会当凌绝顶,一览众山小——谈谈人工智能里的最优化
最近,公众号的读者长势喜人,留言和互动也渐渐多了起来。不论是产品经理、在校生、运营还是工程师,都经常提一个问题:听村长说,现在是人工智能时代,俺也作兴这个,恁说该弄啥哩?
上、上、上篇文章我们说了,想成为一个二手的人工智能科学家,既不是报个Python培训班,也不是买块GPU跑起来,更不是在Kaggle比赛数据上凑个答案。最重要的基础技能,是不管扔给你一个什么样的模型,都得能把它的最优参数找出来,这个就叫最优化,说色唐纲叫做Optimization。掌握了这门手艺,你才能在设计和选择模型时进入自由王国,而不是只会拿开源工具跑个结果。
最优化的任务,是找一个函数的最大值,通俗地说就是爬山:把你扔在一片山地里,看你怎么能最快地爬上最高峰。登山也分这么两种:一种是无场地边界限制的登野山,这对应于无约束优化问题;还有一种是有场地限制的登山,这叫做有约束优化问题。显然,前者是后者的一个特例,解决起来也简单一些。
注意,本文用登山问题来比喻最优化,是为了方便大家理解。不过实际数学上描述的最优化问题,习惯上是求最小值,也就是“探谷”而非“登山”,因此在提到“某某下降法”这样的术语时,大家能领会其精神就好了。
有约束优化问题,可以通过拉格朗日乘数法转化成无约束的方程组优化问题,你可以这么理解,把登山赛场的围栏去掉,转而变成指定一条赛道,通过求解赛道上的公里数来求最高峰的位置——当然,这条赛道是在高维空间里的曲折蜿蜒的。
对于有约束优化问题,如果场地限制是个凸的形状,而山也是象下图中神山冈仁波齐那样的凸函数(“凸”是啥意思各位自行查找),这就叫凸优化问题。凸优化式的登山问题,理论界研究比较充分,解决起来也相对容易。因此,在设计目标函数时,我们往往倾向于构造一个凸问题,这样后面的事情就一马平川了。

好了,既然有约束优化问题可以转化成无约束优化问题来解决,我们就要重点掌握无约束优化问题的思路和方法了。要顺利登顶,无非要解决这三个基本问题:
“如何摸清地形情况”
“如何决定往哪边走”
“如何决定走多远”
根据这三点的不同,方法也是琳琅满目。各种方法的细节,当然不是本文能说清,但我希望带领大家在这个领域走上一遭,让诸位大致了解在什么情况下,应该有何种思路。至于具体的方法,大家再去查书就行了。因此,坚持要问“哪里有code下载”的朋友们,敬请你们出门,上桥,右转!
如果这片山地有很多山峰,要摸清地形,最高效的策略,是先开着直升机飞到空中看看全貌,找到最高峰的大致位置,再去那里精细地勘察。遗憾的是,目前所有实用的优化方法,都没有这种直升机式的航拍能力。据传说,量子计算实现以后,可能会有这种一目千里的办法,这个我们就不提了。

在有多个山峰的情况下,一般的方法都只能找到离自己的出发点比较近的某个峰,这称为局部最优(Local Optimum)。一定要找到全局最高峰的方法也有,例如模拟退火、遗传算法等,但这都是带有一些随机性的方法,简单说就是像醉鬼一样瞎撞,当然醉鬼爬山,肯定就很慢了,所以工程上并不常用。我们在这里,也只讨论一个峰的优化问题。
在登山过程中,我们一般都假设:给定一个位置x,对应的海拔高度f(x)是可以计算出来的——这不是废话么,高低都不知道的还优化个什么劲?除了计算海拔高度,我们往往还希望知道,在当前位置往哪个方向最陡峭,也就是上升地最快,这就是梯度▽f(x)(注意,梯度是个方向而不是一个值,在数学上来看就是一个矢量,不懂的回去找你的体育老师重修去!)

这里要注意了:在实践中,梯度能不能算出来,可就不一定了。如果梯度算不出来,或者算起来时间代价极大,怎么办呢?这种场景虽然遇上的不多,但是万一遇上了,不知道怎么办也是抓瞎,就好像说相声的不会太平歌词,别人挣一百,你挣七十五。
在梯度无法计算的情况下,我们可以采用这样的方法:从上图中找三个人站成个三角形,海拔最低的那个人想办法朝海拔高的方向走一段,然后再重新看三个人的海拔高度。就这样把这个三角形象个阿米巴虫一样不断伸缩,最终可以收敛到最高点,这个方法叫做下降单纯形法(Downhill Simplex),或者就叫阿米巴(Ameoba)变形虫法。用这种方法,爬地球上的山峰,三个人配合就够了;而爬N维空间里的山峰,就得N+1个人配合了。
当然,如果梯度可以计算,那就简单多了:只要沿着最陡峭的方向走上一小步,海拔肯定是升高的,走完这一小步,再计算新的梯度,小车不倒只管推,总有走到山顶的那一天,这就叫做梯度下降法(Gradient Descent)。
梯度法在实操过程中,又有两种思路:一种是在所有训练样本上算好方向,然后加起来得到总的方向,这叫做批处理模式(Batch Mode);还有一种是在一小批样本上算方向,走一小步,然后再取下一小批样本算方向,这叫做随机梯度下降法(Stochastic Gradient Descent,SGD)。听起来好像是前一种方法更加合理,可实际上,常用的是后一种。
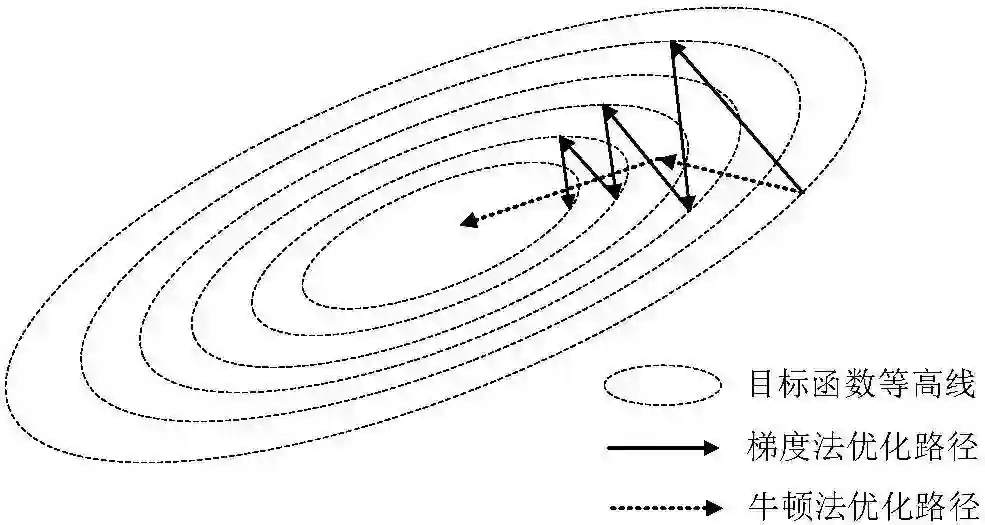
那么,批处理的梯度法有什么问题呢?我们看看下面这个图就明白了:在这样一个长条状等高线的地区登山,如果每一步都按梯度方向来(注意梯度方向跟等高线垂直的),就会走出这样拐来拐去的路线,不知啥时候才能爬到山顶。有人说,这样奇怪的山很常见么?没错,很常见。因此,批处理的梯度法,工程上基本是不可用的。而SGD的方法,由于不同的数据片引入了一定的随机性,也就是有点儿乱撞的意思,反而收敛性要好得多。
这种随机性带来的好处,有时候是超出人类想象的。Google的大神Jeff Dean等人干脆搞了个参数服务器(Parameter Server),让一堆机器分别读数据片段,完全互相不商量地去更新同一个模型,结果不但训练得飞快,收敛性也相当好,您瞧这找谁说理去!
那么批处理的方法就不能用了么?不然。根据上面的图来看,只要引入二阶导数信息,就非常容易避免拐来拐去的问题了。二阶导数,我们称为Hession矩阵H(x) = ▽^2 f(x),注意,H已经是一个矩阵而不是矢量了。用二阶导数修正一下走的方向,沿着 {H(x)}^(-1) ▽f(x)的方向走,这就叫做牛顿法(Newton Method)。
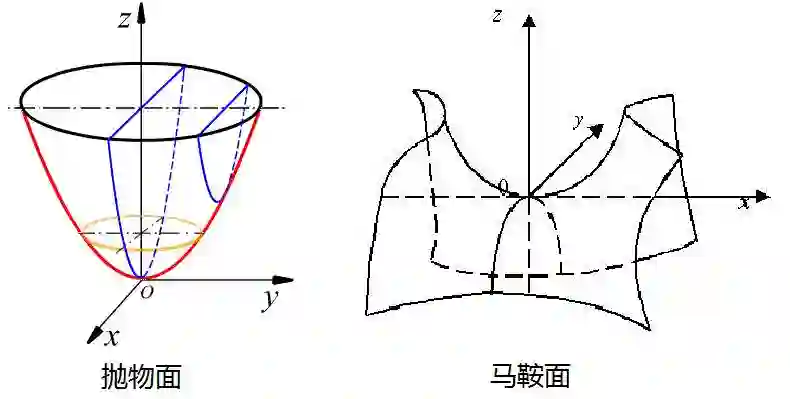
看起来,牛顿法应该没问题了?先别急,这个也不好用。学过线性代数的朋友都知道,H不一定正定阿!也就是说,从二阶导来看,你不一定站在一个局部的抛物面上啊,万一脚下是个马鞍面,那还求什么极值?这怎么解决呢?严谨的数学家们决定用捏造的方法来解决!既然H不一定正定,那就造一个假的H出来,假的这个得是正定的,这就叫做拟牛顿法(Quasi-Newton Method)。当然,要以假乱真,就不能胡来了,捏造的方法,基本上就是根据你前面走的几步(比如前图中那几位)的海拔、梯度方向来拟合。具体的拟牛顿法有很多种,比较常见的一种,是BFGS方法,这里的四个字母,是四位数学家的名字。
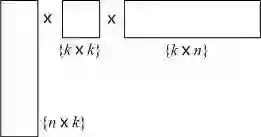
拟牛顿法和牛顿法一样,都会碰到一个工程上的挑战:当x的维度很高时,H就会变得非常大。比方说x是一百万维,H就有一万亿个元素,一般计算机的内存可对付不了这么大的矩阵。于是,还要把H做个近似,将其分解为两个条状矩阵和一个对角阵,这样规模就大大降低了。如果在BFGS方法上应用这一技巧,就是著名的L-BFGS方法,这里的“L”,指的是“Limited-Memory”。
说到这儿,细心的读者可能会发现一个问题,不论是梯度法、牛顿法、BFGS还是L-BFGS,都可以总结为“先方向,后步长”的方法。但是在找方向的过程中,又是编二阶导,又是近似的,这个方向找的还靠谱么?我只能说,大致上靠谱,不过确实也打了不小的折扣。那么如果不做这些妥协和近似行不行呢,办法也是存在的,不过这就要要变成“先步长,后方向”的思路。
先方向后步长方法的典型代表,是置信域法(Trust-region method),与前面的拟牛顿法相比,它不用近似一个正定的H——这里的妙处在于,只要用金箍棒划了一个圈儿,不管圈儿里是抛物面还是马鞍面,最高点是可以求出来的,而且有个接近闭式的解!

不管是先步长还是先方向,步长到底选多大合适呢?说实话,这基本上是个玄学问题(如果不是神学问题的话):步子迈小了,得多怎才能爬上去;步子迈大了,象毗湿奴那样一下子迈过三界的话,什么梯度、Hession矩阵就全乱了,优化过程也变得不可控。但是,规律还是有的,那就是步长总是要按一定的规律逐渐变小的,好比你罚点球助跑的时候,前面大步流星,后面碎步紧倒,才能准确找到球。
篇幅有限,先说这么多,读者们希望我展开讲哪块,欢迎在“计算广告”后台留言。其实,本文里提到的方法,其实还都是一些基础方法。对于高维度、大规模、复杂约束的问题,还需要更高级的方法才能解决——只不过,这些高级方法往往是上面这些基础方法的组合。看懂了本文,能熟练文中加亮的关键词,才能玩弄各色的目标函数于股掌之间,成功地登上白头山最高峰,成为人工智能领域二手的天降伟人!

公众号文章精选:




