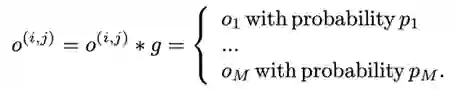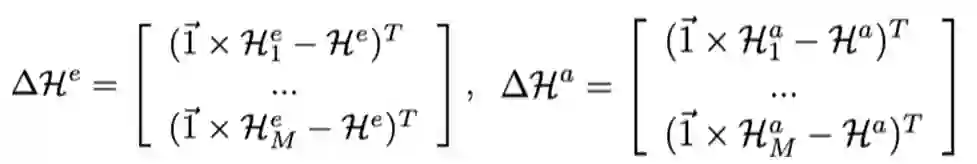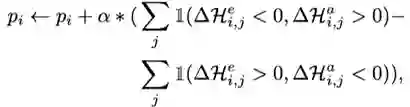加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文是论文一作郑侠武对论文《multinomial distribution learning for effective neaural architecture search》的解读。该论文由厦门大学媒体分析与计算实验室(纪荣嵘团队)、华为诺亚方舟实验室合作完成,旨在降低神经网络结构检索(NAS)中搜索消耗的计算量。论文代码:
https://github.com/tanglang96/MDENAS
摘要
近年来,通过神经架构搜索(NAS)算法生成的架构在各种计算机视觉任务中获得了极强的的性能。
然而,现有的 NAS 算法需要再上百个 GPU 上运行 30 多天。
在本文中,我们提出了一种基于多项式分布估计快速 NAS 算法,它将搜索空间视为一个多项式分布,我们可以通过采样-分布估计来优化该分布,从而将 NAS 可以转换为分布估计/学习。
除此之外,本文还提出并证明了一种保序精度排序假设,进一步加速学习过程。
在 CIFAR-10 上,通过我们的方法搜索的结构实现了 2.55%的测试误差,GTX1080Ti 上仅 4 个 GPU 小时。
在 ImageNet 上,我们实现了 75.2%的 top1 准确度。
背景介绍
给定数据集,神经架构搜索(NAS)旨在通过搜索算法在巨大的搜索空间中发现高性能卷积架构。
NAS 在各个计算机视觉领域诸如 图像分类,分割,检测等取得了巨大的成功。
![]()
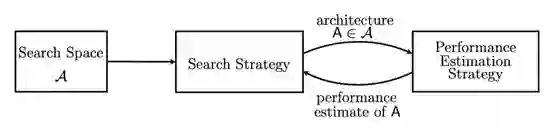
如图一显示,NAS 由三部分组成:
搜索空间,搜索策略和性能评估:
传统的 NAS 算法在搜索空间中采样神经网络结构并估计性能,然后输入到搜索策略算法中进行更新,一直迭代至收敛。
尽管取得了显着进步,但传统的 NAS 方法仍然受到密集计算和内存成本的限制。
例如,强化学习(RL)方法 [1] 需要在 20,000 个 GPU 上训练 4 天,以此训练和评估超过 20,000 个神经网络。
最近 [2] 中提出的可微分的方法可以将搜索空间松弛到连续的空间,从而可以通过在验证集上的梯度下降来优化体系结构。
然而,可微分的方法需要极高的 GPU 显存,并且随着搜索空间的大小线性增长。
主要方法
大多数 NAS 方法使用标准训练和验证对每个搜索的神经网络结构进行性能评估,通常,神经网络必须训练到收敛来获得最终的验证集的评估,这种方式极大的限制了 NAS 算法探索搜索空间。
但是,如果不同结构的精度排序可以在几个训练批次内获取,为什么我们需要在将神经网络训练到收敛?
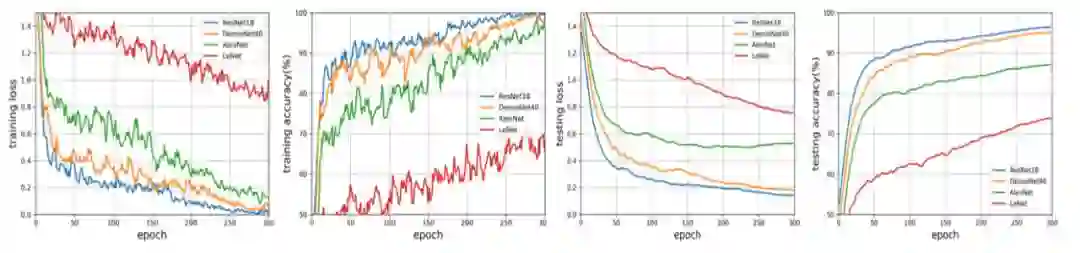
例如下图二,我们随机采样四个网络结构(LeNet,AlexNet,ResNet 和 DenseNet)在不同的次数下,在训练集和测试集中的性能排名是一致的(性能排名保持为 ResNet-18> DenseNet-BC> AlexNet> LeNet 在不同 网络和训练时代)。
![]()
基于这一观察,我们对精度排序提出以下假设:
在训练过程中,当一个网络结构 A 的精度比网络结构 B 要好,那么当收敛的时候,网络结构 A 的表现也优于网络结构 B.
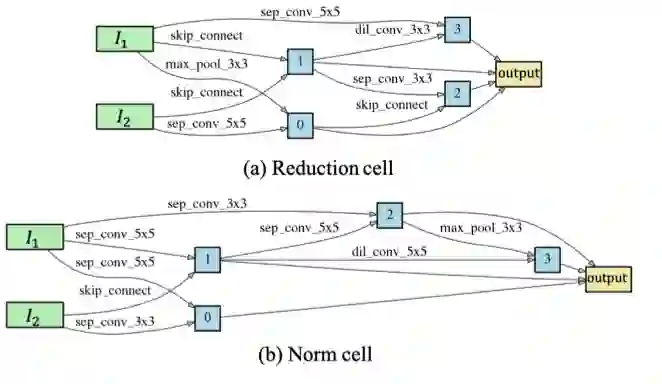
在搜索空间上,我们主要延续了 [2] 中的搜索空间,
![]()
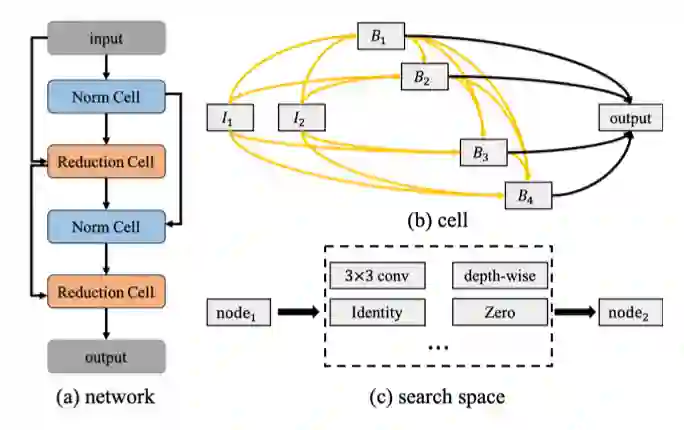
具体搜索空间如图 3 所示:
(a)单元可以堆叠起来形成一个卷积网络,或者递归连接形成一个循环网络。
(b)一个单元(cell)作为最终架构的基石,单元是由 N 个有序节点组成的全
连接有向无环图。
每个节点都是一个特征(神经网络的卷积特征或者其他特征),每个有向边是对该节点的某种运算。
假设每个单元有两个输入节点和一个输出节点。
对于卷积单元,输入节点被定义为前两层的单元输出 [1][2]。
通过对所有中间节点应用及连操作(concatenation)来获得最终的单元的输出。
针对精度排序假设,我们设计了一套基于多项式分布学习的神经网络结构检索算法,首先对于整个搜索空间,我们假设图 3 中的搜索空间为一个多项式分布,最开始的时候,每一个多项式分布的初始概率值保持一致,即假设有 8 个可选的操作,那么搜索空间中每一个的概率为 1/8。
在训练的时候,每一个训练的 epoch,我们首先对网络结构进行采样。
采样结束后,对于一个节点输入的操作为具体边对应采样的点:
![]()
进行采样后,进行训练以及测试,在搜索空间中我们记录下每一个操作被采样的次数以及精度。
并且计算针对训练批次的差分以及精度的差分:
![]()
![]()
从上面的公式中,对于搜索空间中的两个操作,我们主要进行下面的比较,当一个操作 A 与另外一个操作 B 之间进行比较,当 A 的训练批次比 B 要少,但是精度却更高,我们认为 A 比 B 要好,所以增加 A 的概率的同时的减少 B 的概率,反之亦然:
当 A 比 B 要差,把 A 的概率分给 B。
最后当多项式分布仅有一个选择,或者墒少于一定的值的时候(在实验中,基本上 150 个 epoch 之后基本上结构就会稳定不变),我们认为算法收敛。
实验
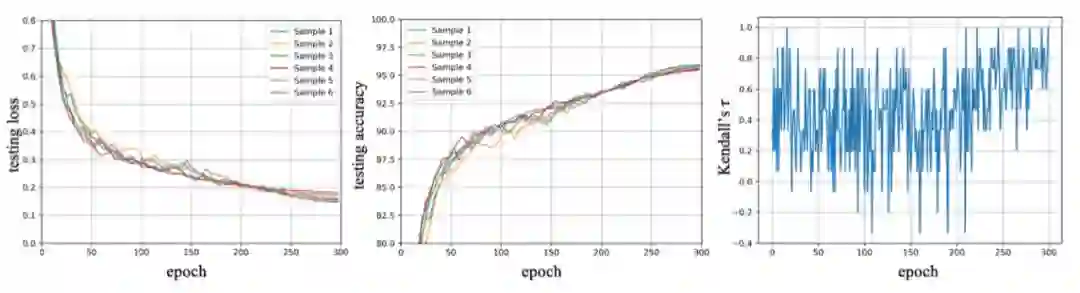
我们首先对精度排序假设进行论证,论证方式为:
随机从搜索空间中采样网络结构,训练这些网络结构,计算每一个中间 epoch 与最终收敛时候的 epoch 的排序精度。
其中评价指标为 kendall』s tau:
具体阐述了两个排序之间的准确度,两个排序中保持一致的对数。
![]()
在上图中我们可以发现,kendall's Tau 在所有的 epoch 中保持了很高的准确度(kendall』s Tau 范围为 [-1,1],0 代表两个 rank 的一致的概率为 50%。
),特别的,我们计算 kendall's Tau 的平均值为 0.47,代表不同的 epoch,评价指标的准确度为 74%。
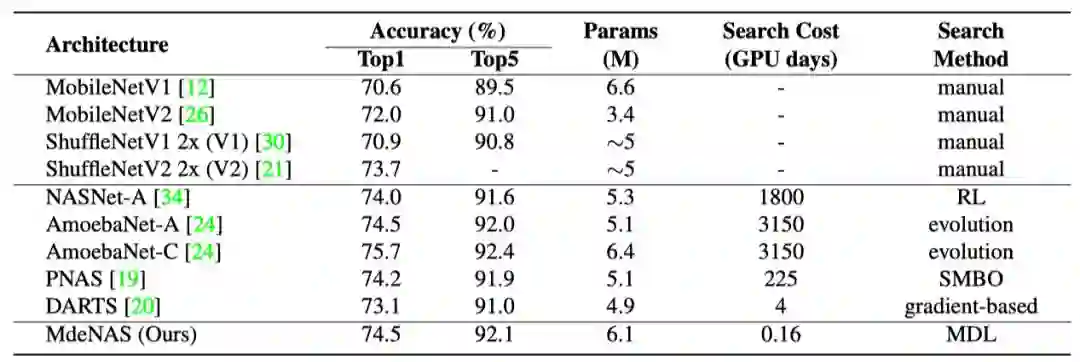
根据之前的文章 [1][2][3],我们主要设置了三个实验,(1) 直接在 cifar10 上面搜索,训练以及测试,(2) 在 cifar10 上搜索,将网络结构进行迁移,迁移到 ImageNet 数据集进行训练测试。
(3)直接在 ImageNet 上搜索训练以及测试。
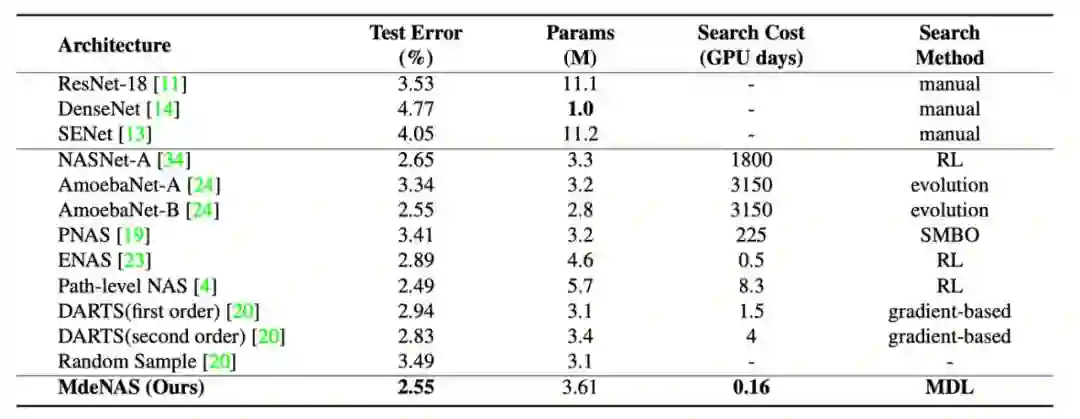
(1)搜索数据集:
cifar10;
训练数据集:
cifar10;
测试数据集:
cifar10;
该实验具体搜索时间上的性能指标以及测试错误率如下表显示:
![]()
![]()
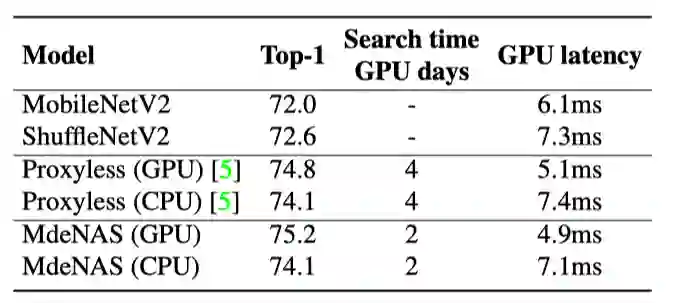
(2)搜索数据集:
cifar10;
训练数据集:
ImageNet;
测试数据集:
ImageNet;
该实验具体搜索时间上的性能指标以及测试错误率如下表显示:
![]()
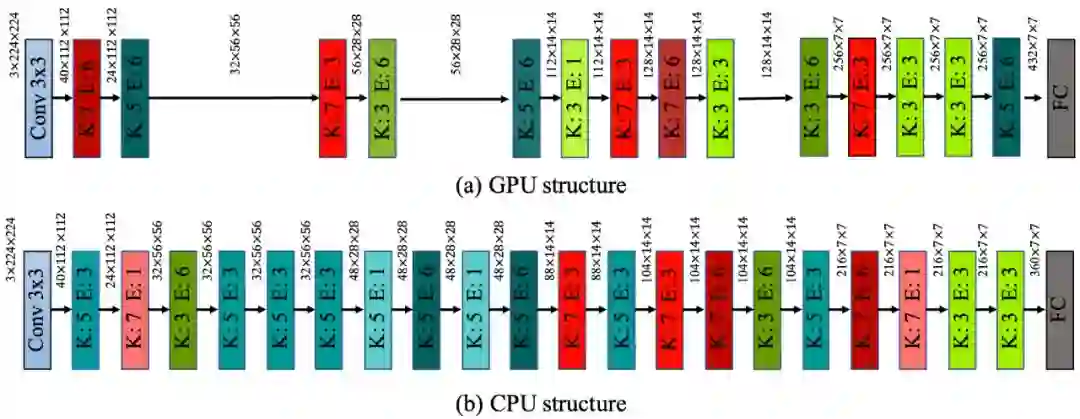
(3)搜索数据集:
ImageNet;
训练数据集:
ImageNet;
测试数据集:
ImageNet;
该实验具体搜索时间上的性能指标以及测试错误率如下表显示:
![]()
![]()
结论
在本文中,我们介绍了第一种基于分布式学习神经网络结构搜索算法。
我们的算法基于新颖的精度排序假设,该假设能够进一步缩短搜索时间,从而利用比较早期训练过程中的架构性能的排序来优化搜索算法。
从我们的假设中受益,提出的搜索算法大大降低了计算量,同时在 CIFAR-10 和 ImageNet 上表现出了出色的模型精度以及高效的搜索效率。
此外,我们提出的方法可以直接在 ImageNet 上进行搜索,相比于人类设计的网络和其他 NAS 方法更优越。
[1] Elsken T, Metzen J H, Hutter F. Neural architecture search: A survey[J]. arXiv preprint arXiv:1808.05377, 2018.
[2] Liu H, Simonyan K, Yang Y. Darts: Differentiable architecture search[J]. arXiv preprint arXiv:1806.09055, 2018.
[3] Han Cai and Ligeng Zhu and Song Han ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. International Conference on Learning Representations 2019.
[4] Xiawu Zheng, Rongrong Ji∗ , Lang Tang , Baochang Zhang, Jianzhuang Liu, Qi Tian Multinomial Distribution Learning for Effective Neural Architecture Search. ICCV 2019
-完-
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()