SIGGRAPH Asia 2022 | 一句话生成高清360度场景及光照,可直接渲染数字资产
机器之心专栏
作者:MMLab@NTU
来自南洋理工大学 S-Lab 的研究者提出 了一个基于零次学习文本驱动的 HDR 全景图合成框架。
伴随着元宇宙的浪潮和虚拟现实技术的不断进步,业内对于 3D 逼真写实渲染的需求愈发凸显。除去建模精细度,环境光照也是影响渲染质量的重要因素。在所有的图形学技术中,高动态范围全景贴图(HDRI)能够提供逼真的场景光照和沉浸式的环境纹理,是最通用且高效的方法。
然而,能够直接应用到渲染管线中的 HDRI 应具有足够多的场景细节、极高的分辨率和记录线性光照的高动态范围。这使得不论是采集还是编辑 HDRI 都变得十分困难和昂贵。这自然而然地引出一个问题,我们能否使用图像生成模型来合成 HDRI,同时给予用户足够简单的输入(例如文本),即文本驱动的高动态范围全景图生成。这样一来,在任何虚拟现实应用中,没有专业知识的用户也可以仅仅通过一句话合成出自己想要的逼真场景,同时获得与之匹配的写实光照。

想要达成这样的目标,面临着如下四个挑战:
1)超高分辨率:已有图像生成模型难以在超高分辨率(大于 4K)下合成场景级别的内容,同时保证丰富的细节。
2)空间一致性与整体感:不同于以物体或人为中心的图像合成,场景级别的全景图常常包含很多物体和特定的空间结构。在图像合成过程中保持空间连续性及场景语义完整是一个很难的问题。
3)文本一致性:不同于 DALLE2 和 stable-diffusion 等文本驱动的生成模型,我们难以收集到足够的文本 - 全景图数据对用于训练,因此在缺失成对训练数据的情况下,如何将场景语义与输入文本对齐通过自监督的方式对齐也是一项挑战。
4)高动态范围:不同于传统图像(动态范围在 0-255 之间),HDRI 记录了线性域下的光辐照度,常常具有较大的动态范围,会导致不稳定的学习。

-
项目主页:https://frozenburning.github.io/projects/text2light/ -
代码:https://github.com/FrozenBurning/Text2Light -
论文:https://arxiv.org/abs/2209.09898 -
Colab demo:https://colab.research.google.com/github/FrozenBurning/Text2Light/blob/master/text2light.ipynb
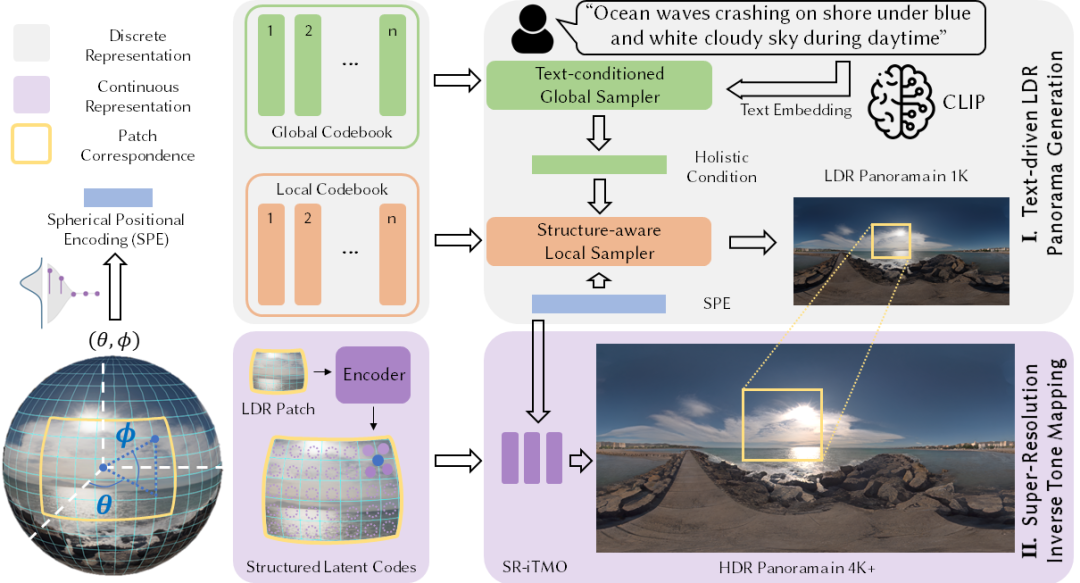
在阶段一中,我们采用了层级化的框架,将全局外观与局部细节解耦到各自独立的模块中进行建模。具体而言,阶段一由三个模块组成,如下图所示:
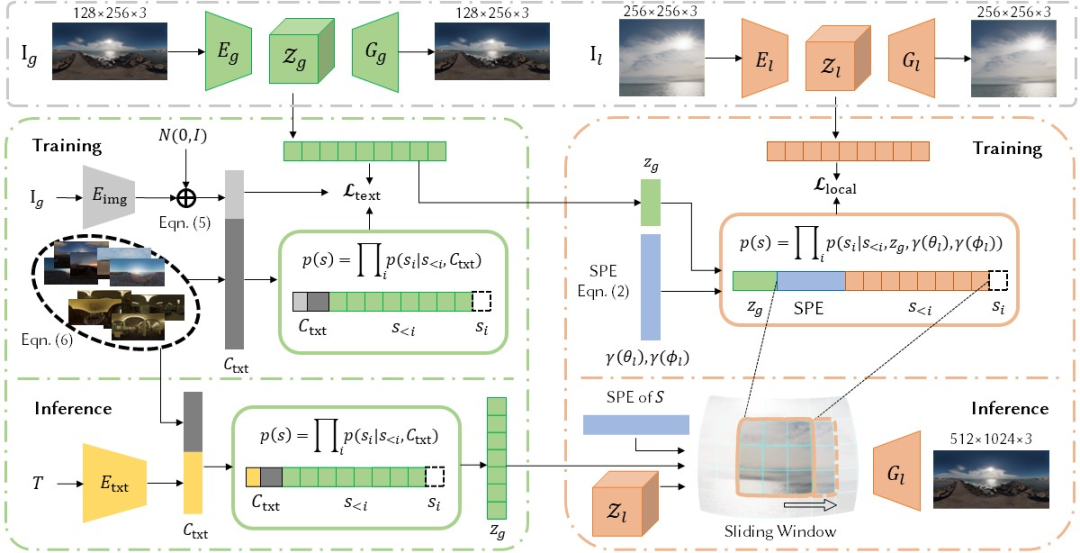
1)全局 - 局部层级码本:我们使用 VQVAE 的训练方法,将极低分辨率的全景图嵌入到全局 (global) 码本中,将高分辨率的图像块 (patch) 嵌入到局部 (local) 码本中。这样一来就可以从全局码本中采样具有空间一致性和整体感的全局特征,同时从局部码本中采样获得局部细节。
2)基本文本的全局采样器:我们使用 CLIP 预训练得到的图像编码器将训练数据中的全景图转化到文本 - 图像空间中,同时获得数据集中相应样本的 K 近邻特征向量,进而采样器通过自监督学习获得根据文本采样全局特征的能力。
3)具备结构感知的局部采样器:根据全局采样器输出的全局语义特征,我们进而训练一个局部采样器来合成全景图中的局部细节。为了保持全景图的特有球面空间结构,我们还引入了球面位置编码作为一种特殊的归纳偏置。
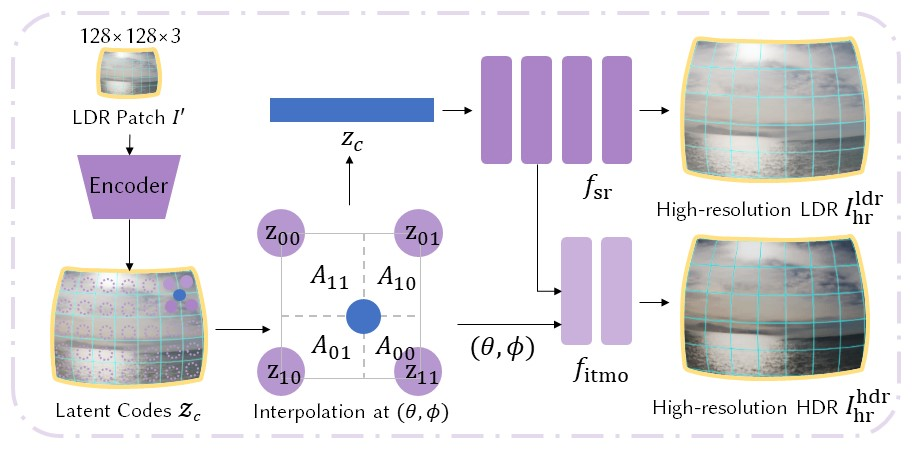
在阶段二中,作为阶段一中离散表征的补充,我们将全景图建模为连续球面场,即可以使用任意球面坐标来查询得到一个高动态范围像素值。这一建模同时满足了超分辨率(低分辨率到高分辨率)和逆向色调映射(低动态范围到高动态范围)两种需求。具体而言,如下图所示,我们首先使用卷积网络将图像块编码为与像素对齐的潜在特征向量。对于连续球面上的任意位置,我们利用区域插值从其四个近邻特征向量中获得其特征,并最终使用两个 MLP 得到输出的 HDR 像素值。

输入 (green grass field with trees and mountains in the distance), 我们能得到下面这样沉浸式的 VR 体验!



我们的生成结果甚至可以直接在 blender 中用来渲染大规模城市场景:
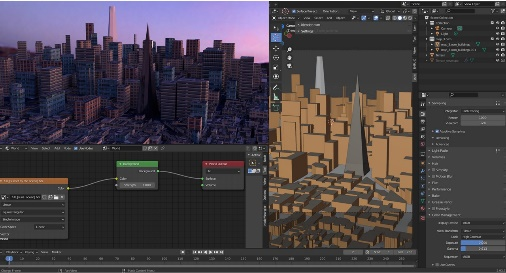
同时我们还展示了 text2light 在编辑全景图上的潜在能力。

本工作提出了 Text2Light,一个基于零次学习文本驱动的 HDR 全景图合成框架,能够根据一段场景描述合成高分辨率、高动态范围的全景图,并可以直接用在下游图形学任务和应用上,例如逼真地渲染数字资产。我们希望本工作能够为虚拟现实和元宇宙生态提供了一种全新的可能。