图中 s 和 o 分别表示主体和客体)或空间特征。改图表示这些空间和类别特征对某一视觉关系的重要性。
从上图中可以看出,图像无关 特征可以在一些复杂视觉关系中捕获变化,这些视觉关系由于实例间的相互差异很难直接被刻画为某种表示。因此,为了量化我们的图像无关特征的重要性,本文的作者定义了“子类型”用来测量空间和类别的变化。


为了说明空间和类别特征可以很好的描述不同的视觉关系,作者对于每一种视觉关系都训练了一个决策树模型。在图 3 中画出了 4 中视觉关系中最重要的几个空间和类别特征,例如,“飞”跟主体还有客体的 y- 轴左边有很大的关系,“看”主要取决于物体类别(例如,手机、笔记本、窗户)而不依赖于任何空间方向。
为了系统的研究视觉关系的变化,作者将每个视觉关系定义为具有一定数量 子类型 的组合。例如,在图 4 中,“骑”包含了一个类别子类型<人 - 骑 - 自行车>和另一个类别子类型<狗 - 骑 - 冲浪板>。类似的,一个人可能会以多种不同的空间方式“拿”一个物体(例如,在头上,在身侧)。为了找到所有的空间子类,作者使用均值漂移聚类对 Visual Genome 中的所有视觉关系提取空间特征。为了找到类别子类,作者对一个视觉关系中的所有物体类别进行了数量统计。

图 4:同一视觉关系的不同子类,上半部分均为“骑”,下半部分均为“拿”。
对于无标注的数据集 Du,作者使用了三步来获得其概率标签:(1)作者提取了已标注数据集 Dp 的图像不变特征,同时结合目标检测算法提取 Du 中候选物体的图像不变特征;(2)对图像不变特征使用启发式生成算法;(3)使用基于因子图的生成模型对概率标签进行聚合并赋给 Du 中的未标注物体对。具体算法在论文原文的 Algorithm1 中有详细叙述,整个系统的端到端框架如图 5 所示。
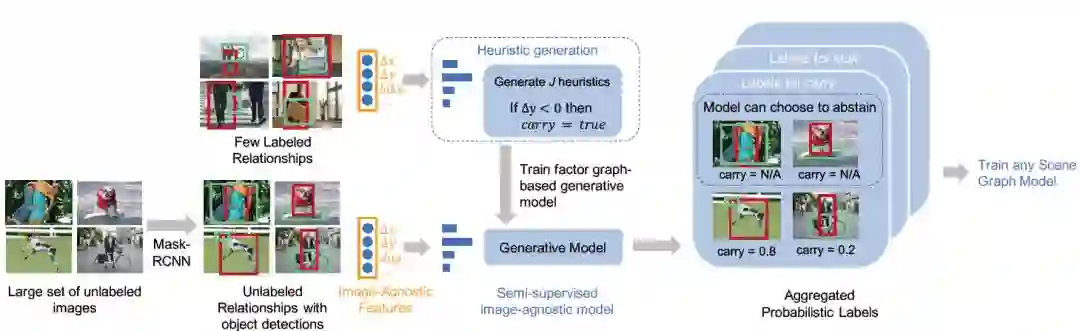
图 5:本文提出算法的整体框架图,图中以“拿”这一关系作为示例进行展示。
提取图像无关特征需要用到现有的目标检测算法,这里作者使用了 Mask-RCNN 来生成无标签数据物体候选框,然后使用使用第三部分所述的图像无关特征的定义计算无标注数据的图像无关特征。对于已标注的数据,则直接利用其标注的候选框计算图像无关特征。
作者使用已标注的视觉关系中的空间和类别特征训练了一个决策树。同时,作者对这些启发式算法的复杂度进行了约束以防止模型过拟合。这里作者使用了浅层的决策树网络,对于每一个特征集使用不同的深度约束,这样就产生了 J 个不同的决策树。随后作者使用了这些启发式算法预测无标签数据集的标签,得到所有无标签关系的预测矩阵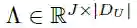

图 6:视觉关系的一个子集,空间和类别子类决定了不同程度的复杂度。
为了更进一步的防止过拟合,作者通过设置一个置信度阈值对Λ进行调整。最终的启发式算法如图 5 中的示例所示,当一个主体在客体上方时候,则会对谓语部分的 拿 这一动作的类标赋予正值。

最终,这些概率类标被用于训练任何一种场景图模型。场景图模型通常使用交叉熵损失进行训练,作者对该函数进行了调整,这是为了将生成模型的标注错误也考虑进去。最终,作者使用了一种噪声感知经验误差函数来优化场景图模型:
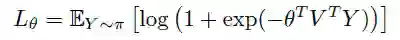
其中θ是需要学习的参数,Π表示使用生成模型学到的分布,Y 是真实类标,V 是使用任意场景图预测模型提取的视觉相关特征。
作者首先在 VRD 数据集上对生成模型的标注能力进行了测试,以验证生成模型是否具有寻找丢失的视觉关系的能力。然后,作者使用生成的类标训练了目前最好的场景图模型。作者将生成的标签与 Visual Genome 数据集的类标进行了比较。最后,作者将本文的方法与迁移学习方法进行了对比。VRD 和 Visual Genome 模型都是视觉关系预测和场景图识别方向的两个标准数据集。由于 Visual Genome 数据库规模太大(108K 张图像),每个场景图的标签都不完整,因此作者仅在 VRD 数据集上对半监督算法的进行了验证。
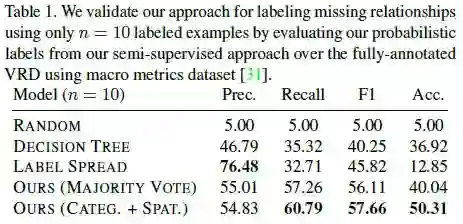
作者为了验证他们提出的半监督方法能够很好地标注丢失的视觉关系,作者在 VRD 数据集的测试集上计算了精确度和召回率。实验结果如下表所示:
为了展示概率标签的效果,作调整了现有的场景图模型并使用了三种标准评价模式:1)场景图检测(SGDET),该模式输入图像,预测出其边界框、物体类别和谓语类标。2)场景图分类(SGCLS),该模式输入真实边界框,预测出图像的物体类别和谓语类标。3)谓语分类(PREDCLS),该模式输入边界框的真实集合和物体类别,预测图像的谓语类标。关于这三种任务的详细介绍作者推荐了文章 [1] 供读者们参考。本文的方法在这三个任务上的实验结果如下表所示:
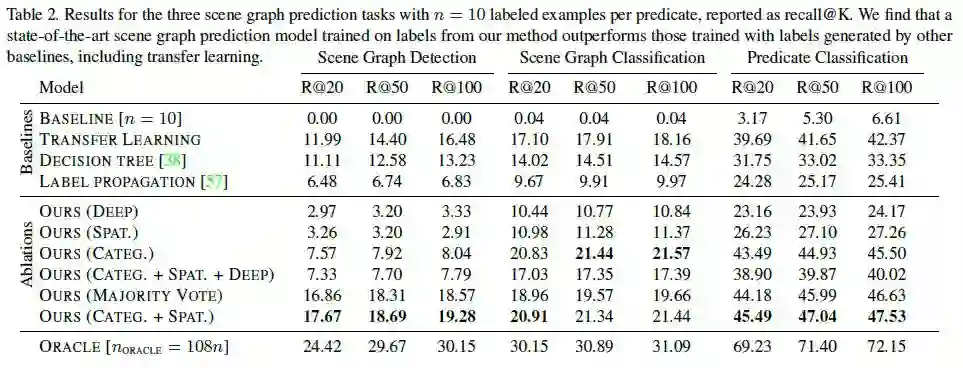
该表中,作者采用 ORACLE 作为模型性能的上边界,因为这个方法的实验结果是在整个 VIsual Genome 上训练得到的,作者希望提出的方法能够尽量与 ORACLE 达到相同的效果。表格的上半部分是一些基线方法,其中 DECISION TREE 是一种提取图像无关特征的单决策树方法,LABEL PROPAGATION 是一种应用广泛的半监督方法,TRANFER LEARNING 则使用了一种通用的迁移学习方法进行训练。
表格的下半部分是消融实验结果,即对作者提出方法的每个部分进行有效性验证。(CATEG.)表示仅使用类别特征,(SPAT.)表示仅使用空间特征,(DEEP)表示仅使用 ResNet50 提取的深度特征,(CATEG.+SPAT.)表示使用级联的类别和空间特征,(CATEG.+SPAT.+DEEP)表示三者结合。(MAJORITY VOTE)则是使用类别和空间特征,同时使用简单的多数投票方法而不是使用生成模型来聚合启发式函数的输出的方法。可以看出本文提出的方法在多个模式下都体现出卓越的效果。
作者绘制了本文提出方法的类标赋值情况,与图 3 中相关的图像无关特征进行了比较,类标可视化结果如下图:

在 (a) 中,本文的模型预测出了“飞”这个位于,因为它学习到了“飞”这个动作表示两个物体在 y 轴上的存在巨大差异。在(c)中,本文提出的模型则做出了错误的预测,将“挂”理解为了“坐”,这是因为模型过度的依赖于类别特征中“椅子”和“坐”密不可分的关系。
本文的作者首次提出了一种补全视觉信息库的半监督方法,该方法利用图像无关特征尽可能地用少于 10 个标注实例来刻画每一种视觉关系。然后通过对这些特征进行启发式学习训练,最后使用生成模型为无标注图像分配概率标签。作者在 VRD 数据集上进行了测试,实验结果表明本文提出的模型性能在标注方面比标准的半监督方法(例如标签传播)高出了 11.84 点,F1 分数达到了 57.66。
为了进一步验证生成类标的作用,作者对目前最好的场景图模型进行微调从而使其可以使用生成的概率标签进行训练。使用概率标签训练后的模型在 Visual Genome 数据库上达到了 46.53recall@100(召回率 100 时的识别准确率),与仅使用有标注实例训练后的模型相比提升了 40.97 个点。同时,作者还与其他迁移学习方法进行了对比。在召回率为 100 时,本文提出的方法比其他迁移学习方法高出 5.16 个百分点,这是因为对于未标注的子类本文提出的方法具有更好的泛化能力,尤其是具有高复杂度的视觉关系。
论文原文链接:https://arxiv.org/abs/1904.11622

你也「在看」吗?👇