【论文推荐】最新5篇深度学习相关论文推介——感知度量、图像检索、联合视盘和视杯分割、谱聚类、MPI并行
【导读】专知内容组整理了最近人工智能领域相关期刊的5篇最新综述文章,为大家进行介绍,欢迎查看!
1. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (深度特征在感知度量中难以置信的有效性)
作者: Richard Zhang,Phillip Isola,Alexei A. Efros,Eli Shechtman,Oliver Wang
摘要:While it is nearly effortless for humans to quickly assess the perceptual similarity between two images, the underlying processes are thought to be quite complex. Despite this, the most widely used perceptual metrics today, such as PSNR and SSIM, are simple, shallow functions, and fail to account for many nuances of human perception. Recently, the deep learning community has found that features of the VGG network trained on the ImageNet classification task has been remarkably useful as a training loss for image synthesis. But how perceptual are these so-called "perceptual losses"? What elements are critical for their success? To answer these questions, we introduce a new Full Reference Image Quality Assessment (FR-IQA) dataset of perceptual human judgments, orders of magnitude larger than previous datasets. We systematically evaluate deep features across different architectures and tasks and compare them with classic metrics. We find that deep features outperform all previous metrics by huge margins. More surprisingly, this result is not restricted to ImageNet-trained VGG features, but holds across different deep architectures and levels of supervision (supervised, self-supervised, or even unsupervised). Our results suggest that perceptual similarity is an emergent property shared across deep visual representations.

期刊:arXiv, 1 月 12 日
网址:
http://www.zhuanzhi.ai/document/55a5ec8a7580cbe74a6f64e11df39d9b
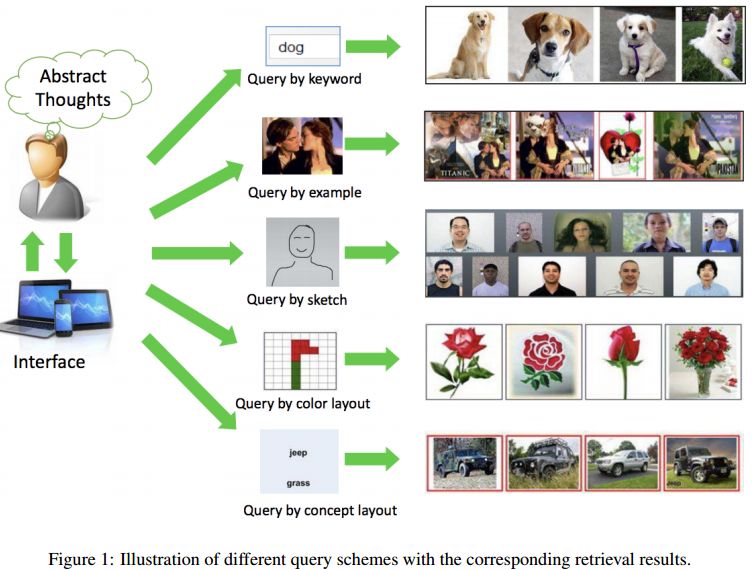
2. DeepSeek: Content Based Image Search & Retrieval(DeepSeek:基于内容的图像检索)
作者: Tanya Piplani,David Bamman
摘要:Most of the internet today is composed of digital media that includes videos and images. With pixels becoming the currency in which most transactions happen on the internet, it is becoming increasingly important to have a way of browsing through this ocean of information with relative ease. YouTube has 400 hours of video uploaded every minute and many million images are browsed on Instagram, Facebook, etc. Inspired by recent advances in the field of deep learning and success that it has gained on various problems like image captioning and, machine translation , word2vec , skip thoughts, etc, we present DeepSeek a natural language processing based deep learning model that allows users to enter a description of the kind of images that they want to search, and in response the system retrieves all the images that semantically and contextually relate to the query. Two approaches are described in the following sections.
期刊:arXiv, 1 月 11 日
网址:
http://www.zhuanzhi.ai/document/2261ccce9805813790a943597a6c73fe
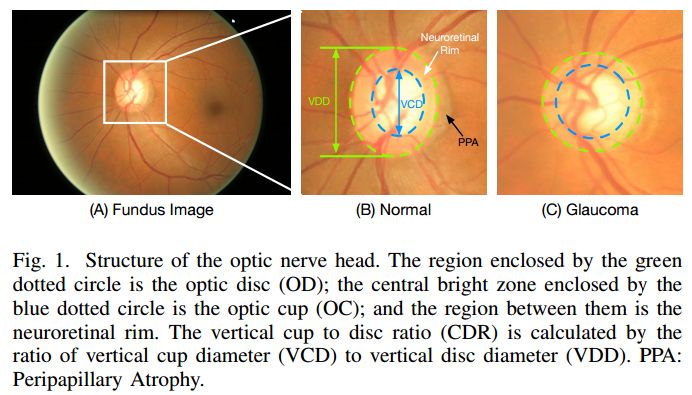
3. Joint Optic Disc and Cup Segmentation Based on Multi-label Deep Network and Polar Transformation(基于多标签深度网络和极性变换的联合视盘和视杯分割)
作者: Huazhu Fu,Jun Cheng,Yanwu Xu,Damon Wing Kee Wong,Jiang Liu,Xiaochun Cao
摘要:Glaucoma is a chronic eye disease that leads to irreversible vision loss. The cup to disc ratio (CDR) plays an important role in the screening and diagnosis of glaucoma. Thus, the accurate and automatic segmentation of optic disc (OD) and optic cup (OC) from fundus images is a fundamental task. Most existing methods segment them separately, and rely on hand-crafted visual feature from fundus images. In this paper, we propose a deep learning architecture, named M-Net, which solves the OD and OC segmentation jointly in a one-stage multi-label system. The proposed M-Net mainly consists of multi-scale input layer, U-shape convolutional network, side-output layer, and multi-label loss function. The multi-scale input layer constructs an image pyramid to achieve multiple level receptive field sizes. The U-shape convolutional network is employed as the main body network structure to learn the rich hierarchical representation, while the side-output layer acts as an early classifier that produces a companion local prediction map for different scale layers. Finally, a multi-label loss function is proposed to generate the final segmentation map. For improving the segmentation performance further, we also introduce the polar transformation, which provides the representation of the original image in the polar coordinate system. The experiments show that our M-Net system achieves state-of-the-art OD and OC segmentation result on ORIGA dataset. Simultaneously, the proposed method also obtains the satisfactory glaucoma screening performances with calculated CDR value on both ORIGA and SCES datasets.
期刊:arXiv, 1 月 11日
网址:
http://www.zhuanzhi.ai/document/fff712a31d01bbe1e5c10665653dfca4/
4. SpectralNet:Spectral Clustering using Deep Neural Networks (SpectralNet:使用深度神经网络的谱聚类)
作者: Uri Shaham,Kelly Stanton,Henry Li,Boaz Nadler,Ronen Basri,Yuval Kluger
摘要:Spectral clustering is a leading and popular technique in unsupervised data analysis. Two of its major limitations are scalability and generalization of the spectral embedding (i.e., out-of-sample-extension). In this paper we introduce a deep learning approach to spectral clustering that overcomes the above shortcomings. Our network, which we call SpectralNet, learns a map that embeds input data points into the eigenspace of their associated graph Laplacian matrix and subsequently clusters them. We train SpectralNet using a procedure that involves constrained stochastic optimization. Stochastic optimization allows it to scale to large datasets, while the constraints, which are implemented using a special-purpose output layer, allow us to keep the network output orthogonal. Moreover, the map learned by SpectralNet naturally generalizes the spectral embedding to unseen data points. To further improve the quality of the clustering, we replace the standard pairwise Gaussian affinities with affinities leaned from unlabeled data using a Siamese network. Additional improvement can be achieved by applying the network to code representations produced, e.g., by standard autoencoders. Our end-to-end learning procedure is fully unsupervised. In addition, we apply VC dimension theory to derive a lower bound on the size of SpectralNet. State-of-the-art clustering results are reported on the Reuters dataset. Our implementation is publicly available at https://github.com/kstant0725/SpectralNet .

期刊:arXiv, 1 月 10日
网址:
http://www.zhuanzhi.ai/document/e624265c1b91d3ad0620ebcf26d194e9
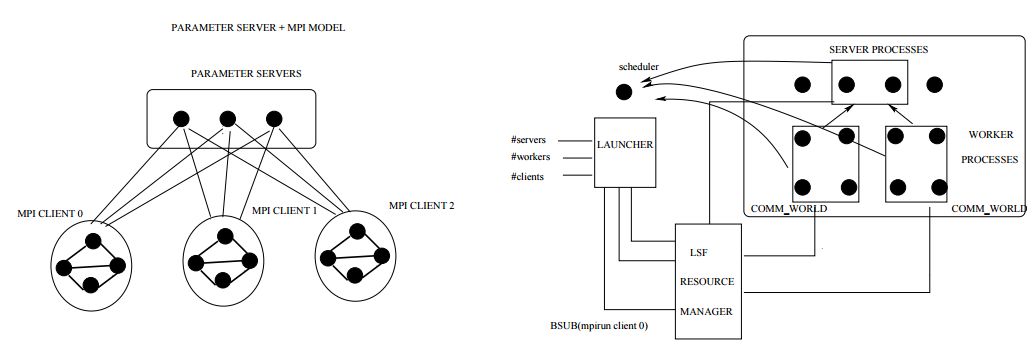
5. MXNET-MPI: Embedding MPI parallelism in Parameter Server Task Model for scaling Deep Learning(MXNET-MPI:scaling深度学习在参数服务器任务模型中的嵌入MPI并行)
作者: Amith R Mamidala,Georgios Kollias,Chris Ward,Fausto Artico
摘要:Existing Deep Learning frameworks exclusively use either Parameter Server(PS) approach or MPI parallelism. In this paper, we discuss the drawbacks of such approaches and propose a generic framework supporting both PS and MPI programming paradigms, co-existing at the same time. The key advantage of the new model is to embed the scaling benefits of MPI parallelism into the loosely coupled PS task model. Apart from providing a practical usage model of MPI in cloud, such framework allows for novel communication avoiding algorithms that do parameter averaging in Stochastic Gradient Descent(SGD) approaches. We show how MPI and PS models can synergestically apply algorithms such as Elastic SGD to improve the rate of convergence against existing approaches. These new algorithms directly help scaling SGD clusterwide. Further, we also optimize the critical component of the framework, namely global aggregation or allreduce using a novel concept of tensor collectives. These treat a group of vectors on a node as a single object allowing for the existing single vector algorithms to be directly applicable. We back our claims with sufficient emperical evidence using large scale ImageNet 1K data. Our framework is built upon MXNET but the design is generic and can be adapted to other popular DL infrastructures.
期刊:arXiv, 1 月 12 日
网址:
http://www.zhuanzhi.ai/document/dcc9fde2f633561366d502be61dace5e
更多论文请上专知查看:PC登录 www.zhuanzhi.ai 点击论文查看
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知




