漫谈统计学习:关于基础概念那些事

©作者 | 黄春喜
单位 | 香港科技大学
研究方向 | 智能交通
01.
前言
之前在硕士阶段,统计学习(SL)既不是我的研究方向、也不是我的研究工具,所以了解甚少。之前我与 SL 唯一的接触停留在非常走马观花的读过一遍 ISLR 那本书,积累的技能仅限于在 R 里调包来 fit 简单的 model。简单来说就是了解的东西连皮毛都算不上,更不用提个中细致的推导以及背后严谨的数学了。
目前的学习和研究中,我导本身对统计学习要求很高,关键是她自己也很强,搞得我压力山大一直在狂补基础。开学一月有余,最近正好在上 Prof. Yang Can 的一门统计推断相关的课,刷新了我对统计学习的认知,他讲故事的能力极强,能用一幅 big picture 把各种我听过的没听过的方法互相联系起来(当然这也源于他的深厚功力),个人也对他写的统计学习相关的博客十分着迷。最近在重读 ISLR+ESL,想记录一下进展,深知目前水平有限,写此文只为分享自己关于某些概念的理解,供读者一乐。
本文主要谈一谈我自己关于一些基础概念的理解和解读,包括但不限于统计学习中的预测和推断、模型精度与模型可解释性、bias-variance trade-off 等内容。大佬请略过直接拉到末尾有好文推荐可享用。
02.
什么是统计学习?
在我们的日常生活、生产中,有众多的数据存在着、流动着,数据和数据之间也有着各种各样的联系。很多时候,基于已观测到的数据,我们好奇其中的联系,想要找到其中隐含的经验和知识来帮助我们对现有的系统进行优化、或是对未来的不可见数据做预测和推断。统计学习做的就是这么一件事:基于数据构建模型并且用模型对数据进行预测和分析。
举个很简单的例子,根据长期的观察,人们发现子女和父母的身高之间存在一定的定性关系。统计学家利用收集到的数据进行统计学习建模,学习出的模型就能够根据父母身高及其他因素(家庭孩子数量、孩子的性别)等对未出生的子女的身高进行预测。两个世纪以前,法国的科学家 Galton 做的就是这么一件事,他发现了 1.08 这个奇妙的数字,也发现了男孩比女孩平均要高一些。两百年多年过去了,他给我们留下了一个名为 Galton Family 的古老的数据集,至今仍是很好玩的 toy set。感兴趣的伙伴可以去 fit 一个任意模型看看你能达到的最小 MSE 是多少哈哈(settings:利用其它变量预测 child height,train-734,test-200,reps-200)。
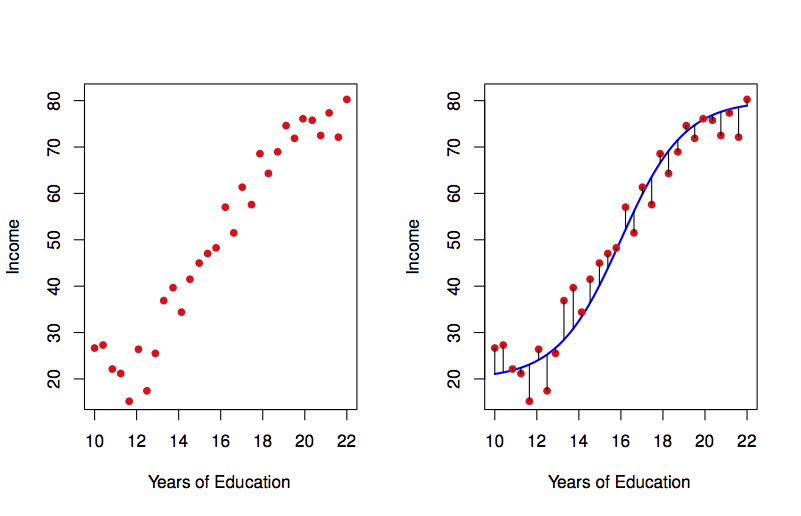
下图是另一个例子,左图是受教育年限与收入的样本数据,根据此数据可以构建右图中蓝线所示的统计学习模型,该模型可以用于预测某个受教育年限的样本其收入情况如何。
03.
统计学习模型:
预测和推断
上文提到,统计学习中通常要基于数据进行建模来实现预测和推断。实际上,针对未来数据所做的预测和推断就是我们构建模型最初的动力和目标。这里有必要区分一下预测(prediction)和推断(inference)。
预测是指我们给所构建的模型一定的输入,利用模型对输出进行预测。这在很多时候代表着未知场景下对关键指标的估计,比如根据候选人的学历、工作经营等因素预测其薪资时,我们更好奇某个条件(如硕士学历、3 年工作经验)的候选人能拿到的薪资数额是多少?不难发现,在预测中我们对输出更感兴趣。
而推断则与预测不同,简单来说,当我们的目的是推断时,我们对输入和输出之间的关系(而不是输出)更为感兴趣,我们更好奇哪个输入对输出的有什么样的影响?同样的例子,当我们的任务是推断时,我们要解决的问题很可能就是学历对薪资的影响有多大?或是学历和工作经验到底哪一个对薪资的影响更大?
04.
如何构建学习模型?
要想实现预测和推断,构建统计学习模型是第一步。大致来分的话,构建统计学习模型的方法可以分为两种:参数式方法和非参数式方法。
参数式方法比较直接,可以分为两步。第一步先对模型的形式做一个假设,比如最简单的模型假设就可以说它是线性的。选择完模型假设后,我们对模型有一个较为准确的认知了,此时的模型中只剩下众多未知的参数。所以第二步就是利用已有的数据对模型中的参数进行估计。很容易看出,参数式方法把寻找一个未知模型(函数)的问题通过预先假设模型形式的方法转变成了根据数据估计一堆参数的问题,这是一个化繁为简的过程,其代价就是对模型形式进行了限制。
而非参数式的方法则对模型的形式没有具体的假设,这使得它理论上可以构建任何能最接近训练集的模型。
通过上面的简单解释,不难发现为什么它们拥有这样的命名。此外,参数式方法和非参数式方法的优缺点也一览无余:参数式方法将构建模型的问题简单化,然而却面临模型假设与数据背后未知的真实模型相差甚远的风险,所以对于参数式方法来说,如果模型假设提的好,效果自然好,构建起来也轻松一些,但如果模型假设不那么好甚至相差很远,就是完完全全的灾难。非参数式方法的优势则在于其理论上可以根据数据拟合任何种类的模型(能够最大程度的贴近数据),而其劣势则是需要更大量的数据(相较参数式方法而言)来构建一个准确的模型。
通过不同的方法,我们可以构建很多不同的模型。可为什么要有这么多不同的统计学习方法/模型呢?没有一个最高级、最 fancy 的模型一劳永逸的解决所有问题吗?确实没有,no free lunch 说的就是这么个事,没有一个最好的模型可以在任何问题上优于其他模型,模型好不好都是 problem-dependent 的。换句话说,抛开具体问题谈哪个模型更好是没有一点意义的。
05.
预测精度 v.s. 模型可解释性
如在众多的统计学习方法中,不同的方法有着不同的特点,有些方法灵活性/弹性(flexibility)较差(约束较多),只能够构建有限的模型集合来拟合数据,如线性模型。有些方法 flexibility 则较好,能够构建更多的模型来拟合数据。
说到这不禁会有疑问,这样说来 flexibility 更好的方法不是我们的最佳选择吗?为什么还需要那些 flexibility 较差的方法呢?实际上,这里有一个很重要的 trade-off,那就是模型的预测精度与模型的可解释性。通常来说,以线性模型为代表的 flexibity 较差的模型,虽然它们能够构建的模型范围有限,导致其可能捕捉不到一些数据里的信息、造成预测精度较低,但是它们通常有着较为清晰的模型形式,比如线性模型可以将输出 Y 表示为输入 X 的线性组合,我们就可以清晰的分析出哪些变量会影响输出,这样的模型可解释性就非常高。
相反地,有些 flexibility 较好的方法,其试图利用更复杂的模型去拟合、贴近数据,预测精度上就会较高,但受限于更复杂的模型形式,我们很难清晰的解释清楚输入与输出之间的关系。下图即为众多方法的 flexibility 与模型可解释性之间的关系:
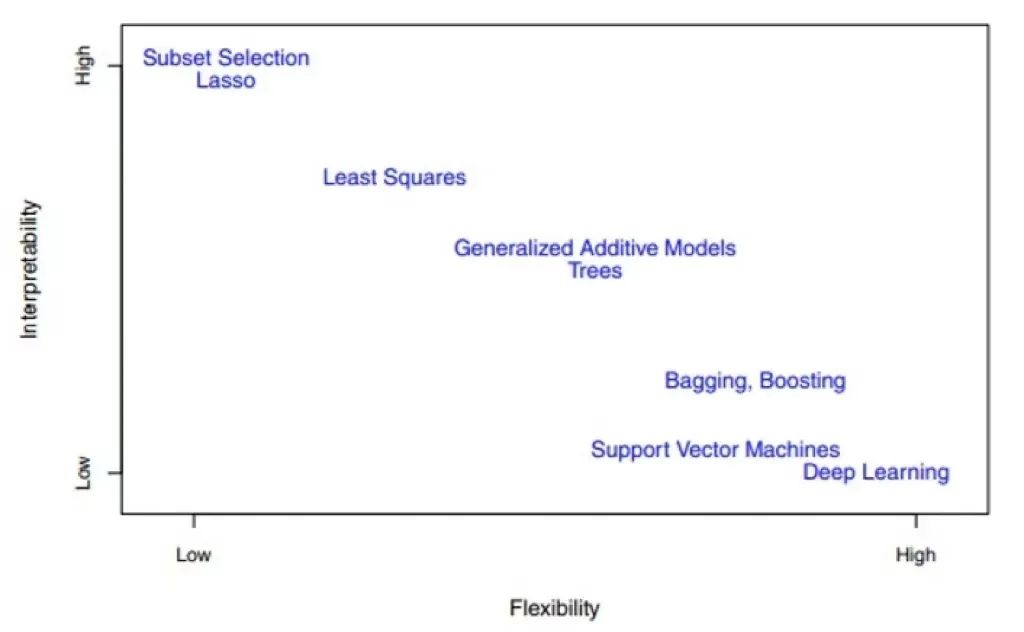
关于这一点,我们耳熟能详的基于神经网络的深度学习就是最好的例子。理论上来说,神经网络可以拟合任意一种非线性的模型或函数。通常这些非线性的模型或函数其 flexibility 都非常好,预测精度也非常高,而最严重的缺点就是模型的可解释性非常差。这就是通常我们所说的深度学习模型可解释性较差的由来。
上图中有一点需要指出的是,我们最常用来拟合线性模型的 least squares 方法并不是 flexibility 最低的方法。比如 lasso 就通过增加了正则项来对模型的预测变量做了选择,换句话说,lasso 方法通过正则化项限定了某些预测变量的参数为 0,所以 lasso 方法的模型更不 flexible。
此外,对于统计学习的方法而言,还有很多分类:例如有监督学习和无监督学习,分类问题和回归问题等,这些很多书籍和材料都有涉猎,此处不再赘述。
模型构建起来后,有一个很直观的问题就是:这个模型好不好?
06.
如何衡量一个模型的好坏?
对于一个给定的数据集,为了衡量一个模型的好坏,我们需要某种方式来衡量模型的预测是否贴合实际观测到的数据。换句话说,我们需要量化模型预测值与真实值之间的差距,如果此差距很小,说明模型拟合数据拟合得很好,反之同理。
上文提到统计学习方法可分为处理分类问题的方法和处理回归问题的方法,此处从回归问题中如何量化模型预测值与真实值之间的差距开始谈起。对于回归问题,通常我们常用的用来衡量模型拟合效果的 metric 就是 mean squared error (MSE):
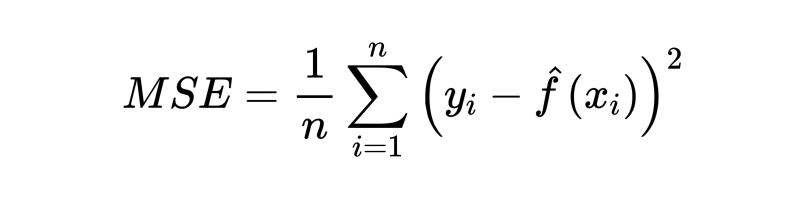
其中 y 代表观测到的真实值,f(x) 代表模型的预测值。如果 MSE 的值很小,说明模型拟合数据的能力强,反之同理。然而,当我们利用上式计算 MSE 的时候,用的都是我们已经用来训练模型的数据,所以上式更准确的名字应该是训练 MSE (train MSE)。
而我们训练模型归根结底的目的是要用其去预测或推断没见过的数据(未曾用于训练模型的数据),所以通常情况下我们不会太在意训练 MSE,与此同时我们更在意测试 MSE (test MSE)。顾名思义,测试 MSE 就是将模型用于测试集得到的 MSE。虽然区分训练集和测试集是再简单不过的概念,但在实际操作中,还是有很多误用数据导致 data snooping 现象的出现,data snooping 指的是在做统计推断之前先查看了数据的特征(甚至包括训练数据),这无疑与我们利用模型推断未知数据的基准相违背。这一点在课上 Prof. Yang Can 给了几个例子,确实让我想起了我之前的一些沙雕操作。
实际上,这种利用 MSE 来衡量模型拟合效果的行为对应着监督学习里两种策略的其中一种:经验风险最小化(这种 squared-error 只是经验风险最小化策略中的一种损失函数)。如果对上式的期望形式做拆解,考虑随机误差项时可写为:
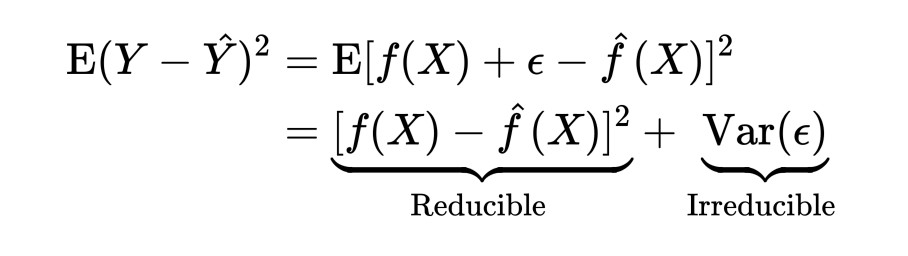
很容易发现,总的误差被分为了两部分:一部分是可消除的误差,这部分误差来源于模型与真实数据之间的关系,模型拟合数据好自然这部分误差就小;而另一部分则是不可消除的误差,来源于随机误差。训练模型的过程,就是寻找一个能将可消除误差降到最低的模型。
针对同样的数据,我们可以拟合很多不同参数的同类模型、不同种类的模型,根据经验风险最小化的策略,我们选择目标模型的标准很简单:test MSE 最小。
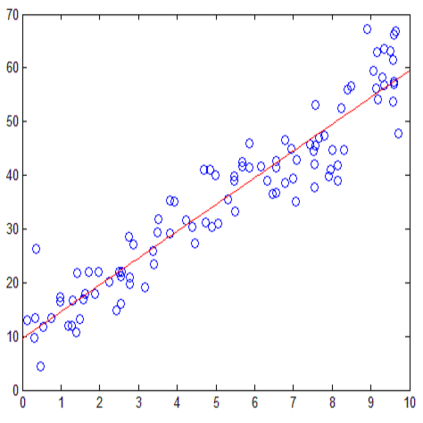
如下图所示,在一个模拟数据集中,左图中圆圈为样本点,黑线所代表的是生成样本点的真实模型。橙色、蓝色、绿色的线分别是针对这个数据集所拟合的不同的模型,可以看出,橙色线是一个线性模型,蓝色和绿色线都是非线性模型,但蓝色离真实模型更接近,绿色则是过多的捕捉了样本点分布的局部特征。
给定一个输入,用这三个模型中的任何一个,我们都能得到一个输出,然而,到底哪个模型能给我们更准确的输出?三个模型中,直观来看无疑蓝色是最好的。反应在下图右侧的图中,则是红色所代表的 test MSE,蓝色模型的 test MSE 是最低的,所以我们在三个模型中会选择它。
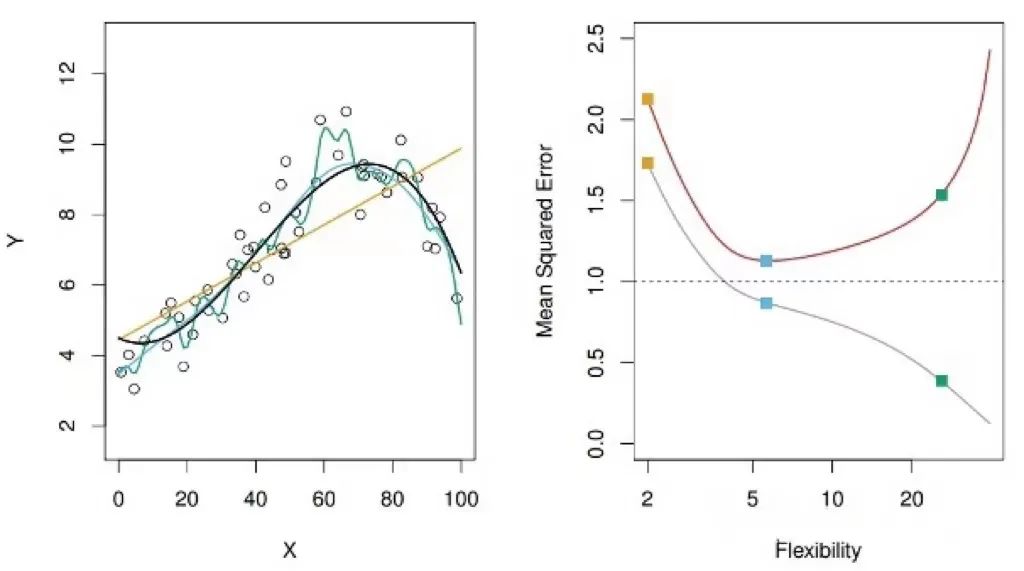
此外,在右图中,我们发现红色所代表的 test MSE 出现了一个典型的先降后升的“U型”趋势图,然而灰色所代表的 train MSE 则是一路下降。换句话说,随着模型 flexibility 的提升,train MSE 不断下降,这很容易理解,因为模型 flexibility 不断提升的过程中在不断的贴近训练集中的数据。而作为我们衡量模型好坏的标准,test MSE 先降后升,说明模型 flexibility 不是越高越好。模型 flexibility 不断提升的过程中,到底发生了什么?
07.
过拟合与variance-bias trade-off
实际上,对于给定数据集,随着模型的 flexibility 不断提升,模型的复杂程度也在不断上升。以上图为例,绿色模型的非线性程度更高,相较其他模型,它能捕捉到很多其他模型无法拟合的局部特征。但实际在此例子中,真实模型是黑色线所代表的模型,并没有绿色模型那么复杂,换句话说,绿色模型通过提升 flexibility 过度学习到了很多不属于真实数据的部分。这种现象称为过拟合 (overfitting)。过拟合过程中学习到的不属于真实数据的部分实际上来源于训练集中数据的随机误差等。
为什么过拟合会降低 train MSE、提升 test MSE 呢?此处将 MSE 进行拆解可分为以下部分:
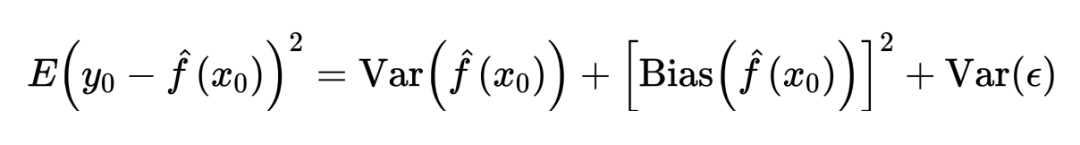
从上式中不难看出,要想最小化经验风险,最好的模型应该同时具有两个特点:variance 小、bias 小。通常情况下,具有高 flexibility 的模型其拟合数据的能力很强,所以 bias 很小,然而因为模型过于 flexible,其很容易受到新数据、或是数据变化的影响,variance 很大;而低 flexibility 的模型不容易受到新数据变化的影响、但拟合数据的能力较弱,所以 bias 较大而 variance 很小。两者似乎无法同时缩小,这就是统计学习中一个重要的概念:variance-bias trade-off。
下图是在三个不同的模拟数据集上所拟合模型的结果,很容易看出,不管真实模型如何,variance-bias trade-off 都存在。有一点需要说明的是,红线指的是 test MSE,黑色虚线指的则是随机误差的方差,可以看出针对给定数据集,任何统计学习方法/模型所能达到的理论最小 test MSE 就是随机误差的方差。
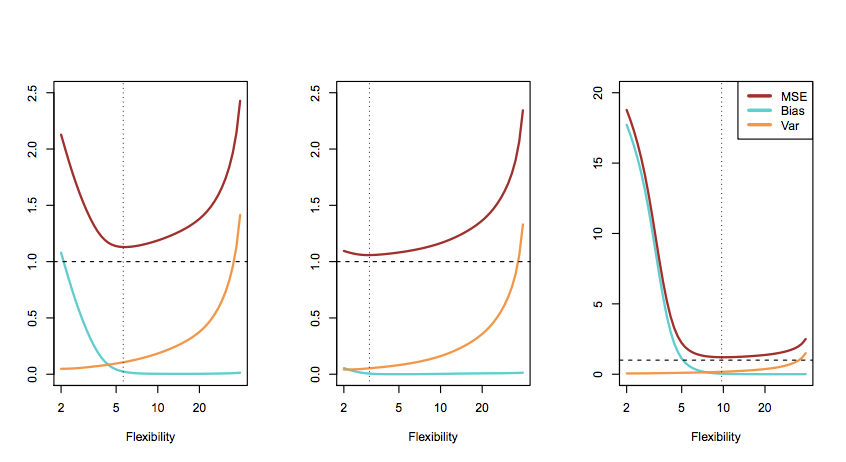
我们的目标模型是 test MSE 最小,而这实际上就是奥卡姆剃刀法则所阐述的:我们需要的模型是在能最大程度拟合数据的同时最简单的模型。想要获得这样的模型,只利用经验风险最小化是无法达到的,经验风险最小化只会最大程度降低 bias,这种伴随而来的是由 variance-bias trade-off 带来的 variance 上升。最直接的解决办法就是同时对 bias 和 variance 进行约束,这就带给了我们监督学习中的另外一个策略:结构风险最小化。结构风险最小化就是在经验风险最小化的基础上加上一个正则项对模型的复杂度做约束,以实现 bias 和 variance 的平衡。
读到这里,或许会有好奇,深度学习的模型flexibility都很高,为什么不会有明显的过拟合现象存在呢?那就是另一个跟正则化有关的有趣的故事了,最近正好在学习gradient boosting相关的内容,此处暂时讲不清楚,先略过等啥时候能讲清楚了再来填坑。
08.
分类问题
上文提到回归问题中利用 test MSE 来衡量模型好坏,对于分类问题,也有一个类似的衡量指标:误分类率 (error rate)。可写为以下形式:
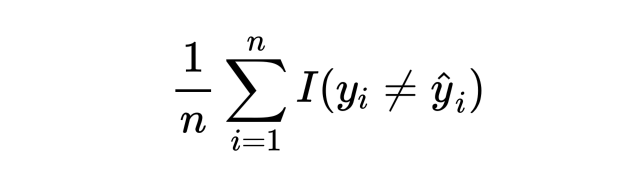
其中 I 是指示函数,当模型预测值与真实值不同时该函数取 1,反之取 0。我们可以简单根据 test error rate 来选择模型。
上式所提到的 test error rate 可以通过一个简单的分类器来达到最小,该分类器根据预测变量的值将每一个样本分到最有可能的类别。可以写成以下形式:
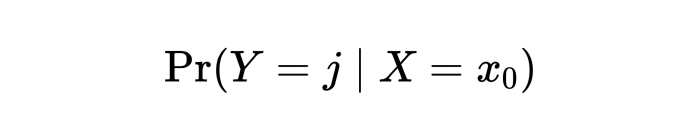
当以上条件概率最大时,我们把该样本分到第j类(证明此处省略),而这个分类器就叫做贝叶斯分类器 (bayes classifier)。对于最简单的二分类问题,如果上式的 j=1 时,可以简单考虑 0.5 为一个 threshold,当上式的条件概率大于 0.5 时将该样本分为 1,反之分为 0。
下图所示即为利用贝叶斯分类器执行一个二分类任务(模拟数据集),橙色和蓝色圆圈所代表的是两类样本点。紫色虚线代表的点就是概率为 0.5 的地方,这就是 bayes decision boundary。
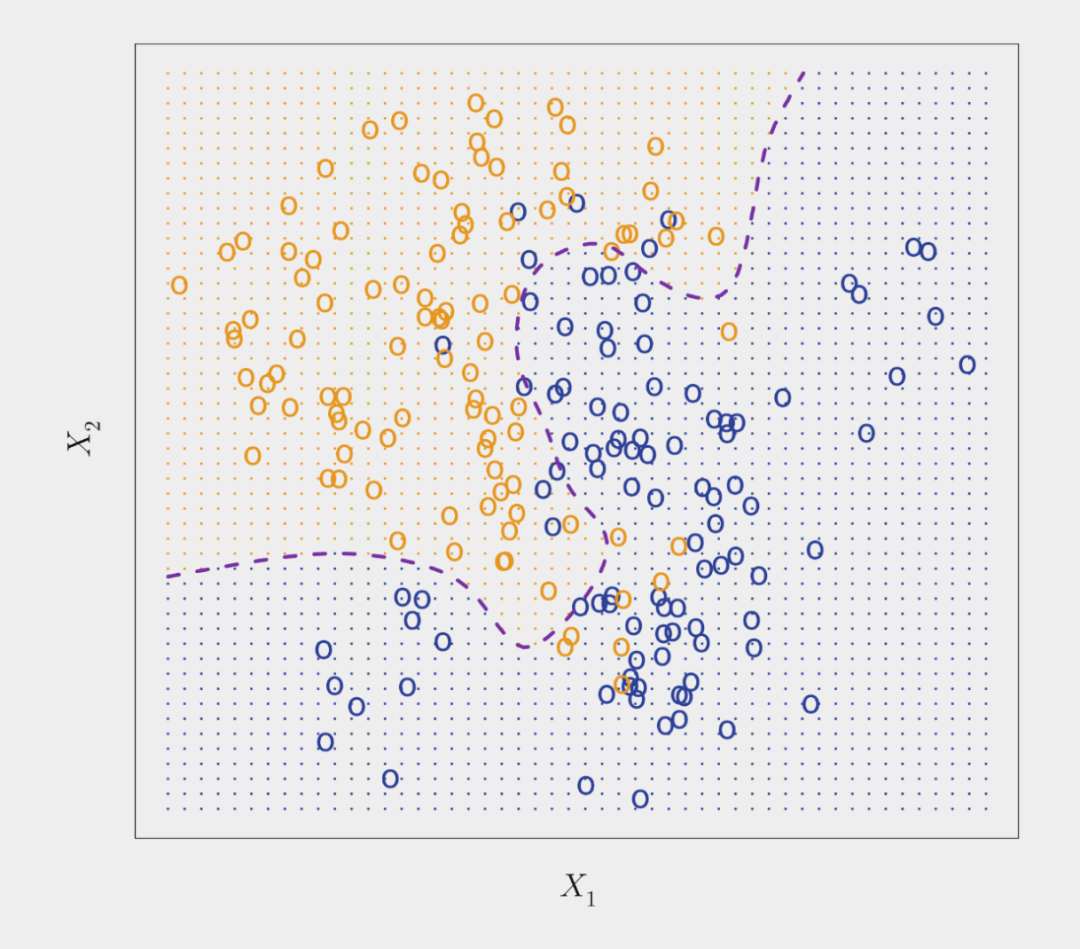
考虑到贝叶斯分类器的特点,理论上我们总是想用它来做分类任务。但是在真实数据集中,对于给定的样本 x,其所属类 Y 的条件分布是不可知的。所以贝叶斯分类器对我们而言是一个无法达到的标准,很多分类器也是通过根据训练数据估计以上条件分布来对样本进行分类的。一个很简单的例子就是 K 近邻法(KNN),在 KNN 中,可以通过调整 K 值来调整模型的 flexibility,K 值较大时模型 flexibility 较小,而 K 值较小时模型 flexibility 较大。选择合适的K值可以达到接近(略低于)贝叶斯分类器的分类效果。
09.
总结
以上就是我对最近看的一些统计学习的基础概念的简单分享,这些内容全都是入门内容,奈何之前丝毫不在意,走马观花导致基础不牢,以此作为简单的反思和记录。内容虽然简单,如有错误也请各位批评指正。文中图均来自于以下书籍:
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning(Vol. 112, p. 18). New York: springer.
最后,贴上我最近痴迷的 Prof. Yang Can 十年前所写的统计学习相关的博客,他也是浙大的学长。个人觉得写得很浪漫、很有故事性的同时不失其科学性,强烈推荐大家去看看!希望有一天我也能有能力像学长这样驾轻就熟的运用各种方法。以下,请各位尽情享用:
1. 统计学习那些事
https://cosx.org/2011/12/stories-about-statistical-learning
2. 那些年,我们一起追的 EB
https://cosx.org/2012/05/chase-after-eb
https://cosx.org/2014/04/lmm-and-me


🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧