模型不收敛,训练速度慢,如何才能改善 GAN 的性能?

AI 研习社按:本文为雷锋字幕组编译的技术博客,原标题 GAN — Ways to improve GAN performance,作者 Jonathan Hui。
翻译 | 姚秀清 郭蕴哲 校对 | 吴桐 整理 | 孔令双
与其他深度网络相比,GAN 模型在以下方面可能会受到严重影响。
不收敛:模型永远不会收敛,更糟糕的是它们变得不稳定。
模式崩溃:生成器生成单个或有限模式。
慢速训练:训练生成器的梯度会消失。
作为 GAN 系列的一部分,本文探讨了如何改进 GAN 的方法。 尤其在如下方面,
更改成本函数以获得更好的优化目标。
在成本函数中添加额外的惩罚以强制执行约束。
避免过度自信和过度拟合。
更好的优化模型的方法。
添加标签。
特征匹配
生成器试图找到最好的图像来欺骗鉴别器。当两个网络相互抵抗时,“最佳“图像会不断变化。 然而,优化可能变得过于贪婪,并使其成为永无止境的猫捉老鼠游戏。这是模型不收敛且模式崩溃的场景之一。
特征匹配改变了生成器的成本函数,用来最小化真实图像的特征与生成图像之间的统计差异,即,它将目标从击败对手扩展到真实图像中的特征匹配。 我们使用图像特征函数 f(x) 对真实图像和生成图像的均值间的L2范数距离来惩罚生成器。
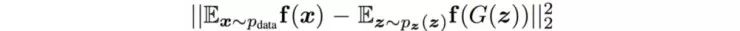
其中 f(x) 是鉴别器立即层的输出,用于提取图像特征。
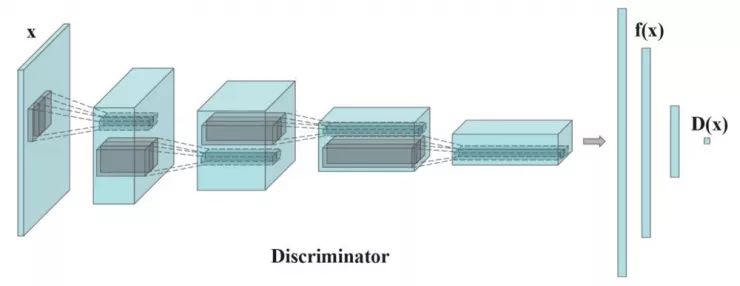
每个批次计算的实际图像特征的平均值,都会波动。这对于减轻模式崩溃来说可能是个好消息。它引入了随机性,使得鉴别器更难以过拟合。
当 GAN 模型在训练期间不稳定时,特征匹配是有效的。
微批次鉴别
当模式坍塌时,创建的所有图像看起来都相似。为了缓解这个问题,我们将不同批次的实际图像和生成的图像分别送给鉴别器,并计算图像 x 与同一批次中其余图像的相似度。 我们在鉴别器的一个密集层中附加相似度 o(x) ,来确定该图像是真实的还是生成的。
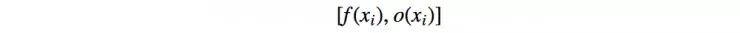

如果模式开始崩溃,则生成的图像的相似性增加。鉴别器可以使用该分数来检测生成的图像。这促使生成器生成具有更接近真实图像的多样性的图像。
图像 xi 与同一批次中的其他图像之间的相似度 o(xi) 是通过一个变换矩阵 T 计算得到的。如下所示,xi 是输入图像,xj 是同一批次中的其余图像。
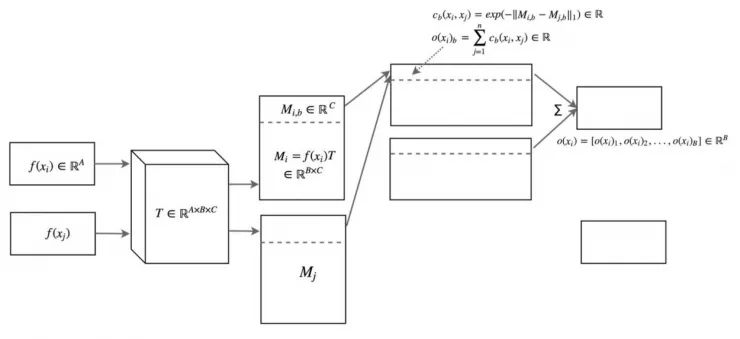
方程式有点难以追踪,但概念非常简单。(读者可以选择直接跳到下一部分。)我们使用变换矩阵 T 将特征 xi 转换为 Mi , 一个 B×C 的矩阵。

我们使用 L1 范数和下面的等式导出图像 i 和 j 之间的相似度 c(xi, xj) 。

图像 xi 与批次中其余图像之间的相似度 o(xi) 为
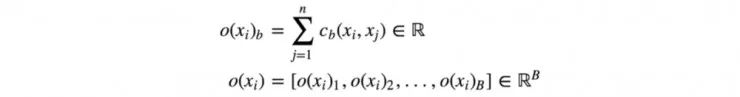
这里是回顾:
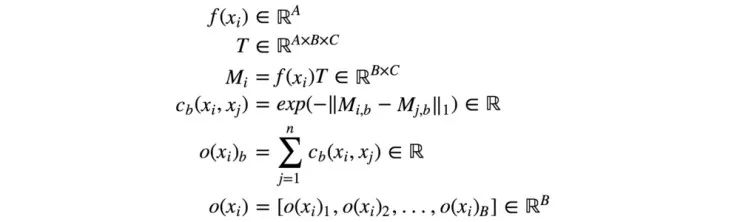
引用自论文“ Improved Techniques for Training GANs ”
微批次鉴别使我们能够非常快速地生成视觉上吸引人的样本,在这方面它优于特征匹配。
单面标签平滑
深度网络可能会过自信。 例如,它使用很少的特征来对对象进行分类。 深度学习使用正则化和 Dropout 来缓解问题。
在 GAN 中,我们不希望模型过拟合,尤其是在数据噪声大时。如果鉴别器过分依赖于某一小组特征来检测真实图像,则生成器可能迅速模仿这些特征以击败鉴别器。在 GAN 中,过度自信的负面作用严重,因为鉴别器很容易成为生成器利用的目标。为了避免这个问题,当任何真实图像的预测超过 0.9(D(实际图像)> 0.9)时,我们会对鉴别器进行惩罚。 这是通过将目标标签值设置为 0.9 而不是 1.0 来完成的。 这里是伪代码:
p = tf.placeholder(tf.float32, shape=[None, 10])
# Use 0.9 instead of 1.0.
feed_dict = {
p: [[0, 0, 0, 0.9, 0, 0, 0, 0, 0, 0]] # Image with label "3"
}
# logits_real_image is the logits calculated by
# the discriminator for real images.
d_real_loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=p, logits=logits_real_image)
历史平均
在历史平均中,我们跟踪最后 t 个模型的模型参数。 或者,如果我们需要保留一长串模型,我们会更新模型参数的运行平均值。
我们为成本函数添加了如下的一个 L2 成本,来惩罚不同于历史平均值的模型。
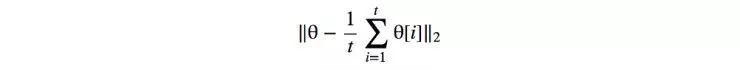
对于具有非凸对象函数的 GAN,历史平均可以迫使模型参数停止围绕平衡点兜圈子,从而令其收敛。
经验回放
为了击败生成器当前产生的内容,模型优化可能变得过于贪婪。为了解决这个问题,经验回放维护了过去优化迭代中最新生成的图像。我们不仅仅使用当前生成的图像去拟合模型,而且还为鉴别器提供了所有最近生成的图像。因此,鉴别器不会针对生成器某一特定时间段生成的实例进行过度拟合。
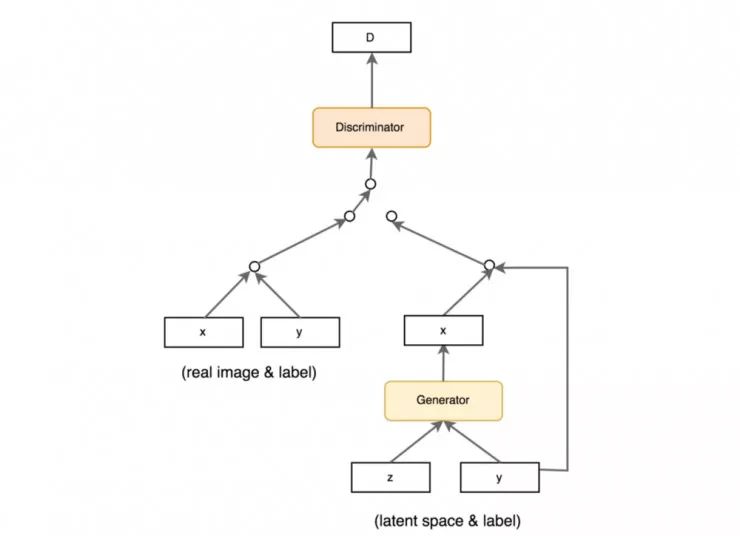
使用标签(CGAN)
许多数据集都带有样本对象类型的标签。训练 GAN 已经很难了。因此,对于引导 GAN 的训练来说,任何额外的帮助都可以大大提高其性能。添加标签作为潜在空间 z 的一部分, 有助于 GAN 的训练。如下所示 , CGAN 中采用的数据流就充分利用了样本的标签。
成本函数
成本函数重要吗? 它当然重要,否则那么多研究工作的心血都将是一种浪费。但是如果你听说过 2017 年 Google Brain 的一篇论文,你肯定会有疑虑。 但努力提升图像质量仍然是首要任务。因此在我们对成本函数的作用有一个明确的认识之前,我们很有可能会看到研究人员仍在努力尝试着不同的成本函数。
下图列出了一些常见 GAN 模型的成本函数。

表格改动自这里:
https://github.com/hwalsuklee/tensorflow-generative-model-collections
我们决定不在本文中详细介绍这些成本函数。实际上,如果您想了解更多信息,我们强烈建议您细致地阅读这些文章中的至少一篇:WGAN/WGAN-GP,EBGAN / BEGAN,LSGAN,RGAN 和 RaGAN 。 在本文的最后,我们还列出了一篇更详细地研究成本函数的文章。 成本函数是 GAN 的一个主要研究领域,我们鼓励您稍后阅读该文章。
以下是某些数据集中的一些 FID 分数(越低越好)。这是一个参考点,但需要注意的是,现在对于究竟哪些成本函数表现最佳下结论还为时尚早。 实际上,目前还没有哪一个成本函数在所有不同数据集中都具有最佳表现。
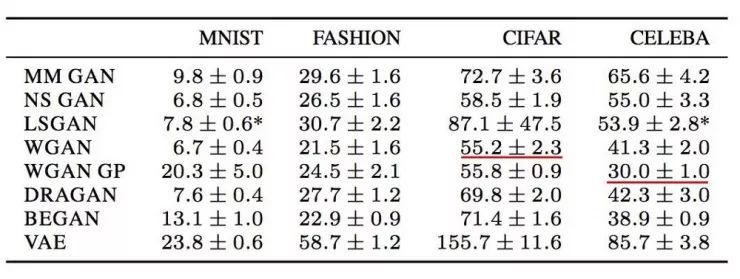
但缺乏好的超参数的模型不可能表现良好,而调参需要大量时间。所以在随机测试不同的成本函数之前,请耐心地优化超参数。
实现技巧
将图像的像素值转换到 -1 到 1 之间。在生成模型的最后一层使用 tanh 作为激活函数。
在实验中使用高斯分布对 z 取样。
Batch normalization 可以让训练结果更稳定。
上采样时使用 PixelShuffle 和反卷积。
下采样时不要使用最大池化而使用卷积步长。
Adam 优化通常比别的优化方法表现的更好。
图像交给判别模型之前添加一些噪声,不管是真实的图片还是生成的。
GAN 模型的动态特性尚未得到很好的解释。所以这些技巧只是建议,其优化结果如何可能存在差异。例如,提出 LSGAN 的文章指出 RMSProp 在他们的实验中表现更加稳定。这种情况非常稀少,但是也表明了提出普遍性的建议是非常困难的。
Virtual batch normalization (VBN)
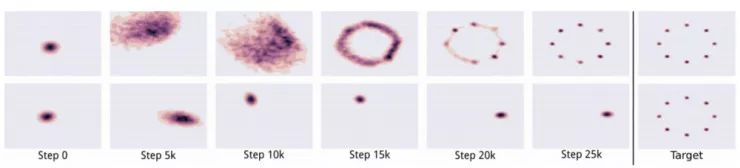
Batch normalization 已经成为很多深度神经网络设计中的事实标准。Batch normalization 的均值和方差来自当前的 minibatch 。然而,它会在样本之间创建依赖关系,导致生成的图像不是彼此独立的。
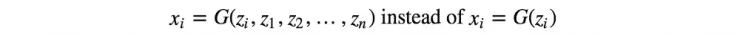
下图显示了在使用同一个 batch 的数据训练时,生成的图像有着相同的色调。

上排图像是橙色色调,第二排图像是绿色色调。 原文链接:https://arxiv.org/pdf/1701.00160v3.pdf
本来, 我们对噪声 z 是从随机分布中采样,为我们提供独立样本。然而,这种 batch normalization 造成的偏见却抵消了 z 的随机性。
Virtual batch normalization (VBN) 是在训练前从一个 reference batch 中采样。在前向传播中,我们提前选择一个 reference batch 为 batch normalization 去计算 normalization 的参数( μ 和 σ )。 然而,我们在整个训练过程中使用同一个 batch,会让模型过拟合。为了解决这个问题,我们将 reference batch 与当前 batch 相结合起来计算参数。
随机种子
用于初始化模型参数的随机种子会影响 GAN 的性能。 如下表所示,测量GAN性能的FID分数在50次独立运行(训练)中有所不同。但是波动的范围不大,并且可以在后续的微调中完成。
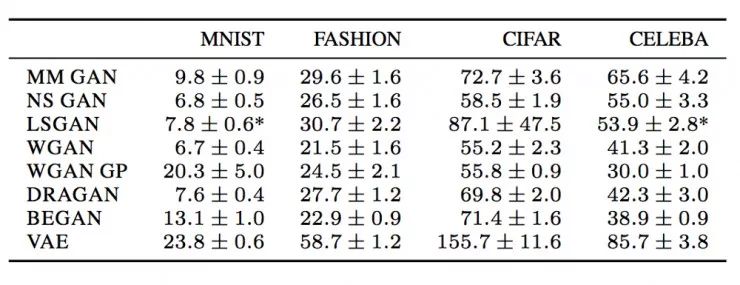
一篇来自 Google Brain 的论文指出 LSGAN 偶尔会在某些数据集中失败或崩溃,并且需要使用另一个随机种子重新启动训练。
Batch normalization
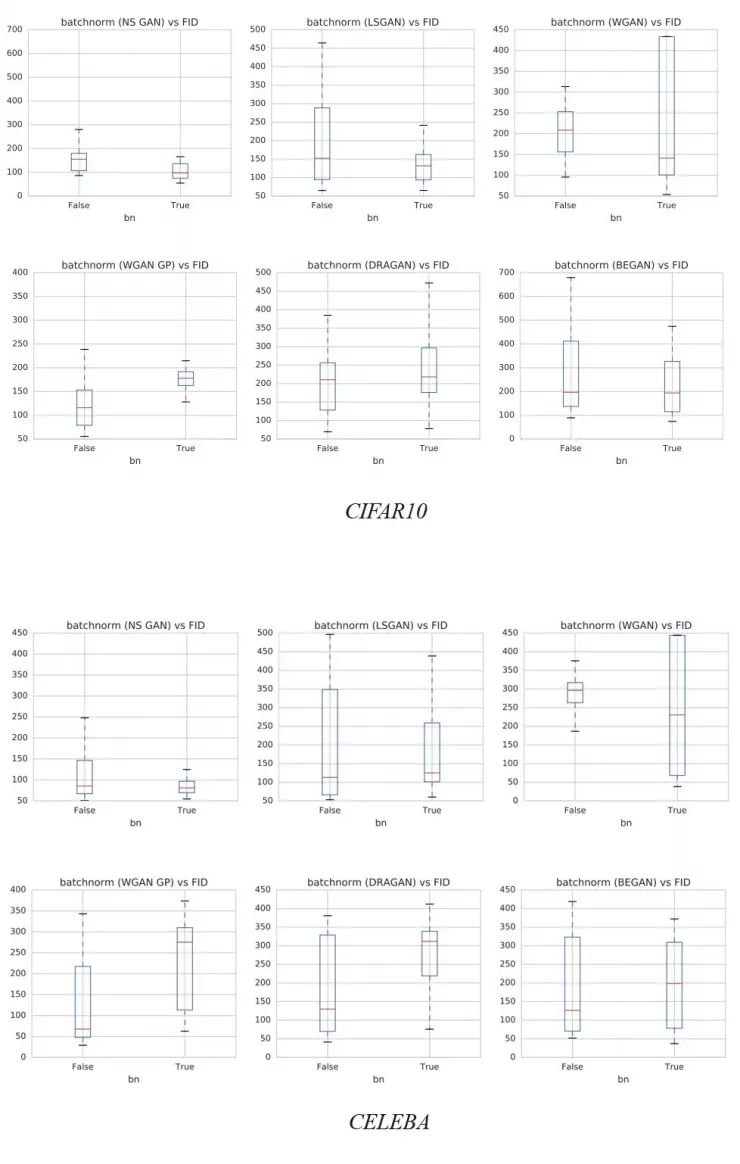
DGCAN 强力建议在网络设计中加入 batch normalization 。 Batch normalization 的使用也成为许多深度网络模型的一般做法。 但是,也会有例外。 下图演示了 batch normalization 对不同数据集的影响。 y 轴是 FID 得分,越低越好。 正如 WGAN-GP 论文所建议的那样,当使用成本函数 WGAN-GP 时,不应该使用 batch normalization 。 我们建议读者检查 batch normalization 上使用的成本函数和相应的FID性能,并通过实验验证来设置。
多重 GANs
模式崩溃可能并不全是坏事。 实际上,当模式崩溃时,图像质量通常会提高。 实际上,我们可以会为每种模式收集最佳模型,并使用它们来重建不同的图像模式。
判别模型和生成模型之间的平衡
判别模型和生成模型总是处于拉锯战中以相互削弱。生成模型积极创造最好的图像来击败判别模型。 但如果判别模型响应缓慢,生成的图像将收敛,模式开始崩溃。 相反,当判别模型表现良好时,原始生成模型的成本函数的梯度消失,学习速度慢。 我们可以将注意力转向平衡生成模型和判别模型之间的损失,以便在训练 GAN 中找到最佳位置。 不幸的是,解决方案似乎难以捉摸。 在判别模型和生成模型之间的交替梯度下降中,定义它们之间的静态比率似乎是有效的,但也有很多人怀疑它的效果。 如果说已经有人做过这件事的话,那就是研究人员每训练生成模型5次再更新判别模型的尝试了。 其他动态平衡两个网络的建议仅在最近才引起关注。
另一方面,一些研究人员认为平衡这些网络的可行性和愿景是很困难的。 训练有素的判别模型无论如何都能为生成模型提供高质量的反馈。 然而训练生成模型使之能与判断模型抗衡也并不容易。 相反,当生成模型表现不佳时,我们可能会将注意力转向寻找不具有接近零梯度的成本函数。
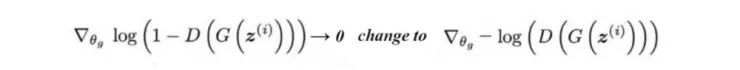
然而问题仍然是存在的。 人们提出了许多建议,研究者们对什么是最好的损失函数的争论仍在继续。
判别模型和生成模型的网络容量
判别模型通常比生成模型更复杂(有更多滤波器和更多层),而良好的判别模型可以提供高质量的信息。 在许多 GAN 应用中,当增加生成模型容量并没有带来质量上的改进时,我们便遇到了瓶颈。 在我们确定遭遇了瓶颈并解决这个问题之前,增加生成模型容量不会成为优先考虑的选项。
延伸阅读
在本文中,我们没有对损失函数的改进做进一步的说明。 这是一个重要的研究内容,我们建议读者点击下面的链接,对其有进一步的了解。
GAN — A comprehensive review into the gangsters of GANs (Part 2)
https://medium.com/@jonathan_hui/gan-a-comprehensive-review-into-the-gangsters-of-gans-part-2-73233a670d19
这篇文章介绍了改进 GAN 的动机和方向。在 medium.com 了解更多
一些 GAN 的酷酷的应用:
GAN — Some cool applications of GANs.
https://medium.com/@jonathan_hui/gan-some-cool-applications-of-gans-4c9ecca35900
我们在 GAN 开发的最初几年取得了不错的进展。 不会再有只有邮票这么小分辨率的面部图像……在 medium.com 了解更多
本系列所有文章:
GAN — GAN Series (from the beginning to the end)
https://medium.com/@jonathan_hui/gan-gan-series-2d279f906e7b
一个涵盖了 GAN 的应用、问题和解决方案的文章列表。
参考文献:
Improved Techniques for Training GANs
https://arxiv.org/pdf/1606.03498.pdf
原文链接:
https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b
号外号外~
一个专注于
AI技术发展和AI工程师成长的求知求职社区
诞生啦!
欢迎大家扫码体验


用Keras搭建GAN:图像去模糊中的应用(附代码)
▼▼▼