ACL 2021 | 难度预测和采样平滑,提高ELECTRA模型的表现!

(本文阅读时间:8分钟)
ELECTRA 模型包含一个生成器和一个判别器,如图1所示。生成器将掩码语言模型任务(Masked Language Modeling,MLM)作为训练目标,通过 MLM 头采样替换词,并输入到判别器;判别器则用来判断输入的单词是否被生成器替换。不同于掩码语言模型的损失只来自被遮盖的部分,ELECTRA 的预训练损失来自整个句子中的每一个单词,因此模型表现有大幅提升。
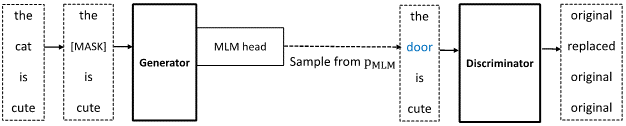
然而在 ELECTRA 的预训练过程中,由于生成器与判别器之间没有直接的信息反馈回路,模型的两部分训练过程完全独立,这就导致生成器的采样较为低效。此外,一个训练完全的生成器会有很高的MLM准确率,所以大多数替换词都是原始输入的单词,进而使得采样效率较为低下。针对上述问题,微软亚洲研究院提出了两种方法:难度预测和采样平滑,通过提高生成器的采样效率来提升模型的表现。相关研究论文 “Learning to Sample Replacements for ELECTRA Pre-Training” 已被 Findings of ACL 2021 收录。

论文链接 :https://arxiv.org/abs/2106.13715

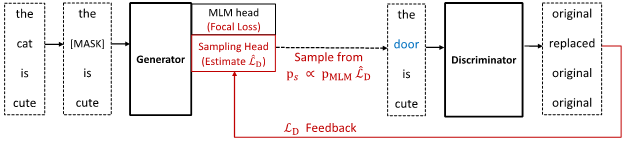
图2:ELECTRA+HP+Focal 模型概览
难度预测的核心是让生成器可以接受判别器的反馈,进而采样更多对于判别器来说较难的替换词。图2为模型主要结构,除了原有的 MLM 头,该结构还额外增加了一个用来采样替换词的采样头。采样头用以估计当采样每一个词表中的单词时,所对应的判别器的损失。因此,采样分布由原来的掩码语言分布变为下述公式:
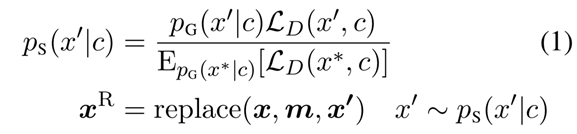
p_G (x' |c) 表示了 MLM 头学习到的掩码语言概率,L_D (x',c) 表示替换词为 x' 时所对应的判别器的损失。论文证明了在上述分布中采样替换词可以将判别器损失的估计方差降为最小。与重要性采样的思想类似,当生成器从一个不同于 p_G 的分布 p_S 中采样时,其对判别器损失的估计方差为:
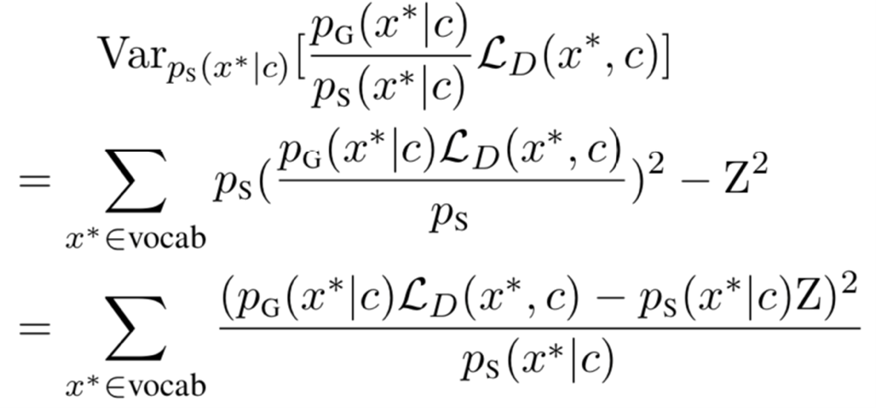
其中,Z 为 L_D (x',c) 在分布 p_G 下的期望。可以看到当 p_S 为分布(1)所示时,判别器损失的估计方差为0。上述采样分布(1)的设计即来自于这个理论最优的形式。需要注意的是,由于真实的 L_D (x',c) 不可能在没有将 x' 作为替换词输入到判别器的情况下得到,所以论文中使用了估计值 L ̂_D (x',c) 来计算采样分布。在预训练过程中,研究员们将实际的判别器损失作为监督信号来训练采样头,通过增加基于难度预测的采样头,生成器可以接收判别器的反馈以实现更高效的采样。
论文中提出了两种不同的采样头:第一种为 HP-Loss,旨在让生成器学习判别器预测某个替换词为原始词的概率。采样头的损失函数如下:
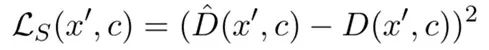
对于每一个替换词 x'(原始输入词为 x),生成器对判别器损失的估计为:
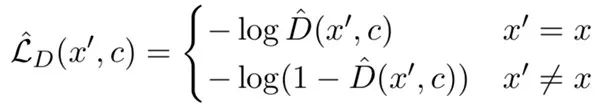
将判别器损失的估计值乘以 MLM 头的输出概率 p_G,即可得到公式(1)中的采样分布 p_S。
第二种为 HP-Dist,旨在让采样头直接近似期望采样分布(1)。在这种情况下,采样头对于每一个替换词 x' 都会通过一个 softmax 层来输出一个采样概率:
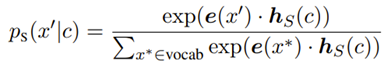
其中 e 为每个词的词嵌入。对于采样出的替换词 x',采样头的损失如下:
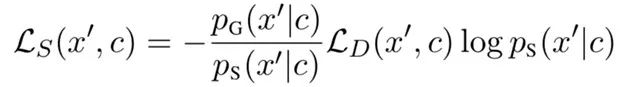
在预训练过程中,生成器的 MLM 头会达到一个较高的准确率。在这种情况下,生成器会过采样那些正确的词作为替换词,使判别器的学习较为低效。为了解决这个问题,研究员们对 MLM 头采用了焦点损失(Focal loss)。相比于之前的交叉熵损失,焦点损失增加了一个调节因子:
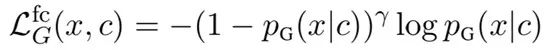
换言之,焦点损失已经可以降低了那些被判别器分类后的简单样例的损失权重,从而更关注较难的训练样例。直观上来看,当一个被掩盖的位置很容易被生成器预测正确时,调节因子会明显降低;但是如果该位置很难预测,焦点损失则近似等于原本的交叉熵损失。因此,论文中应用焦点损失来平滑生成器的采样分布,从而减少了在训练后期生成器总是采样正确替换词问题的出现。
通过应用以上两个方法,模型的训练目标如下所示。与 ELECTRA 一样,在预训练结束后,只使用判别器在下游任务上进行微调即可。
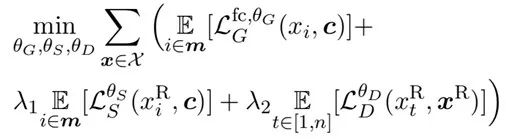
论文在 small-size 和 base-size 上实现了所提出的 ELECTRA + HP-Dist/HP-Loss + Focal 模型。MLM 头和采样头一起共享生成器的参数和词嵌入,但是其预测层参数均不相同,因此避免了不必要的模型复杂度升高。为了做到更可靠的比较,研究员们通过增加相对位置编码,提高了基线模型的表现。
同时,论文在相同数据集(Wikipedia and BookCorpus)和超参数配置下进行了实验,模型在 GLUE 基准上的实验结果如表1所示,在 SQuAD2.0 上的实验结果如表2所示。可以看到,论文中提出的两个方法均可以提升 ELECTRA 模型在下游任务上的表现。
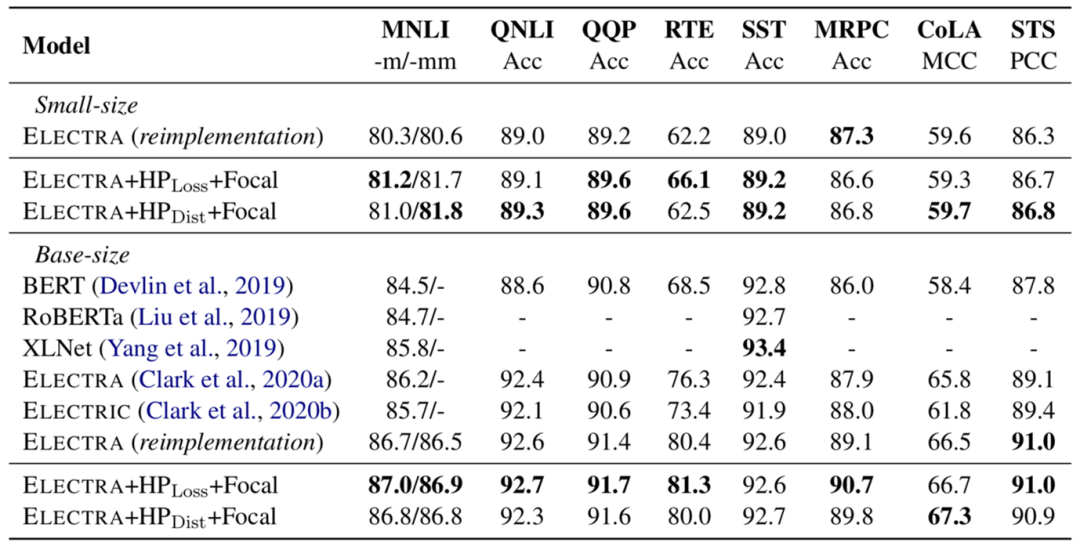
表1:ELECTRA + HP-Dist/HP-Loss + Focal 模型和其他基线模型在 GLUE 基准上的比较
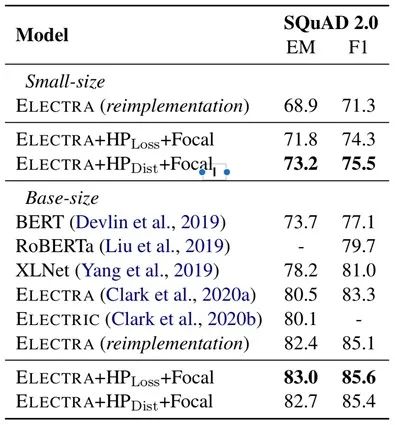
表2:ELECTRA + HP-Dist/HP-Loss + Focal 模型和其他基线模型在 SQuAD2.0 数据集上的比较
为了更好地理解论文中所提出的模型相较于 ELECTRA 模型的优势,研究员们设计了相应的分析实验。首先,论文比较了 ELECTRA 模型和论文模型的生成器的采样分布。ELECTRA 模型和论文模型的生成器在被遮盖位置的最大概率分布如图3所示。可以看到 ELECTRA 模型生成器最大概率在区间[0.9, 1]内的比率要远大于论文模型。换句话说,ELECTRA 模型会过采样这些概率很高的替换词,导致生成器被迫重复地学习这些简单的样例。相比之下,论文模型在每个区间内的分布更为均匀,即模型可以显著降低采样简单样例的概率,使得整个分布更为平滑。
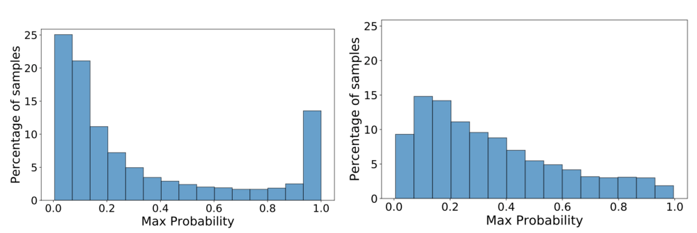
图3:在被遮盖位置,生成器的最大概率分布
论文模型(左),ELECTRA 模型(右)
其次,为了衡量采样头对判别器损失的估计水平,论文计算了真实值和估计值之间的相关系数,结果如表3所示。

表3:判别器损失真实值和估计值的相关系数
最后,为了证明论文模型的采样分布,确实可以采样更多对于判别器来说困难的样例,论文评估了在原始采样分布和所提出的采样分布两种情况下,判别器的预测准确率。从表4中可以看到,无论是在全部位置还是在被遮盖位置进行评估,在论文中提出的采样分布下,判别器的预测准确率都低于 ELECTRA 模型原始的采样分布。结果表明,整个训练过程中,生成器采样到了更多判别器无法准确分类的替换词,同时判别器也尽可能地对困难的样例做出正确的预测。
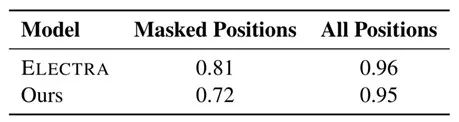
表4:论文模型和 ELECTRA 的预测准确率
你也许还想看:









