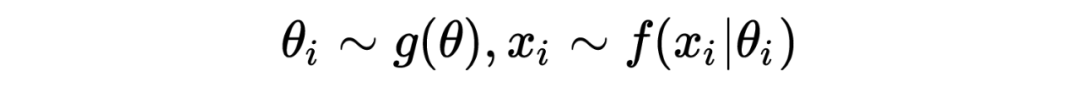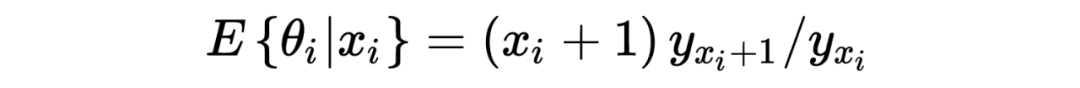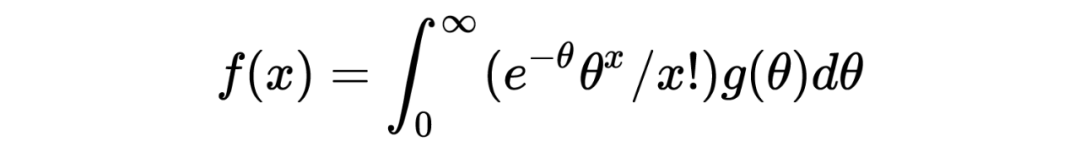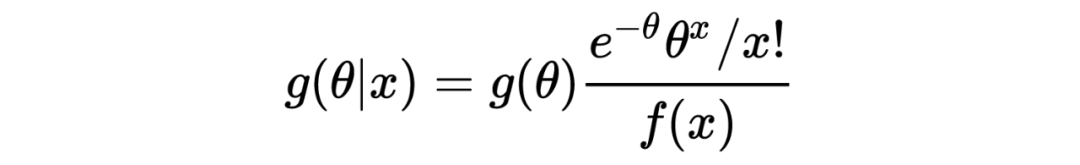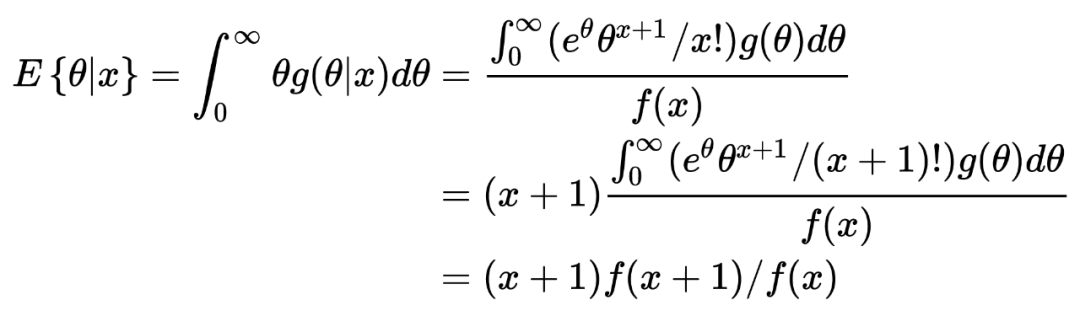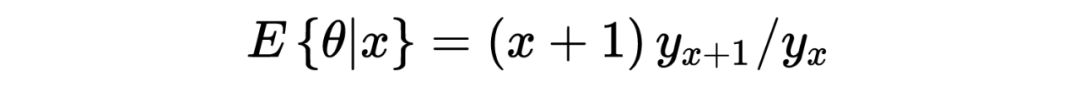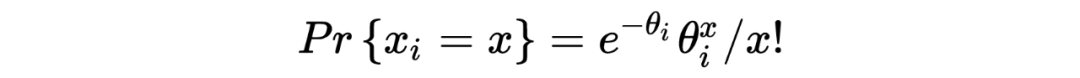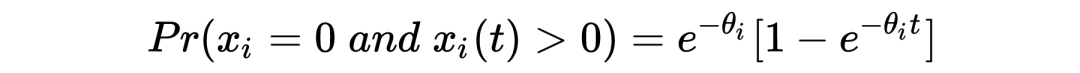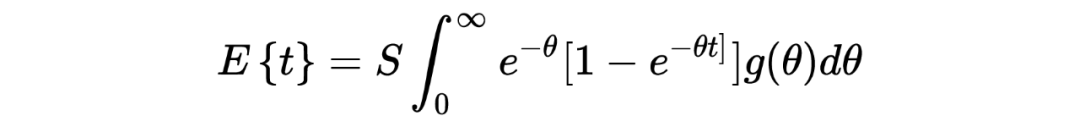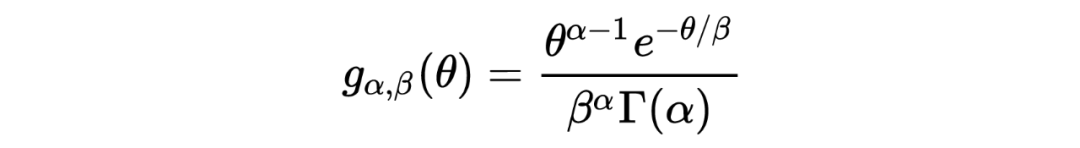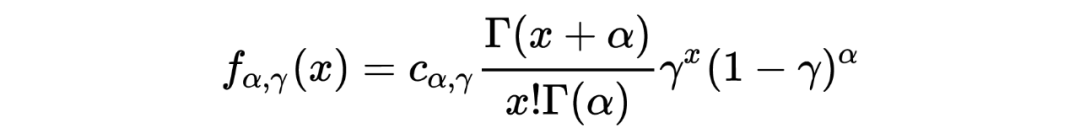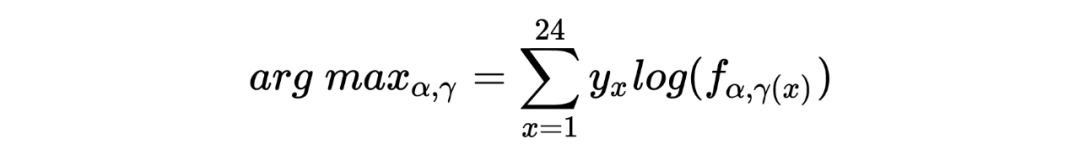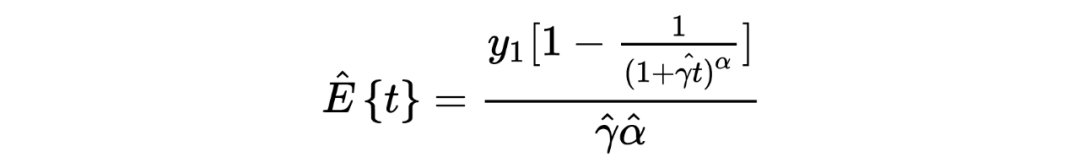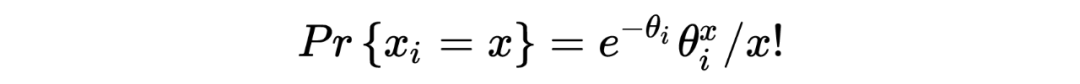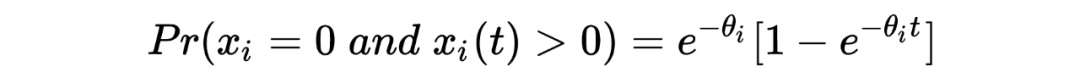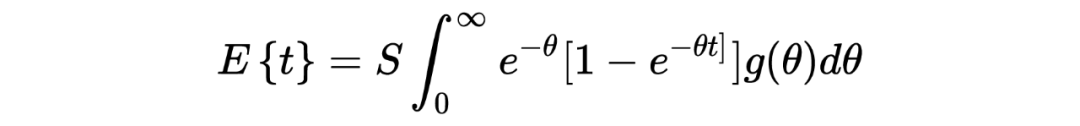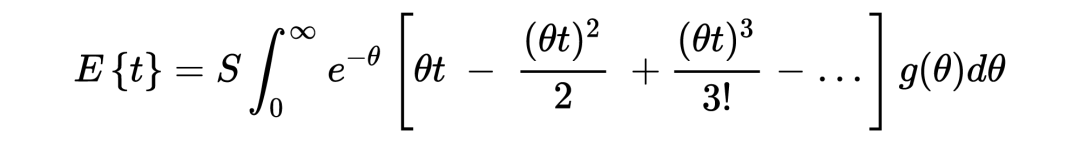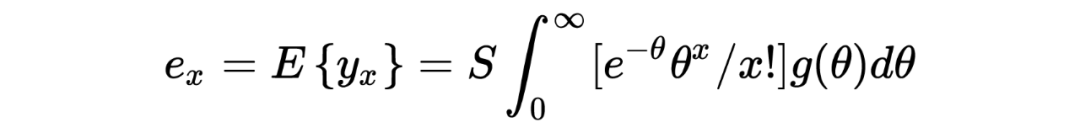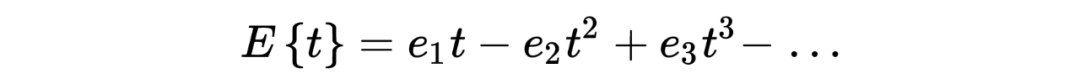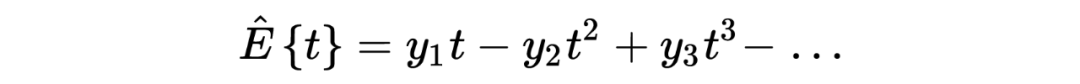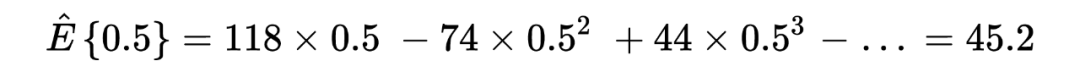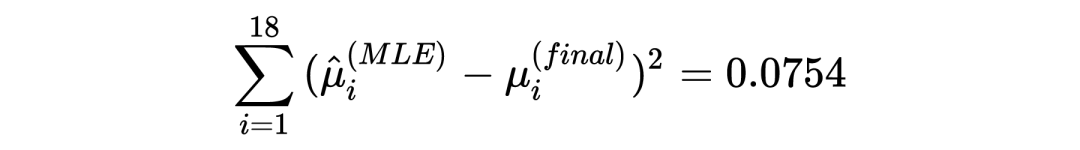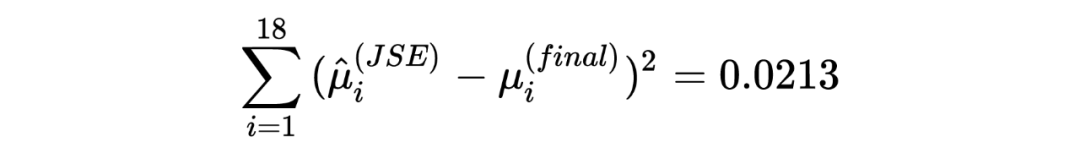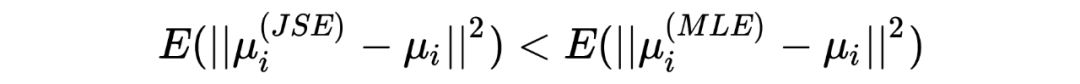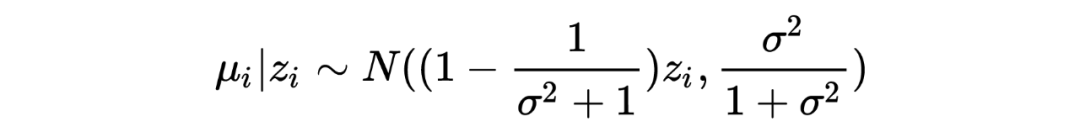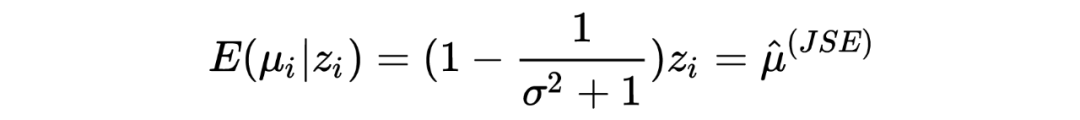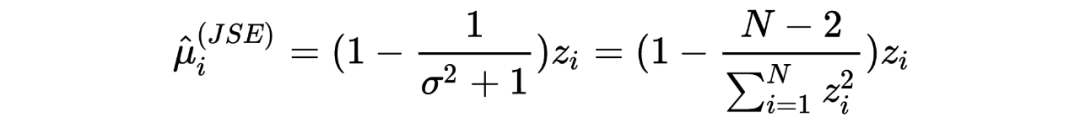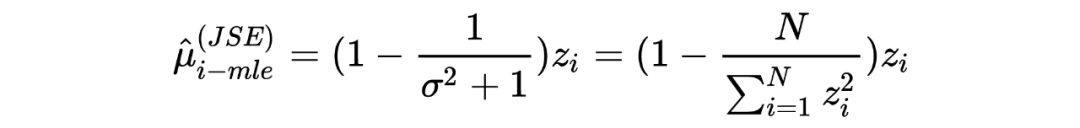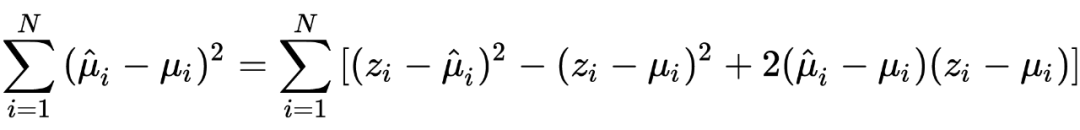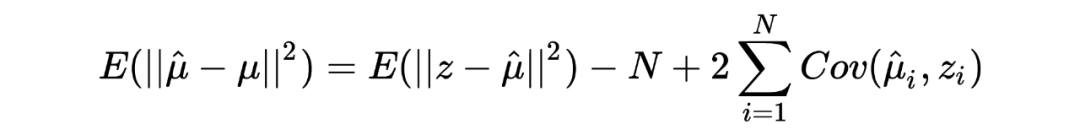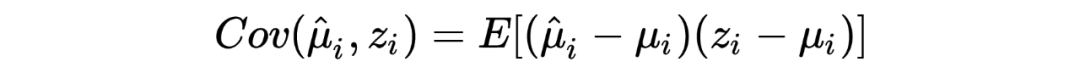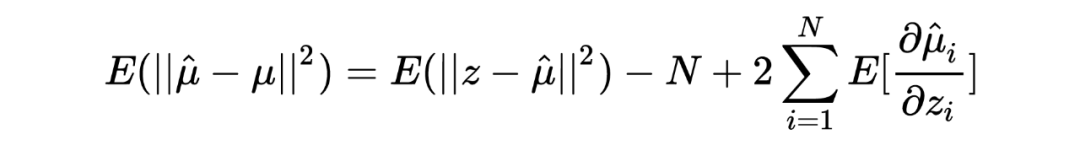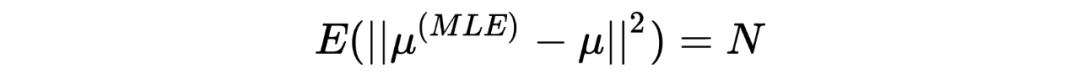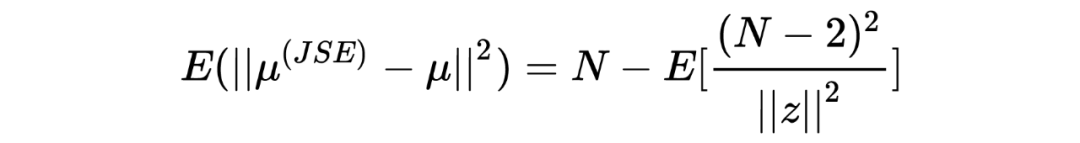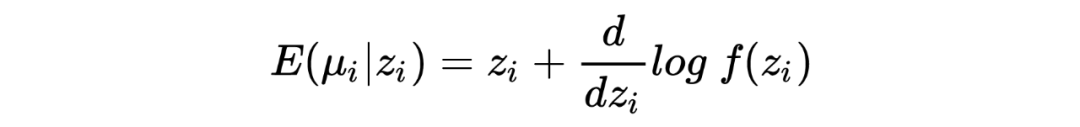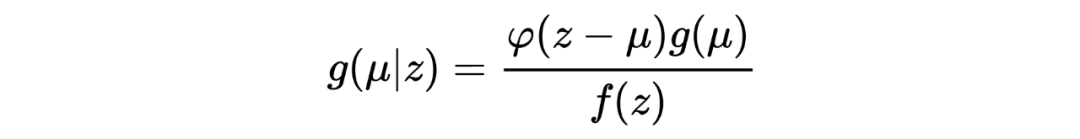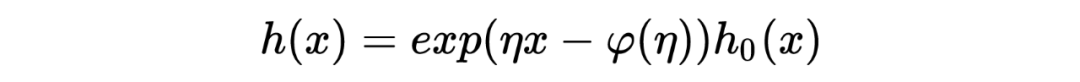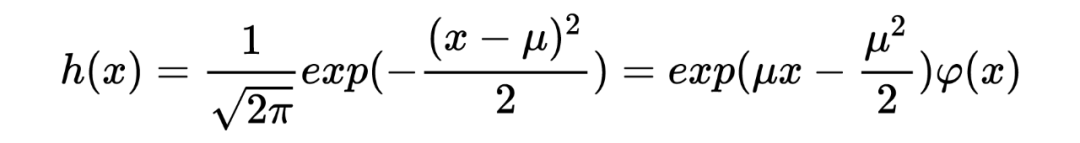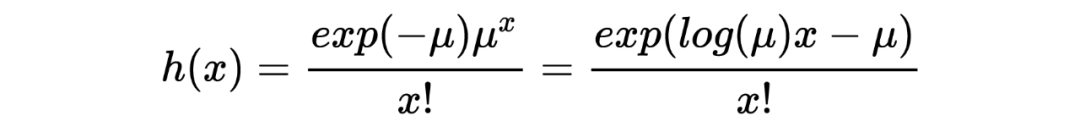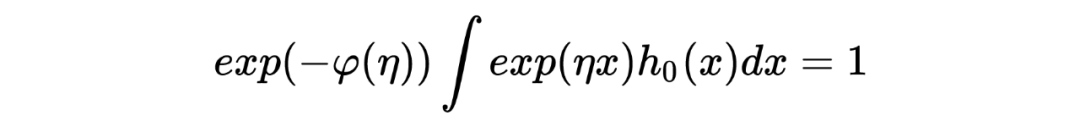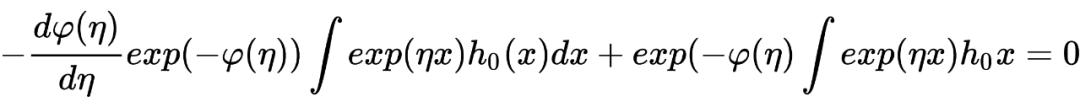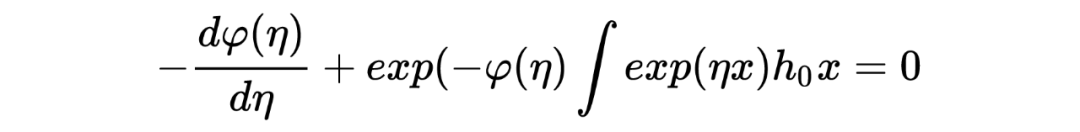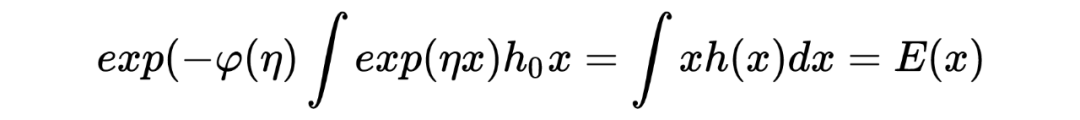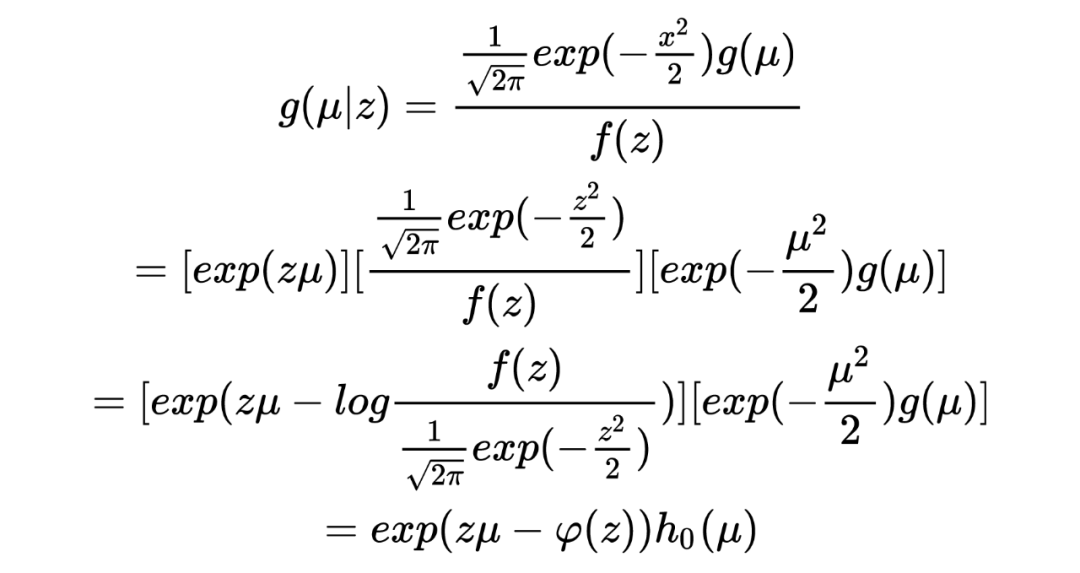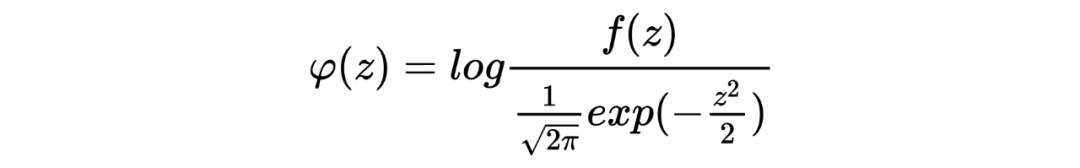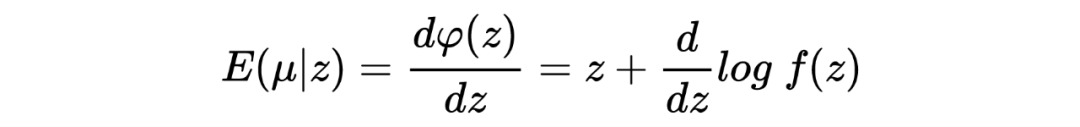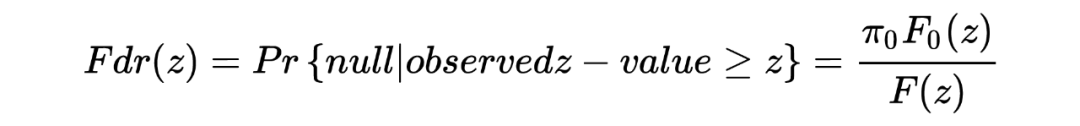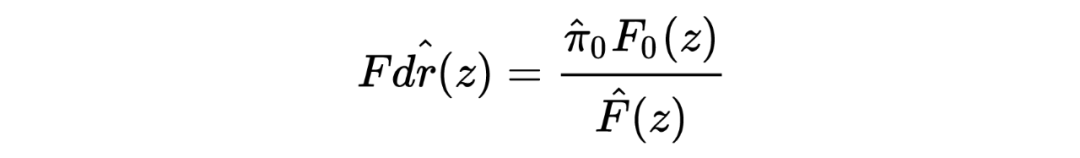在传统的贝叶斯方法中,我们在获取到任何观测数据之前就已经有了确定的先验分布,然后利用观测数据对先验分布进行修正得到后验概率。举个很简单的例子:我在乘坐飞机之前就知道飞机失事的概率非常小,这个概率在我乘坐飞机之前就已经在我心里了;但如果观察到最近国际局势紧张(观测数据),此时我所乘坐的飞机失事的概率(经过修正后的后验概率)可能就会增加。 与此不同的是,经验贝叶斯方法中先验分布并不提前给出,而是从获得的观测数据中去估计,这恰好印证了其命名中的“经验”二字。 在统计推断中,经验贝叶斯方法是非常重要的工具之一,能够帮助我们在缺乏先验分布的情况下做出推断,有时有些场景下的推断甚至性能很不错。在过去的研究中,已经有众多令人称奇的故事和结果出现在我们的视野里,在这里我打算分享一些关于经验贝叶斯的理解。 本文第一部分主要分享经验贝叶斯出现、发展历程中的一个重要节点:Robbins' formula,它证明简单,但意义重大。后面两部分将分享关于 the missing species problems 以及 James-Stein estimator 的相关内容。
1.2 Robbins’formula
Robbins, H. (1956). An empirical Bayes approach to statistics. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, 1954–1955, Vol. I, Berkeley and Los Angeles, pp. 157–163. University of California Press.
1. 在以上这个汽车保险公司的例子中:在没有任何先验分布/信息的情况下,简单的一行数据()中就提供了所有用于估计一个贝叶斯统计值()的信息。某种意义上来说,这种不依赖先验分布/信息的估计是完完全全的频率学派的估计方法,这也恰恰印证了这种方法的大名:经验贝叶斯。不管怎样,任它频率学派还是贝叶斯学派,事实上 Robbins' formula 就是在没有贝叶斯信息(先验分布)的情况下得到了一个贝叶斯的结果。这也给了后续的研究一个革命性的启发:一个足够大的数据集中隐含了其本身的先验分布。
3. 从本质上来说,Robbins's formula 是一个非参数式的方法:它并不依赖任何参数式形式的先验分布。事实上在上文推导过程中,我们也从未去估计这个先验分布 。
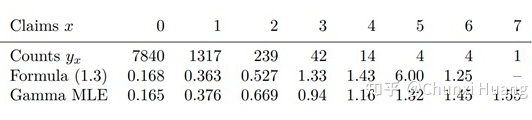
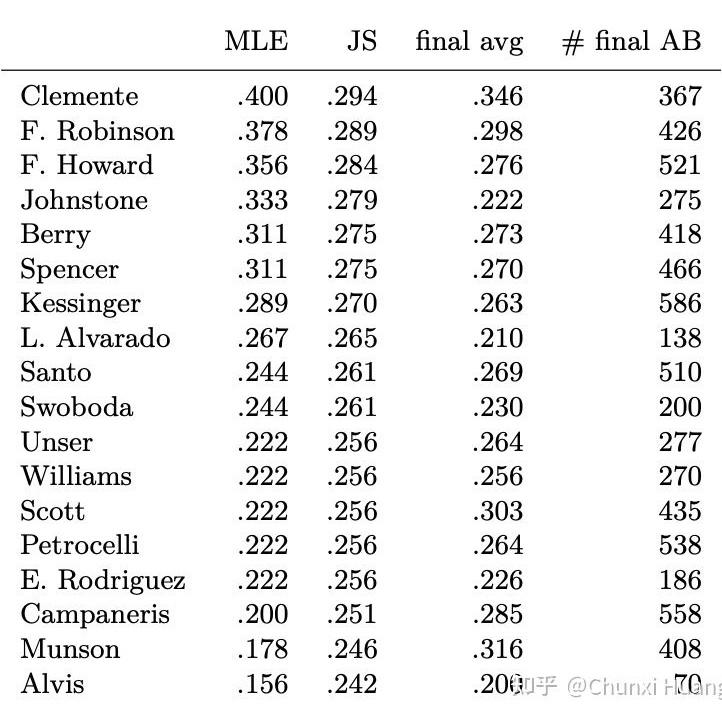
4. 有一点需要注意的是,在上文汽车保险公司例子的表中,第三行所示为利用 Robbins' formula 得出的估计结果,我们发现当 的值变小的时候(表的右侧),这种估计好像出问题了。个人认为这与数据分布本身有关,毕竟从概念上来说,经验贝叶斯的先验分布来源于观测数据本身。而与之相反的则是表中第四行假设先验分布 为 gamma 分布得出的估计值,相较之下更为稳定。
2.1 前言
上一章节我介绍了关于 Robbins‘ formula 的相关内容。很明显,所谓的经验贝叶斯实际上还是在贝叶斯框架下做事,唯一的区别就在于先验分布的给出上:传统的贝叶斯方法直接给出了明确的先验,而经验贝叶斯则依靠观测数据来估计先验分布、进而实现贝叶斯推理。 虽然 Robbins 正式命名了经验贝叶斯方法、并将其概念阐述得很清楚,但实际上,在 Robbins 之前的一篇更早的论文可以视为经验贝叶斯的里程碑。
Fisher, R., A. Corbet, and C. Williams (1943). The relation between the number of species and the number of individuals in a random sample of an animal population. J. Anim. Ecol. 12, 42–58.
这就是本文即将讲述的有关经验贝叶斯的另一个成功故事:the missing species problem。此外,我将以过去的研究为例,简单介绍经验贝叶斯框架下的两种方法:f-modeling 和 g-modeling。 在接下来的第三篇文章,我将继续讲述关于经验贝叶斯的另一个故事:James-Stein estimator。
2.2 The missing species problem
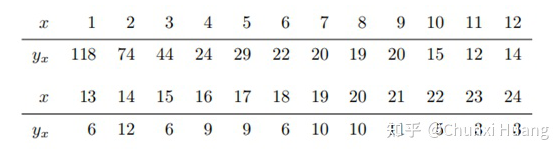
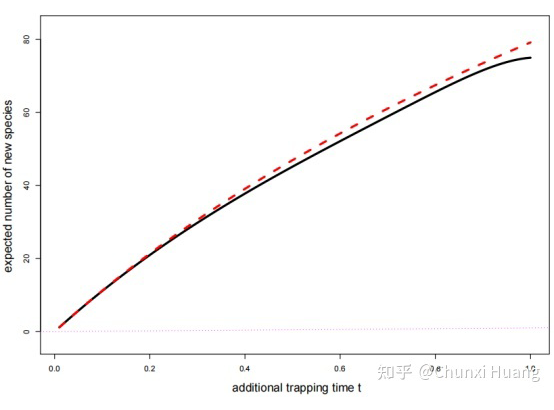
回到问题本身,the missing species problem 主要考虑的场景如下: Corbet 是一个自然学家,他曾经花了两年时间在马来西亚捕获蝴蝶物种标本。以下表格是他所收集到的部分实验数据:其中 代表的是捕获到某种类蝴蝶的次数, 所代表的是捕获次数为 的蝴蝶的种类数。
James, W. and C. Stein (1961). Estimation with quadratic loss. In Proc. 4th Berkeley Sympos. Math. Statist. Prob., Vol. I, pp. 361–379. Berkeley: University of California Press.
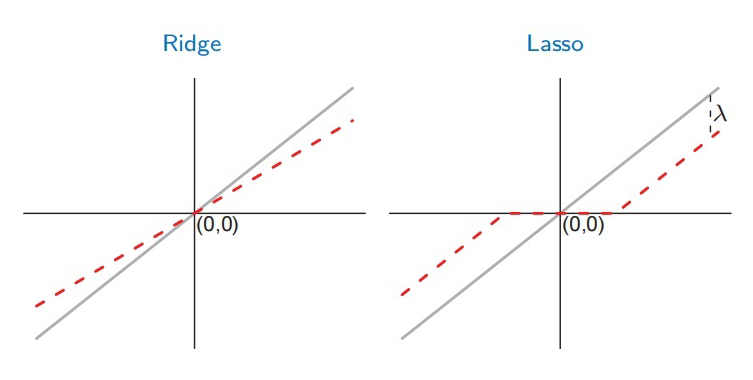
提到 shrinkage,不免会想到 Lasso 和 Ridge,实际上,James-Stein estimator 在某种程度上在实行统计推断时具有某种隐含的正则化的作用。 在以上三个章节中,我分别分享了 Robbins's formula、the missing species problem 以及 James-Stein estimator,其中经验贝叶斯的理念一直贯穿其中:假设一个先验,并用观测数据去估计这个先验(中的参数)。然而,这三个故事中,使用的先验分布涉及到了泊松分布、正态分布等不同的分布,不由得会使人好奇:如果假设别的先验,经验贝叶斯还会 work 吗?答案当然是肯定的,事实上我在以上三个章节中分享的只是皮毛,Tweedie's formula 会给我们一个更 general 的答案。此外,如果在相同推断场景对 James-Stein estimator 和 Tweedie's formula 进行对比的话,它们的 shrinkage 行为与 Lasso 和 Ridge 有着惊人的相似。如果有伙伴感兴趣的话下次抽空再跟大家一起探讨。
4.1 前言
上面分别介绍了几个经验贝叶斯发展历程中的重要节点,包括 Robbins' formula、The missing species problem、James-Stein estimator 等。在经验贝叶斯方法发展的初期,Robbins、Fisher 等大佬在先验上用泊松分布用的比较多,后面 James-Stein estimator 又往经验贝叶斯的先验池子里加入了正态分布,然而这些还远远不够。 对于贝叶斯相关的方法,有一个经久不衰的疑问:为什么用这个先验?用其他先验行不行? 针对这个问题,在经验贝叶斯的框架中 Tweedie's formula 就在一定的推断场景下给出了更普遍的结果:不对先验的形式做限制,只要有就行。本文将主要介绍 Tweedie's formula 的推断场景、其利用 exponential family 及 cumulant generating function 的推导过程以及其与我们熟知的 Ridge regression、Lasso 之间的联系。
4.2 Tweedie's formula
考虑 James-Stein estimator 中的推断场景:
,,我们希望从观测值 中估计 。 在推导 James-Stein estimato 的过程中,我们假设了先验是正态分布: ,在利用观测数据估计了其中的参数 后最终写出了 的后验分布并用其期望作为估计值。 然而在 Tweedie's formula 中,不对先验的形式做特殊要求,只假设其存在:,目标同样是求 后验分布的期望。Tweedie's formula 给出的后验分布的期望为:
其中 是 的边缘分布。 很明显,Tweedie's formula 给出的估计中第一项就是 MLE 的估计,而第二项可以被视为经验贝叶斯在 MLE 估计的基础上做的贝叶斯修正。 我第一次看见这个结论的时候,除了 amazing 没有别的词可以形容了。这个公式意味着:在当前考虑的推断场景下,不对先验做形式上的要求,只要其存在,我们就可以求出后验分布的期望,是不是很神奇? Tweedie's formula 到底是怎么得到的呢?
4.3 Tweedie's formula的推导
在推导 Tweedie's formula 之前,需要强调的是 Tweedie's formula 给出的答案是后验分布的期望,这与获得整个后验分布是完全不同的两码事,两者的区别有点像我们常说的判别模型和生成模型之间的区别。 以下进入 Tweedie's formula 的推导: 首先我们有 ,。 由此可以写出 的边际分布为:,其中 为标准正态分布的概率密度函数。根据贝叶斯公式我们可以得到 的后验分布可写为:
在此处,先验分布 形式不清楚的情况下,我们无法给出后验分布的解析形式。但此处我们的目标是后验分布的期望,可以通过 exponential family 及其中的 cumulant generating function 巧妙地推导而来。 对于 exponential family 中的分布而言,其概率密度函数可以写成以下形式:
由此,我们得到了关于 cumulant generating function 的一条重要性质:。 回顾我们的目标:后验分布的期望。从上式显然期望已经出现在我们的视野中,剩下的就是将后验分布写成 exponential family 的形式,找到 cumulant generating function 求导即可。 以下为根据后验分布找出 cumulant generating function 的过程:
在上式中, 可以被视为 natural parameter,cumulant generating function 则为:
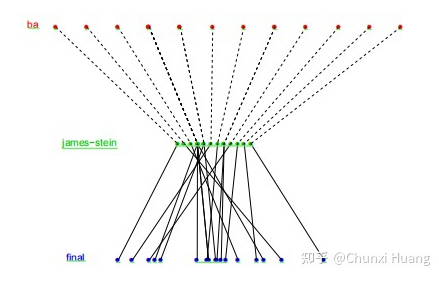
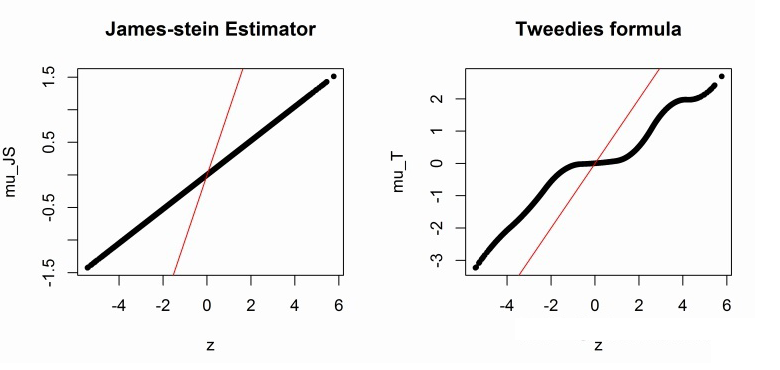
而经验贝叶斯中的两个重要节点:之前所提到 James-Stein estimator 的和本文分享的 Tweedie's formula 则惊奇地有与 Ridge 和 Tweedie's formula 相似的效果。如下图所示,黑色为 JSE 和 Tweedie's formua 的估计值,红色线为 。
这联系多美!
4.5 总结
相较之前的几种方法对先验形式的要求,Tweedie's formula 算是在普适性上一定程度的进步。但这种普适性仍然是有条件的,在推导过程中,不难发现,exponential family 的 cumulant generating function 扮演了很重要的角色。换句话说,想要使用 Tweedie's formula,需要先看看推断目标的分布(本章节中为 的后验分布)能否被写成 exponential family 的形式。尽管有这样的限制,这丝毫不影响 Tweedie's formula 成为经验贝叶斯历史上浓墨重彩的一笔。
Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological),57(1), 289-300.
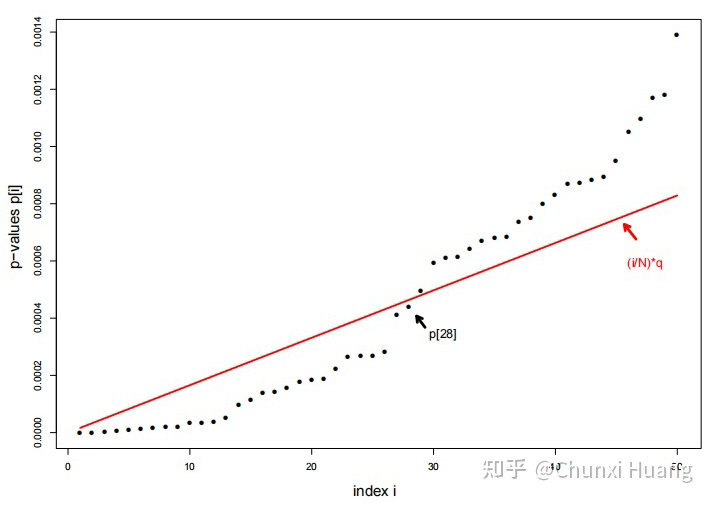
以传统的假设检验为例,设传统假设检验中有 M 个 null hypothesis,一般来说 M 的值通常较小,如:M<20。然而在现代的各种丰富的高维数据场景下,大规模假设检验变成了必须要解决的一个问题。与传统假设检验不同的是,大规模假设检验通常 M 的值较大,如在许多生物信息学的研究中涉及基因组相关的假设检验 M 的值动辄可达几十万乃至上百万。 与小规模的假设检验相比,大规模假设检验的主要问题就在于:如何增加 statistical power (如减少 false negative)?如何控制第一类误差(false postive)?false positive rates 是统计和统计学习中很基础的概念,可以简单写为 ,其也被称为 type I errr。与之相对应的概念则是 false negative rates,也被称为 type II error。 假设我们有 M 个相互独立的测试,每一个测试都提供了一个反对它的 null hypothesis 的 p 值 ,这样一来 M 个 p 值就组成了一个向量 。令 作为一个以 为输入、以接受或拒绝 null hypothesis 的决策为输出的规则。假设我们观察到该规则拒绝了 M 个测试中的 R 个,那么 false discovery proportion(Fdp)可以定义为: ,其中 是 个拒绝的测试中 null hypothesis 实际是正确的数量,换句话说,也就是 false discoveries 的数量。 基于此,规则 的 false discovery rate 就被定义为 Fdp 的期望值,写成:,当然, 时 Fdp 的值则为 0。 上面提到,我们希望在大规模假设检验中控制 false positive,可怎样的方法能够控制呢?乍一看会觉得没头绪,Benjamini 和 Hochberg 给出他们的经典答案:BH procedures。