【泡泡图灵智库】RelocNet:一种通过连续度量学习实现相机重定位的神经网络框架
泡泡图灵智库,带你精读机器人顶级会议文章
标题:RelocNet: Continuous Metric Learning Relocalisation using Neural Nets
作者:Vassileios Balntas, Shuda Li, and Victor Prisacariu
来源:ECCV 2018
播音员:
编译:李建华
审核:彭锐
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——RelocNet:一种通过连续度量学习实现相机重定位的神经网络框架,该文章发表于ECCV 2018。
我们提出了一种用于相机位姿检索的卷积网络表征学习方法,该方法基于最近邻匹配和连续度量学习的特征描述符。我们利用了图像对之间的相机视锥重叠信息,来优化我们的特征嵌入网络,网络最终的相机位姿描述符的差异表示了相机位姿变化。此外,我们构建了一个位姿回归器,该回归器利用几何损失来训练,可基于查询图像和最近邻域图像得到图像之间更精细的相对位姿关系。实验表明,我们的方法能够在不同数据集上进行有意义的泛化,且性能优于其他相关方法。
主要贡献
1、我们采用了基于连续度量学习的方法,使用相机视锥重叠损失函数,以便学习到适用于相机重定位的全局图像特征。
2、通过位姿差异回归网络进一步改善检索结果,该网络直接在位姿矩阵齐次空间中用指数和对数映射图层训练,无需涉及单独的平移和方向项。
3、我们建立了一个新的RGBD数据集RelocDB,数据包含图像序列及对应的位姿真值,专门用来进行相机重定位测试实验。
算法流程
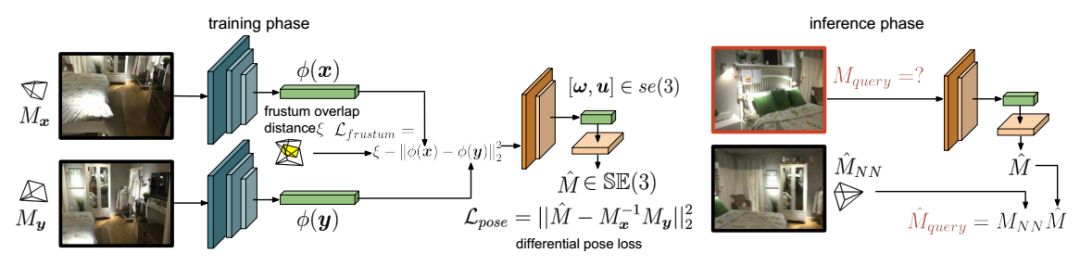
图1 网络架构图。
图1左为训练阶段。使用Siamese架构(偏蓝色的网络)来训练全局特征描述符φ,该描述符的学习由基于相机视锥重叠的连续度量学习损失函数Lfrustum驱动,这样会强制学习到的描述符与细粒度的相机位姿检索相关。后续的网络层(偏黄色的网络)用来根据两个输入推断位姿差异。
图1右为推理阶段。给定一个待检索的图像,使用我们的视锥特征描述符,可以检索得到其最近邻图像,根据位姿差异以及最近邻图像对应的位姿MNN,我们能够计算待检索图像的位姿估计值。
具体步骤如下:
1、使用相机视锥重叠学习相机位姿描述符。普通预训练的网络主要用于图像检索,并不是专门针对位姿检索的。为了让网络能够更好学习到位姿描述符,定义了视锥重叠损失函数:
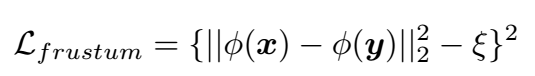
其中,当两个位姿的视锥完全重叠时,ξ为0;完全不重叠,ξ为1。需要指出的是,视锥重叠计算与深度相关,因此对不同场景需要调整计算参数。

图2 视锥示意图,图中数字表示的是视锥重叠比例(1-ξ),0.76重叠比例高于0.22,红色和蓝色线框为视锥
2、位姿差异回归网络
位姿回归的任务是根据输入图像得到位姿输出。采用特殊欧式群SE(3)中矩阵M作为最终的输出,该矩阵为图像间的位姿变换矩阵。网络结构中使用了指数变换层,可以把6维向量映射成4×4的矩阵M。位姿差异的损失函数为
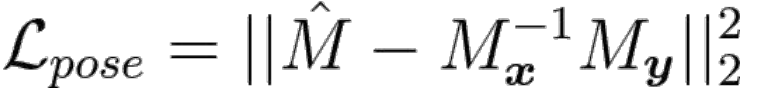
3、网络联合训练
把上述相机位姿描述符和位姿差异回归网络两个损失函数加权起来,联合训练网络。
4、 推理阶段
训练完成后,输入图像,可根据检索得到的最优结果变换得到输入图像的位姿,也可以根据检索的最优k个位姿加权处理得到输入图像的位姿。
主要结果
1、数据集描述
训练数据集:ScanNet
测试数据集:7 secnes 和 RelocDB(自己建立的)。
RelocDB数据集主要用来进行位姿重定位试验,采用Google的Tango设备,采集了500个图像序列。每个序列分为训练集和测试集,通过走相似的路径采集得到,具有相近的数据大小,并对齐到了相同的坐标系下,可用于重定位。
2、定量结果
表1:使用暴力检索方法的最近邻匹配成功率比较。
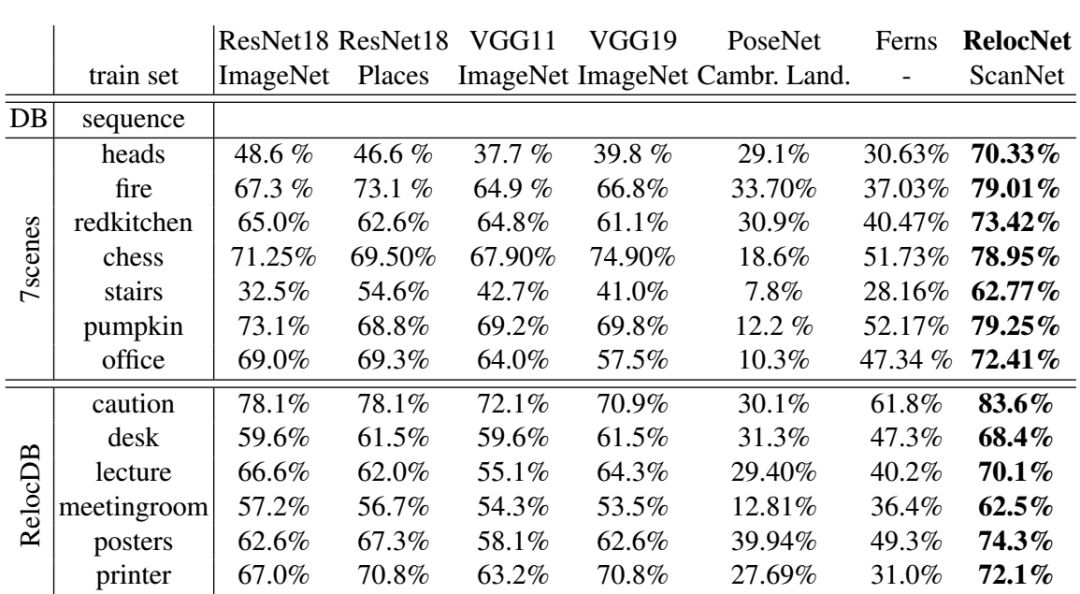
表1中显示了在7Scenes和RelocDB数据集中,视锥重叠阈值设为0.7时的重定位成功率。可以看到,我们的描述符在重定位方面,明显优于其他方法,匹配成功率大致在70%。
表2:7Scenes数据集中的中位数位姿误差。
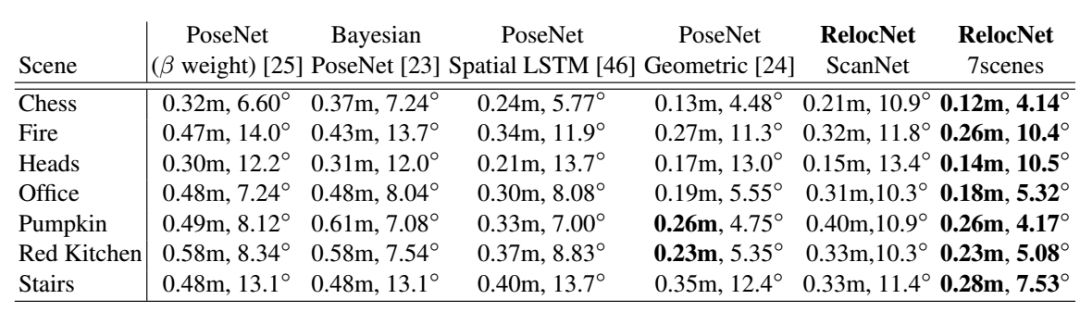
可以观察到,即使测试集和训练集完全不同,我们的RelocNet(倒数第二列)也优于原始版本的PoseNet。这表明我们的方法在不同数据集间的具有可移植的潜力。此外,当训练集和测试集相同时,我们的方法表现最优。最后,值得注意的是使用时间信息(LSTM)带来的性能提升依然小于使用我们的方法。
3、定性结果

图3 定性结果图。第二行图像为检索输入的图像,第一行为根据得到的位姿电脑合成的图像。最后一列为失败案例(可能是因为训练数据和检索数据的视锥重叠太少导致)
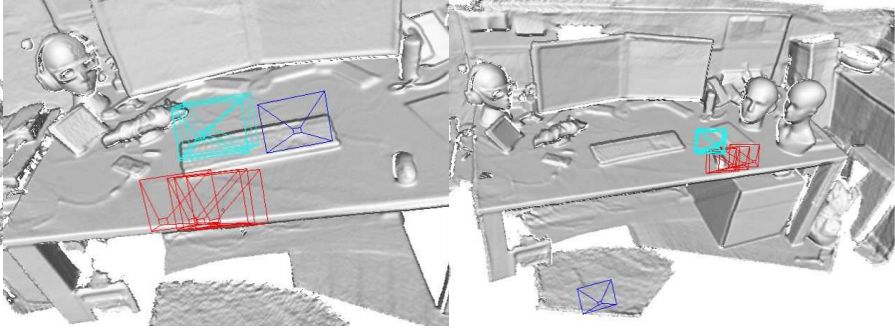
图4 定性结果。 图中蓝色为真值的视锥,红色为检索得到的最近邻视锥,青色为网络估算得到的位姿所对应的视锥。可以看到,我们估算的结果(青色)比最近邻更接(红色)近真值(蓝色)。第二列为失败案例,因为最近邻视锥与真值相差太远。
下一步工作展望:
研究更先进的检索网络训练方法,以及融合多个预测位姿的新方法。优化位姿差异回归网络以提高相机位姿描述符的性能,另外研究使用在线估计方法解决场景缩放问题,并相应地调整学习方法。

Abstract
We propose a method of learning suitable convolutional representations for camera pose retrieval based on nearest neighbour matching and continuous metric learning-based feature descriptors. We introduce information from camera frusta overlaps between pairs of images to optimise our feature embedding network. Thus, the final camera pose descriptor differences represent camera pose changes. In addition, we build a pose regressor that is trained with a geometric loss to infer finer relative poses between a query and nearest neighbor images. Experiments show that our method is able to generalise in a meaningful way, and outperforms related methods across several experiments.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



