NeurIPS 2022 | 一句话让三维模型生成逼真外观风格,精细到照片级细节
机器之心专栏
来自华南理工大学、香港理工大学、跨维智能、鹏城实验室等机构的研究团队提出了一种基于文本驱动的三维模型风格化方法,该方法可对输入的三维模型根据文本进行更具真实性和鲁棒性的风格化。
根据给定输入创建 3D 内容(例如,根据文本提示、图像或 3D 形状)在计算机视觉和图形领域具有重要应用。然而这个问题是具有挑战性的,现实中通常需要专业艺术家(Technical Artist)耗费大量的时间成本去创作 3D 内容。同时,许多网上的三维模型库中的资源通常是没有任何材质的裸露三维模型,要想将他们应用到现阶段的渲染引擎中,需要 Technical Artist 为它们创作高质量的材质,灯光和法向贴图。因此,如果有办法可以实现自动化、多样化和逼真的三维模型资产生成,将是很有前景的。
因此,华南理工大学、香港理工大学、跨维智能、鹏城实验室等机构的研究团队提出了一种基于文本驱动的三维模型风格化方法——TANGO,该方法对于给定的三维模型和文本,可以自动生成更具有真实性的 SVBRDF 材质,法向贴图和灯光,并且对低质量三维模型有更好的鲁棒性。该研究已被 NeurIPS 2022 接收。

项目主页:https://cyw-3d.github.io/tango/
模型效果
对于给定的文本输入和三维模型,TANGO 可以产生精细程度较高的具有照片级真实感的细节,并且不会在三维模型表面产生自交问题。如下图 1 所示, TANGO 不仅在光滑的材料(如金,银等材质)上呈现出了逼真的反射效果,而且对于不平整的材质(例如砖块等)也能通过逐点法线的估计渲染出凹凸不平的效果。

图 1. TANGO 的风格化结果
TANGO 能够生成真实渲染结果的关键在于能够精准地把着色模型中的每一个部件(SVBRDF,法向贴图,灯光)拆分开,并分别学习,最后这些拆分的部件再通过球高斯可微分渲染器输出图片,并送到 CLIP 中和输入文本计算 loss。为了展现解耦部件的合理性,该研究对每个部件都进行了可视化。图 2 (a)展示了 “一双砖块做成的鞋子” 的风格化结果,(b)展示了三维模型原本的法向,(c)是 TANGO 对三维模型上每个点预测的法向,(d)(e)(f)分别表示 SVBRDF 中的漫反射,粗糙度和镜面反射参数,(g)是 TANGO预测的用球高斯函数表达的环境光。

图 2 解耦的渲染部件可视化
同时,该研究也可以对 TANGO 输出的结果进行编辑。例如在图 3 中,该研究可以换用其他的光照贴图对 TANGO 的结果进行重新打光;在图 4 中,可以对粗糙度和镜面反射度参数进行编辑,实现对物体表面反射程度的改变。

图 3 对 TANGO 风格化结果进行重新打光

图 4 对物体材质进行编辑
另外,由于 TANGO 采用预测法向贴图的方式增添物体表面细节,因此对于顶点数较少的三维模型也有很好的鲁棒性。如图 5 所示,原始的 lamp 和 alien 模型分别有 41160 和 68430 个面,研究人员对原始模型进行了降采样,得到了只有 5000 个面的模型。可以看到 TANGO 在原始模型和降采样模型上的表现基本相似,而 Text2Mesh 则在低质量的模型上出现了较为严重的自交现象。
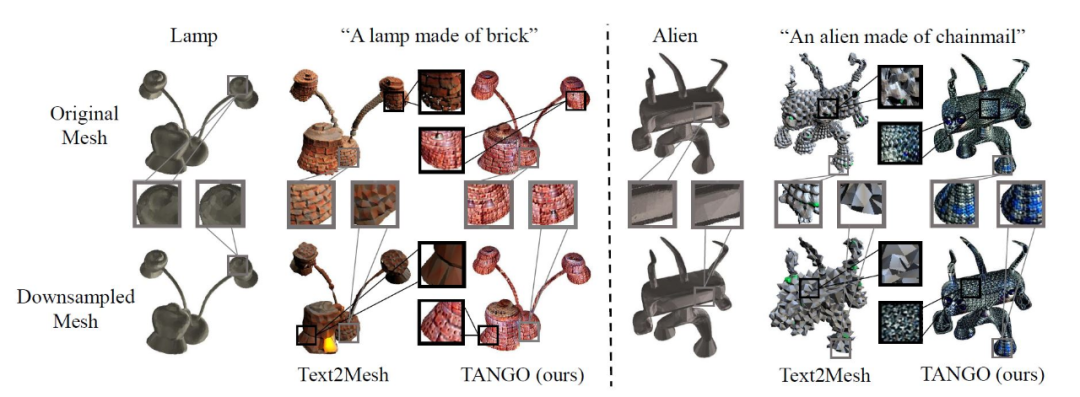
图 5 鲁棒性测试
原理方法
TANGO 主要关注于由文本指导三维物体风格化的方法。这一领域目前最相关的工作是 Text2Mesh,它使用了预训练模型 CLIP 作为指导,预测三维模型表面顶点的颜色和位置偏移,从而实现风格化。然而简单地预测表面顶点颜色通常会产生不真实的渲染效果,且不规则的顶点偏移会造成很严重的自交。因此,该研究借鉴传统的基于物理的渲染管线,将整个渲染过程解耦为 SVBRDF 材质,法向贴图和灯光的预测过程,并分别用球高斯函数表达解耦的元素。这种基于物理的解耦方式使得 TANGO 可以正确产生具有真实感的渲染效果,并具有很好的鲁棒性。
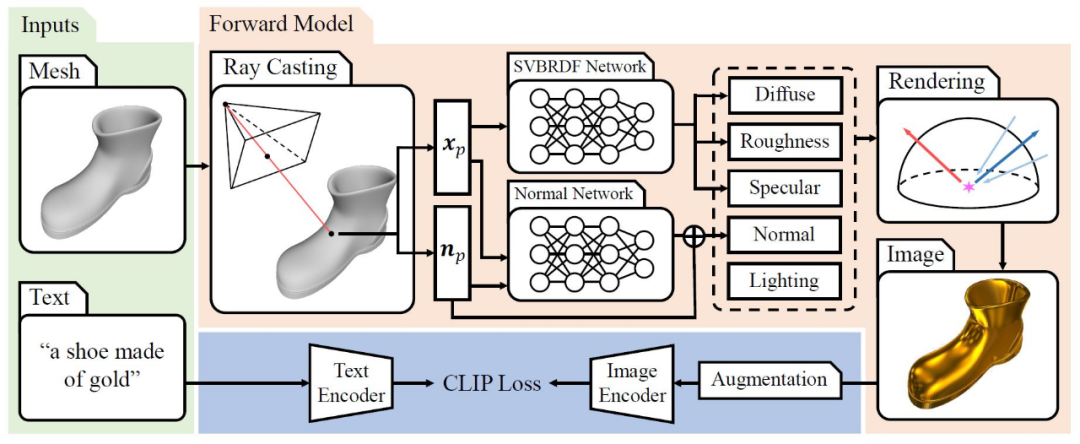
图 6 TANGO 流程图
图 6 展示了 TANGO 的工作流程。给定一个三维模型和文本(例如图中的“一个金子做成的鞋”),该研究先把这个三维模型缩放到一个单位球内,接着在三维模型的附近采样相机位置,在这个相机位置发射射线找到与三维模型的交点 xp 和该交点的法线方向 np。接下来,xp 和 np 会被送入SVBRDF网络和 Normal 网络中,预测该点的材质参数和法线方向,同时,用多个球高斯函数来表达场景中的光照。对于每一次训练迭代,该研究使用可微分的球高斯渲染器渲染图像,然后使用 CLIP 模型的图像编码器对增强图像进行编码,最后 CLIP 模型反向传播梯度更新所有可学习的参数。
总结

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com