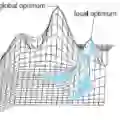
什么是学习率,以及它是如何影响深度学习的
编者按:当大家在训练神经网络时,相信不少人曾深受超参数困扰,学习率(Leraning Rate)、权值初始化(Weight Initialization)……这些数字深刻影响着神经网络的性能,却只能靠经验和实验来得出合适值。那么,学习率究竟是什么?它是怎么影响网络的呢?对于这个问题,澳大利亚最大招聘网站的数据科学家Hafidz Zulkifli近日给出了他的解答。

本文将主要关注以下几点:
什么是学习率?它有什么意义?
如何系统地获得合适的学习率?
为什么我们需要在训练期间改变学习率?
如何用预训练模型来处理学习率?
什么是学习率
学习率是一个重要的超参数,它控制着我们基于损失梯度调整神经网络权值的速度,大多数优化算法(如SGD、RMSprop、Adam)对它都有涉及。学习率越小,我们沿着损失梯度下降的速度越慢。从长远来看,这种谨慎慢行的选择可能还不错,因为可以避免错过任何局部最优解,但它也意味着我们要花更多时间来收敛,尤其是如果我们处于曲线的至高点。
以下等式显示了这种关系:
新权值 = 当前权值 - 学习率 × 梯度
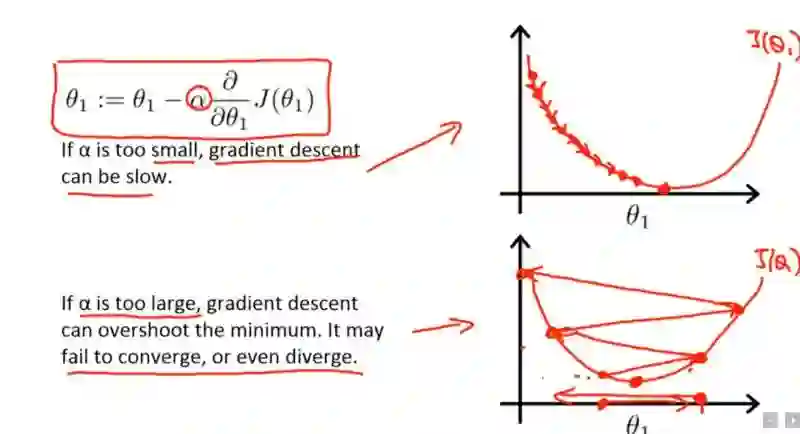
通常,学习率是用户自己随意设的,你可以根据过去的经验或书本资料选择一个最佳值,或凭直觉估计一个合适值。这样做可行,但并非永远可行。事实上选择学习率是一件比较困难的事,下图显示了应用不同学习率后出现的各类情况:
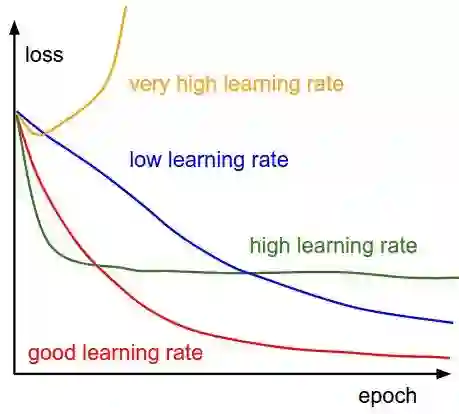
可以发现,学习率直接影响我们的模型能够以多快的速度收敛到局部最小值(也就是达到最好的精度)。一般来说,学习率越大,神经网络学习速度越快。如果学习率太小,网络很可能会陷入局部最优;但是如果太大,超过了极值,损失就会停止下降,在某一位置反复震荡。
也就是说,如果我们选择了一个合适的学习率,我们不仅可以在更短的时间内训练好模型,还可以节省各种云的花费。
有没有更好的方法来确定学习率?
Leslie N. Smith在Cyclical Learning Rates for Training Neural Networks的第3.3节中指出,如果你先设置一个较低的学习率,然后随着训练迭代逐渐增大这个值,最终你可以获得一个较好的学习率。
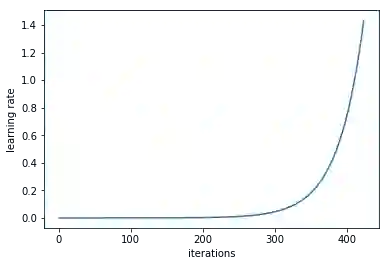
如果我们记录每次训练迭代,画出相应的学习率(对数)和loss变化,我们可以发现,随着学习率不断提高,loss会在一段时间不断下降,并在触及最低点后开始回升。在实践中,最理想的学习率应该是使loss曲线到达最低点的那个值,以下图为例,图中模型的最佳学习率在0.001到0.01之间。
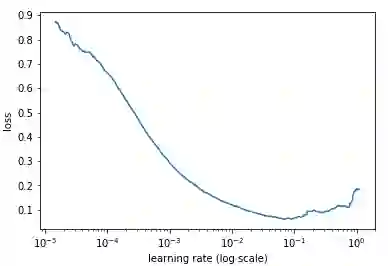
看起来很有道理,那么具体该怎么操作?
上述这种调试学习率的方法已经被封装进fast.ai包,你可以调用它的函数lr_find直接使用。
learn.lr_find()
learn.sched.plot_lr()
如何用学习率提高模型性能
现在我们已经知道了什么是学习率,那么当我们开始训练模型时,我们该如何用学习率来提高模型性能呢?
前人的智慧
通常情况下,当我们用设定好的学习率训练模型时,我们只能等它随着时间的推移慢慢下降,直到模型完成收敛。但是,如下图所示,很多时候随着梯度到达高值,模型的loss会变得很难收敛。对于这一点,Dauphin等人在他们的文章中指出,影响loss降低的主要因素是曲面鞍点,而不是局部最小值。因为如果模型如果陷入了一个“精心设计”的“山谷”,这时它过低的学习率无法产生,或者说是无法在短时间内产生足够的梯度来使模型越过这道“坎”。
因此定期提高学习率将有助于模型更好地收敛。
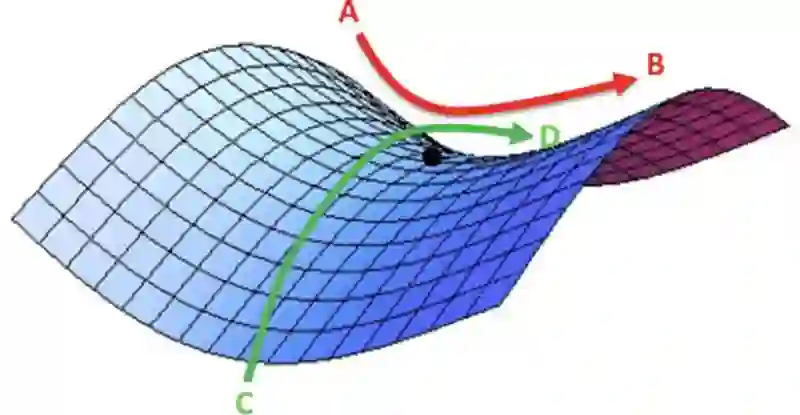
loss曲面上的鞍点,在这一点上函数的导数为0,但它并不是全局最优点
注:不少学习算法在训练过程中,随着误差的减少,迭代次数的增加,步长变化越来越小,训练误差越来越小直到变为零,局部探索到一个驻点,如果这个点是误差曲面的鞍点,即不是最大值也不是最小值的平滑曲面,那么一般结果表现为性能比较差;如果这个驻点是局部极小值,那么表现为性能较好,但不是全局最优值。目前大多数训练算法在碰到无论是鞍点还是局部极值点的时候,因为此刻学习率已经变得非常小,所以会陷入非全局最优值不能自拔。——张俊林
那么该怎么避免这种情况呢?
对于这个问题,一个可行的方法是在训练过程中使用“动态”的学习率,并让它随时间不断下降。
如果发现训练时模型的loss不再发生变化,我们可以视情况引入一些循环函数f,来改变每次迭代的学习率数值。由于每个周期的迭代次数都是固定的,这可以把学习率控制在合理范围内循环调试。如果刚好是卡在鞍点上,学习率的周期性提高可以让模型跳出当前局限,去“更远的地方”看一看。
Leslie Smith等人在2015年提出的Triangular循环学习率正是基于这种思想。它的做法是在每次迭代后从头开始调试学习率。
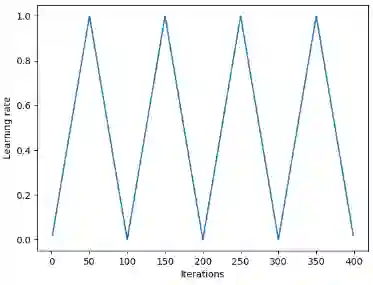
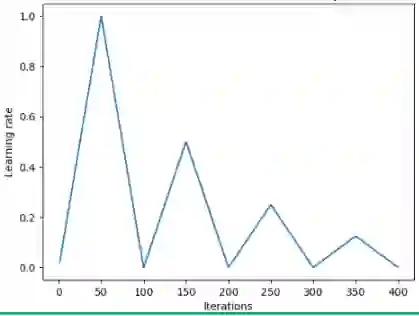
此外,另一种流行的方法是由Loshchilov和Hutter提出的加入了热重启(Warm Restart)的随机梯度下降。这种方法把余弦函数作为循环函数f,并在每一轮迭代开始时重设一个最大学习率。它的“热(warm)”表现在重设学习率时,它取的不是初始值,而是模型上次收敛时的参数。
下图是这一方法的可视化图像,它每轮迭代的学习率相同,但在实际操作中它可以有多种变化。
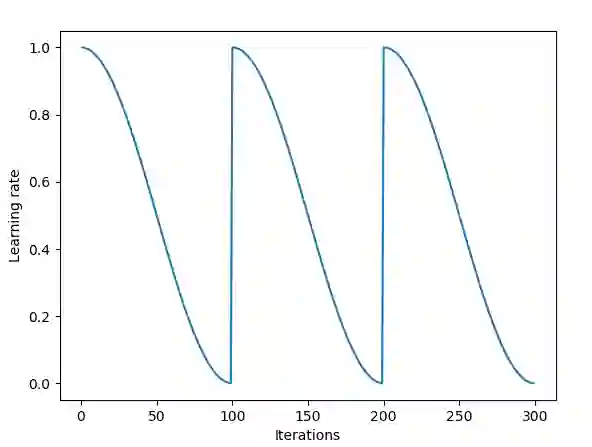
依靠这些方法,我们能周期性跳出loss曲面鞍点,这也意味着能减少训练时间。
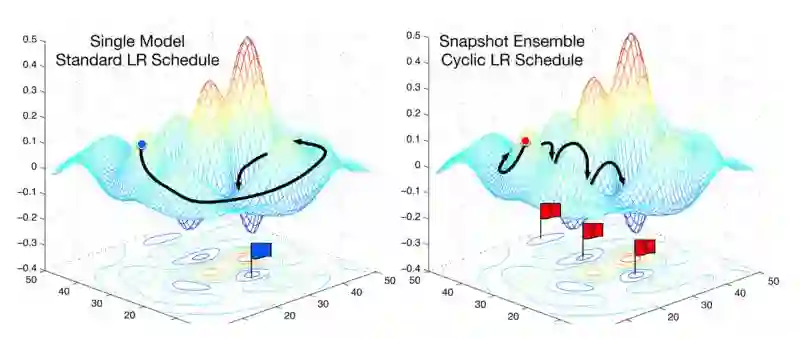
相关研究还表明,这些周期性调整学习率的方法还可以在不对模型做出调整的情况下提高分类准确率,并减少迭代次数。
迁移学习中的学习率
这里需要提到一个和deeplearning.ai齐名的深度学习热门课程fast.ai,如果说吴恩达专注于传播理论基础,那有深厚kaggle背景的fast.ai则更关注如何让你成为一名“老司机”。正是基于这个重视实践的定位,fast.ai特别强调预训练模型,假如你准备训练一个图像分类模型,那fast.ai的老师会强烈建议你用VGG或Resnet50等现成模型先在数据集上试试,再根据具体情况调整参数。
如果你想做一些fast.ai项目,以下是我归纳的基本步骤:
进行数据增强,precompute=True;
在loss保持下降时用
lr_find()找出最佳学习率;用precompute的值调整最后一层的参数,训练最后一层1-2个epoch;
设置cycle_len = 1,用增强后的数据(precompute=False)训练最后一层2–3个epoch;
把所有层设为可训练;
将前一层的学习率设为后一层的1/10-1/3;
再次调用
lr_find();设置cycle_mult=2,训练整个神经网络,直到它过拟合。
注:在fastai中,周期性提高学习率是通过设置learner.fit中的cyclelen和cyclemult参数来实现的。
可以发现,上述的步骤2、步骤5和步骤7都是关于学习率的。我们在上文中只介绍了步骤2的操作方法,即如何在训练模型前确定最佳学习率。因此在接下去的内容中,我们将把注意力放在如何用SGDR缩短训练时间、提高模型准确率上,即通过重新调整学习率避免梯度接近0。
其中最后一节会重点介绍差异性学习,谈谈训练模型和预训练模型相结合时它是怎么调整学习率的。
什么是差异性学习
差异性学习是指在训练期间为神经网络的不同层设置不同学习率的方法,它和一般做法不同,因为通常整个神经网络使用的是同一学习率。
在写这篇文章的时候,Jeremy 和Sebastian Ruder刚发了一篇论文Fine-tuned Language Models for Text Classification,深入探讨了差异性学习这个问题。如果你对NLP有所了解,那差异性学习一个更常规的名称是判別式微调(discriminative fine-tuning)。
为了更清楚地说明这个概念,我们可以看下方这张图,它把预训练模型分为红、蓝、绿三组,并赋予逐渐递增的学习率。
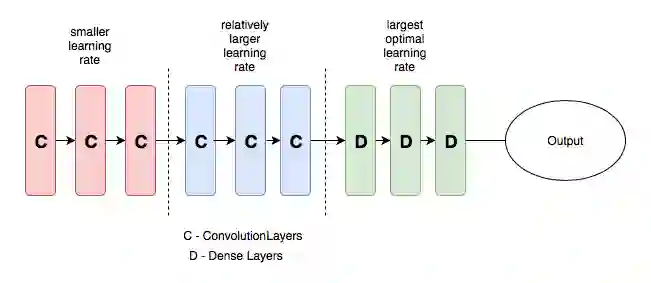
包含不同学习率的CNN
这样设置学习率的初衷是前几个层会包含大量非常细微的重要数据细节,如线条、边缘等,我们需要把它们原封不动的保留下来。而后面的层,如上图中的绿色区域,包含眼睛、鼻子、嘴巴等数据的详细特征,这些内容可有可无。
和其他微调方法的对比
有人认为微调这种方法代价过高,它可能会使一些CNN超过100层,效率太低。因此很多人会通过一层层微调来确定参数。但这样做也有缺点,首先你要保证调试顺序是正确的,其次这种割裂式做法影响了并行计算,最后由于要多次经过数据集,最后模型很可能会过拟合。
对于这个担忧,之前提到的这篇Fine-tuned Language Models for Text Classification已经提出了一种能在NLP任务中兼顾预测准确率和出错率的方法,具体可以查看论文自行掌握。
参考文献
[1] Improving the way we work with learning rate.
[2] The Cyclical Learning Rate technique.
[3] Transfer Learning using differential learning rates.
[4] Leslie N. Smith. Cyclical Learning Rates for Training Neural Networks.
[5] Estimating an Optimal Learning Rate for a Deep Neural Network
[6] Stochastic Gradient Descent with Warm Restarts
[7] Optimization for Deep Learning Highlights in 2017
[8] Lesson 1 Notebook, fast.ai Part 1 V2
[9] Fine-tuned Language Models for Text Classification
[10] 通过不断重置学习率来逃离局部极值点
原文地址:towardsdatascience.com/understanding-learning-rates-and-how-it-improves-performance-in-deep-learning-d0d4059c1c10