本文转载自AI科技评论,机器学习与推荐算法
![]()
2 月 21 日至 25 日,第 15 届 ACM 国际互联网搜索与数据挖掘大会(The 15th International Conference on Web Search and Data Mining,WSDM 2022)在线上召开。本届 WSDM 会议共接收了 790 篇长文投稿,最终录用了 160 篇,录用率约为 20%。
来
自清华大学计算机系的研究团队获得了大会唯
一的最佳论文奖!
这也是自大会创办以来,由来自中国的科研团队首次获得该奖项。
此外,
除了最佳论文奖,WSDM大会还公布
了「时间检验奖」的获奖工作——香港中文大学团队的“Recommender systems with social
regularization”(WSDM 2011)。
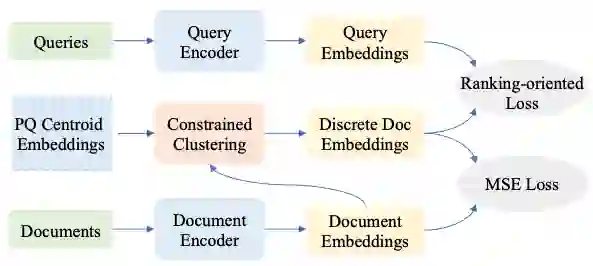
据大会官网信息,清华大学获得今年WSDM唯一最佳论文奖的工作是“Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval”(基于有约束聚类的离散表示学习提升稠密向量检索性能)。
论文链接:
https://arxiv.org/pdf/2110.05789.pdf
论文作者为:詹靖涛,毛佳昕,刘奕群,郭嘉丰,张敏,马少平。
第一作者为清华大学计算机系博士生詹靖涛,通讯作者为清华大学计算机系刘奕群教授,
相关成果由清华大学、中国人民大学、中科院计算所等单位共同完成。
随着深度学习和预训练语言模型等的广泛应用,稠密向量检索已经成为互联网搜索过程中最重要和频繁的数据操作之一,但已有的稠密向量检索模型与传统索引检索模型相比大幅增加了存储开销与时间复杂度,造成了性能提升的重要瓶颈。
针对上述问题,这篇论文提出了一种通过有约束聚类(Constrained Clustering)改进稠密向量检索过程的检索模型RepCONC。
该模型基于有约束聚类方法端到端地联合优化文本编码器和向量量化过程,RepCONC约束稠密向量被均匀地分配到不同的量化中心,从而大幅提升了稠密向量表示的可辨别性,改善了检索性能。
论文从理论上证明了该约束的重要性,并使用最优传输理论推导了有约束聚类过程的近似解以提升算法效率。RepCONC可以在业界通用的向量倒排文件系统(IVF)上运行,即使脱离GPU仅使用CPU也能取得较好的索引压缩与检索效果,比传统稠密向量检索方法在压缩比、检索性能、时间效率等方面均有显著提升。
除了每年选出的唯一最佳论文,大会还分别选出了3篇最佳论文提名(Best Paper Award Runner-Ups):
-
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model(东京工业大学)
论文地址:https://arxiv.org/pdf/2202.01562.pdf
-
Evaluating Mixed-initiative Conversational Search Systems via User Simulation(提契诺大学)
论文地址:https://dl.acm.org/doi/10.1145/3488560.3498440
-
The Datasets Dilemma: How Much Do We Really Know About Recommendation Datasets?(南洋理工大学)
论文地址:https://dl.acm.org/doi/10.1145/3488560.3498519
获得WSDM 2022「时间检验奖」的工作是来自香港中文大学的“Recommender Systems with Social Regularization”。
推荐系统已成为学术界与工业界经久不衰的研究课题。委员会选中这篇论文,是因为它的重要性和对领域的影响力。该论文深入探讨了信任和推荐之间的关系,认识到用户不一定与他们信任的人有相似的品味,但同时又肯定了信任对推荐的重要性。论文作者通过为多个不同的推荐任务建立最合适的社交联系,从而帮助确立了将社交信号纳入推荐系统的价值。因此,这篇论文不但产生了强大的影响力(在 WSDM 时间检验奖的所有提名中被引用次数最多),还提前预见了信任和透明度在推荐系统中的重要性,在近日已成为一个重要的话题。
论文地址:
https://dennyzhou.github.io/papers/RSR.pdf
在这篇工作中,香港中文大学计算机系的研究团队开创性地研究了当时少人问津、现下火热的「社交推荐」问题。目前,社交推荐已成为各个互联网产品的必备技能,微博、抖音、淘宝、微信「看一看」等等都有该功能。
他们基于用户的社交好友信息(从豆瓣等平台挖掘数据),提出了两种社交推荐算法,采用社交正则化项约束矩阵分解目标函数,来帮助提高推荐系统的预测准确性。实验结果表明,他们的方法非常通用,适用于解决多种类型的信任感知推荐问题。
不仅如此,该论文还会反向思考,意识到:社交关系的存在可能会降低推荐质量。从单一信任出发亦可能产生准确率较低的推荐,比如擅长研究球鞋的朋友不一定擅长电影推荐。因此,作者们又很早就用相似度函数,设计了基于不同推荐任务来识别目标朋友群的算法,以对社交系统进行更真实的建模。
在论文中,他们提出:他们相信,随着在线社交网站的快速发展,基于社交的研究会越来越流行。事实证明,确实如此。
完整接收论文列表:https://www.wsdm-conference.org/2022/accepted-papers/
Learning to Learn: 点击率预测模型与网络结构搜索相结合的研究进展
![]()
![]()
![]()