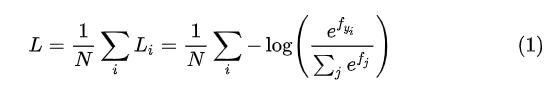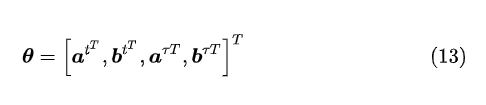![]()
来源丨https://zhuanlan.zhihu.com/p/180465704
目前,
AutoML
技术
非常火,尤其是NAS领域,之前有一篇文章已经对现有的AutoML技术做了总结:
https://zhuanlan.zhihu.com/p/158162306
论文:
https://arxiv.org/pdf/1905.07375v1.pdf
不过这篇文章将介绍一下
如何使用AutoML技术来搜索损失函数。一般来说,损失函数都是需要我们手动设计的,以分类任务而言,我们通常会使用交叉熵。碰到数据集imbalanced的情况,可能会给每个类别加上一个权重。在RetinaNet论文里为目标检测任务提出了FocalLoss。上述都是对交叉熵函数根据特定任务做了修改,可是这样的修改通常需要我们能够洞察到问题的本质,换句话说这需要专业的知识。那我们这种蔡文姬还有设计loss函数的机会吗?商汤科技在这方面做了探索,下面将介绍论文细节。
1. 论文贡献
1、
设计了损失函数搜索空间,该搜索空间能够覆盖常用的流行的损失函数设计,其采样的候选损失函数可以调整不同难度级别样本的梯度,并在训练过程中平衡类内距离和类间距离的重要性。
2、
提出了一个bilevel的优化框架:本文使用强化学习来优化损失函数,其中内层优化是最小化网络参数的损失函数,外层优化是最大化reward。
2. 回顾之前的损失函数
Softmax Loss
![]()
N表示数据集大小,
是最后全连接层输出的预测向量(还没有做softmax运算),
表示向量
的第
位置上的值,因为真实值是one-hot的向量(即只有一个1,其余全是0),
中的
表示1的索引值。
因为
是最后全连接层的输出,所以我们可以将它表示成
其中
是矢量
和
之间的夹角,所以上面公式(1)中的损失函数可以转换成
Margin-based Softmax Loss
看到公式(3)可以很自然地想到能在
和
之间能够插入一个可微变换函数
来调节角度,进而得到margin可变的softmax loss:
不同的
可以得到不同的损失函数,原文中总结了如下几种:
除了在概率上做变化外,Focal Loss对softmax loss做了如下变化:
3. Loss函数分析
3.1 Focal Loss
focal loss的提出主要是为了解决imbalanced的问题。相对于原始的softmax loss,focal loss在求导之后等于原始的softmax loss求导结果再乘以
,换言之
用来缓解imbalance的问题。
3.2 margin-based softmax loss
为方便说明,我们可以假设所有的矢量是单位矢量,即
和
我们使用公式(4)中的损失函数来分别对
(类内,intra-class)和
(类间,inter-class)求导,得到:
文中进一步将
类内距离与
类间距离的
相对重要性定义为
和
的梯度范数相对于margin-based softmax loss的
比率 (
中的
就是表示前面提到的t函数):
同理相对于原始的softmax loss(公式1)的重要性比率是:
由公式10可以知道定义的
损失函数表达式(公式4)中的
的导函数实际上是具有控制类内距离对于类间距离显著性的作用
4. 搜索空间
基于第3节的分析,我们可以知道可以在公式(3)作如下两处的变换:
其中
和
是需要我们进行搜索的任意函数。另外上式中的
的定义域在
,为了使得其定义域在
进而简化搜索空间,将公式(11)作如下变化 (令公式(12)中的
可以使得公式(11)和公式(12)等价):
另外
和
需要实现设定好,那么最后搜索空间定义为:
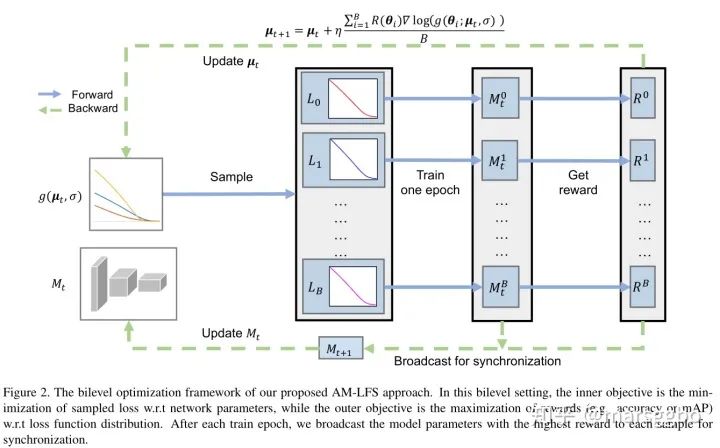
5. 优化
1、内层优化是在固定损失函数后,在训练集上更新模型超参数使得损失函数值最小,得到当前最优的模型参数
2、外层优化则是去找到一组损失函数搜索空间超参数
使得最优的模型参数
在验证集上能取得最大的奖励。
内层优化比较好理解,可是外层优化应该是固定的模型参数,那么最后无论损失函数是什么都不会影响模型输出吧,那怎么最大化奖励呢?文中的做法是这样的(可结合下面的算法流程图来理解):
在每个epoch采样
组损失函数超参数
,其中超参数
服从独立的高斯分布,即
。
先后用
个损失函数来训练当前的模型,得到
,计算每个模型在验证集上的reward,即
。
更新模型权重
:选择reward最大的模型权重作为下一个epoch模型
更新搜索空间
:
,其中
是高斯分布的PDF(概率密度函数),为了简化难度,方差
是固定的,因此只需要更新均值
。
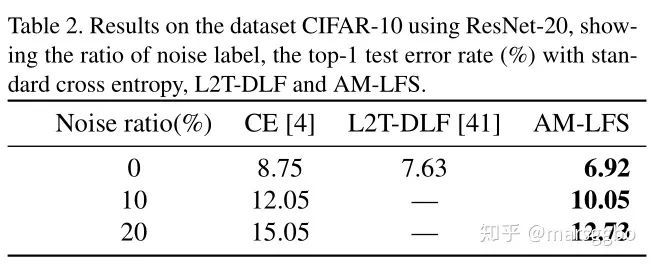
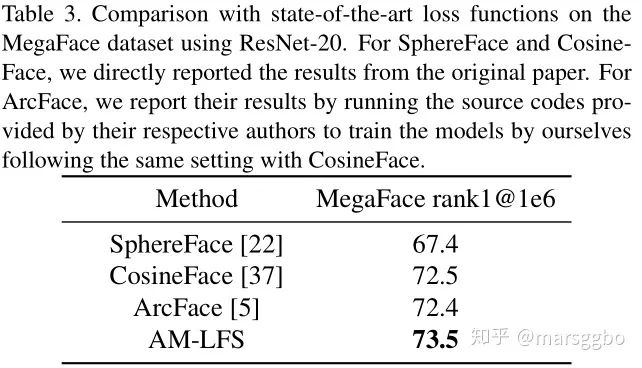
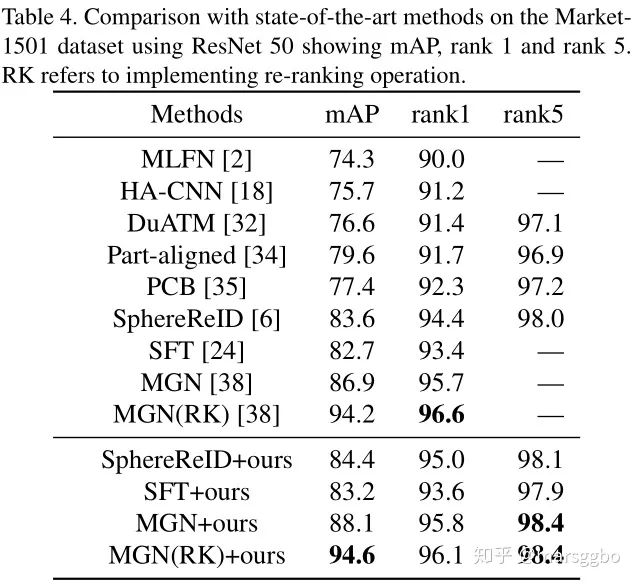
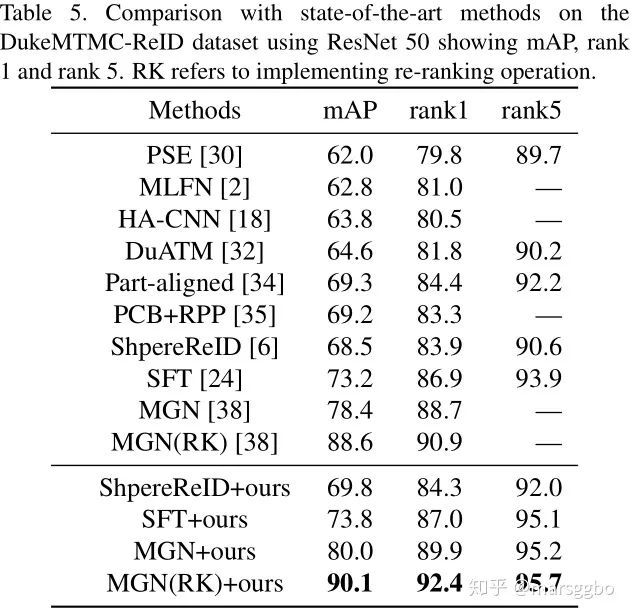
6. 实验结果
Face Recognition:CASIA-Webface用作训练集,MegaFace用做测试集
Person ReID:Market-1501 and DukeMTMC-reID
7. 讨论
本小节是我自己在读完这篇论文后的一些存疑或者觉得需要讨论的点:
1、文中搜索空间的构造引入了两个需要手动设计的超参数(公式12和13),即
和
,这或多或少依赖于手动调参技巧。
2、文中的损失函数搜索只是局限在了对softmax loss函数的变体搜索,而且对于多loss组成的任务,论文仅仅对softmax loss部分做了替换,其余部分保持不变。
3、由算法流程图可以看到,每个epoch都需要基于多个损失函数来训练模型,然后再在验证集上得到reward,这需要大量的计算资源,论文中说了,他们使用了64个GPU,这个emm......大力出奇迹,赞!
本篇文章是基于自己的理解写的,所以可能会有不正确的地方,欢迎指正!
![]()
添加极市小助手微信
(ID : cvmart2)
,备注:
姓名-学校/公司-研究方向-城市
(如:小极-北大-目标检测-深圳),即可申请加入
极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR
等技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
觉得有用麻烦给个在看啦~
![]()