深度学习训练数据不平衡问题,怎么解决?

本文为雷锋字幕组编译的技术博客,原标题 Deep learning unbalanced training data ? Solve it like this,作者为 Shubrashankh Chatterjee 。
翻译 | 叶青 整理 | MY

当我们解决任何机器学习问题时,我们面临的最大问题之一是训练数据不平衡。不平衡数据的问题在于学术界对于相同的定义、含义和可能的解决方案存在分歧。我们将尝试用图像分类问题来解开训练数据中不平衡类别的奥秘。
不平衡类会有什么问题?
在一个分类问题中,如果在所有你想要预测的类别里有一个或者多个类别的样本量非常少,那你的数据也许就面临不平衡类别的问题。
举例
1.欺诈预测(欺诈的数量远远小于真实交易的数量)
2.自然灾害预测(不好的事情远远小于好的事情)
3.在图像分类中识别恶性肿瘤(训练样本中含有肿瘤的图像远比没有肿瘤的图像少)
为什么这是个问题呢?
不平衡类别会造成问题有两个主要原因:
1.对于不平衡类别,我们不能得到实时的最优结果,因为模型/算法从来没有充分地考察隐含类。
2.它对验证和测试样本的获取造成了一个问题,因为在一些类观测极少的情况下,很难在类中有代表性。
解决这个问题有哪些不同方法?
现在有三种主要建议的方法,它们各有利弊:
1.欠采样 - 随机删除观测数量足够多的类,使得两个类别间的相对比例是显著的。虽然这种方法使用起来非常简单,但很有可能被我们删除了的数据包含着预测类的重要信息。
2.过采样 - 对于不平衡的类别,我们使用拷贝现有样本的方法随机增加观测数量。理想情况下这种方法给了我们足够的样本数,但过采样可能导致过拟合训练数据。
3.合成采样( SMOTE )-该技术要求我们用合成方法得到不平衡类别的观测,该技术与现有的使用最近邻分类方法很类似。问题在于当一个类别的观测数量极度稀少时该怎么做。比如说,我们想用图片分类问题确定一个稀有物种,但我们可能只有一幅这个稀有物种的图片。
尽管每种方法都有各自的优点,但没有什么特定的启发式方法告诉我们什么时候使用哪种方法。我们现在将使用深度学习特定的图像分类问题详细研究这个问题。
图像分类中的不平衡类
在本节中,我们将选取一个图像分类问题,其中存在不平衡类问题,然后我们将使用一种简单有效的技术来解决它。
问题 - 我们在 kaggle 网站上选择「座头鲸识别挑战」,我们期望解决不平衡类别的挑战(理想情况下,所分类的鲸鱼数量少于未分类的鲸类,并且也有少数罕见鲸类我们有的图像数量更少。)
来自 kaggle :「在这场比赛中,你面临着建立一个算法来识别图像中的鲸鱼种类的挑战。您将分析 Happy Whale 数据库中的超过25,000张图像,这些数据来自研究机构和公共贡献者。 通过您的贡献,将会帮助打开有关全球海洋哺乳动物种群动态丰富的理解领域。」
我们来看看数据
由于这是一个多标签图像分类问题,我想首先检查数据在各个类别间的分布情况。
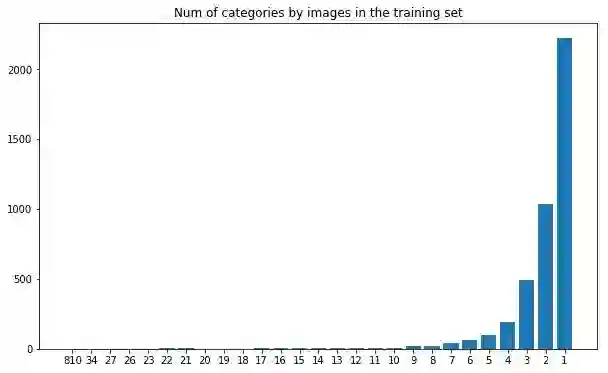
上面的图表表明,在4251个训练图片中,有超过2000个类别中只有一张图片。还有一些类中有2-5个图片。现在,这是一个严重的不平衡类问题。我们不能指望用每个类别的一张图片对深度学习模型进行训练(虽然有些算法可能正是用来做这个的,例如 one-shot 分类问题,但我们现在忽略先这一点)。这也会产生一个问题,即如何划分训练样本和验证样本。理想情况下,您会希望每个类都在训练和验证样本中有所体现。
我们现在应该做什么?
我们特别考虑了两个选项:
选项1 - 对训练样本进行严格的数据增强(我们可以做到这一点,但因为我们只需要针对特定类的数据增强,这可能无法完全达到我们的目的)。因此,我选择了看起来很简单的选项2。
选项2 - 类似于我上面提到的过采样选项。我仅仅使用不同的图像增强技术将不平衡类的图像在训练数据中复制了15次。这受到了杰里米·霍华德(Jeremy Howard )的启发,我猜他在一次深度学习讲座(fast.ai course 课程的第1部分)里提到过这一点。
在开始选项2之前,我们先看看训练样本中的一些图像。

特别的是,这些图像都是鲸鱼的尾巴。因此,识别很可能与特定的图片方向有关。
我也注意到在数据中有很多图像是黑白图片或只有R / B / G通道。
根据这些观察结果,我决定编写下面的代码,对训练样本中不平衡类的图像进行小幅改动并保存它们:

以上代码块对不平衡类(数量小于10)中的每个图像都进行如下处理:
1.将每张图片的 R、G、B 通道分别保存为增强副本
2.保存每张图片非锐化的增强副本
3.保存每张图片非锐化的增强副本
在上面的代码中可以看到,我们在这个练习中严格使用 pillow (一个 python 图像库)。
现在在每个不平衡类中都至少有了10个样本。我们继续进行训练。
图像增强 - 我们简单考虑这个问题。我们只想确保我们的模型能够获得鲸鱼尾的详细视图。为此,我们将变焦图包含到图像增强中。

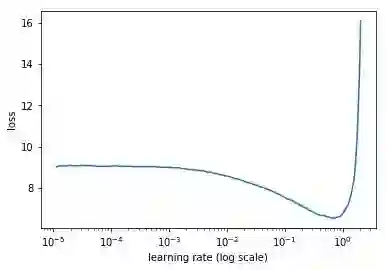
学习速率探测器 - 我们决定将学习率定为0.01,正如学习速率探测器所示。
我们用 Resnet50 模型进行了很少的迭代(先冻结模型,再解冻)。发现冻结的模型对于这个问题也非常有用,因为 imagenet 中有鲸鱼尾图像。
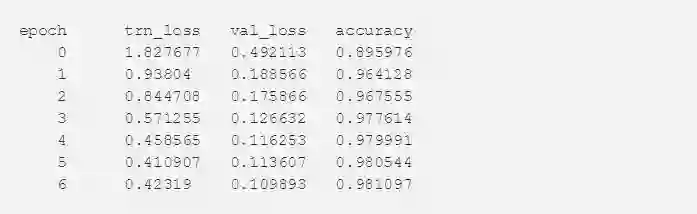
在测试数据上表现如何?
最终我们在 kaggle 排行榜上获得了真相。我们的提出的解决方案在本次比赛中排名34,前五的平均精确度为0.41928 :)
结论
有时,最简单的方法是最合理的(如果你没有更多的数据,只需稍加变化地拷贝现有的数据,假装对模型来说这一类别的大多数观测与它们基本类似)。它们最有效并且可以更容易和直观地完成工作。
原文链接:https://medium.com/@shub777_56374/deep-learning-unbalanced-training-data-solve-it-like-this-6c528e9efea6

为什么你需要改进训练数据,如何改进?
▼▼▼


