【论文推荐】最新八篇强化学习相关论文—残差网络、QMIX、元学习、动态速率分配、分层强化学习、抽象概况、快速物体检测、SOM
【导读】专知内容组整理了最近八篇强化学习(Reinforcement learning)相关文章,为大家进行介绍,欢迎查看!
1.BlockDrop: Dynamic Inference Paths in Residual Networks(BlockDrop:残差网络中的动态推断路径)
作者:Zuxuan Wu,Tushar Nagarajan,Abhishek Kumar,Steven Rennie,Larry S. Davis,Kristen Grauman,Rogerio Feris
摘要:Very deep convolutional neural networks offer excellent recognition results, yet their computational expense limits their impact for many real-world applications. We introduce BlockDrop, an approach that learns to dynamically choose which layers of a deep network to execute during inference so as to best reduce total computation without degrading prediction accuracy. Exploiting the robustness of Residual Networks (ResNets) to layer dropping, our framework selects on-the-fly which residual blocks to evaluate for a given novel image. In particular, given a pretrained ResNet, we train a policy network in an associative reinforcement learning setting for the dual reward of utilizing a minimal number of blocks while preserving recognition accuracy. We conduct extensive experiments on CIFAR and ImageNet. The results provide strong quantitative and qualitative evidence that these learned policies not only accelerate inference but also encode meaningful visual information. Built upon a ResNet-101 model, our method achieves a speedup of 20\% on average, going as high as 36\% for some images, while maintaining the same 76.4\% top-1 accuracy on ImageNet.
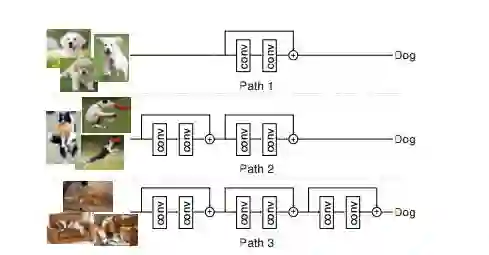
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/4df79a0e7ac6a695592bb121575f330a
2.QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning(QMIX:基于单调值函数因子的深度多智能体强化学习)
作者:Tabish Rashid,Mikayel Samvelyan,Christian Schroeder de Witt,Gregory Farquhar,Jakob Foerster,Shimon Whiteson
摘要:In many real-world settings, a team of agents must coordinate their behaviour while acting in a decentralised way. At the same time, it is often possible to train the agents in a centralised fashion in a simulated or laboratory setting, where global state information is available and communication constraints are lifted. Learning joint action-values conditioned on extra state information is an attractive way to exploit centralised learning, but the best strategy for then extracting decentralised policies is unclear. Our solution is QMIX, a novel value-based method that can train decentralised policies in a centralised end-to-end fashion. QMIX employs a network that estimates joint action-values as a complex non-linear combination of per-agent values that condition only on local observations. We structurally enforce that the joint-action value is monotonic in the per-agent values, which allows tractable maximisation of the joint action-value in off-policy learning, and guarantees consistency between the centralised and decentralised policies. We evaluate QMIX on a challenging set of StarCraft II micromanagement tasks, and show that QMIX significantly outperforms existing value-based multi-agent reinforcement learning methods.

期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/c17c70fe3802166c570a0c6153c49697
3.Learning to Adapt: Meta-Learning for Model-Based Control(学习适应:基于模型控制的元学习)
作者:Ignasi Clavera,Anusha Nagabandi,Ronald S. Fearing,Pieter Abbeel,Sergey Levine,Chelsea Finn
摘要:Although reinforcement learning methods can achieve impressive results in simulation, the real world presents two major challenges: generating samples is exceedingly expensive, and unexpected perturbations can cause proficient but narrowly-learned policies to fail at test time. In this work, we propose to learn how to quickly and effectively adapt online to new situations as well as to perturbations. To enable sample-efficient meta-learning, we consider learning online adaptation in the context of model-based reinforcement learning. Our approach trains a global model such that, when combined with recent data, the model can be be rapidly adapted to the local context. Our experiments demonstrate that our approach can enable simulated agents to adapt their behavior online to novel terrains, to a crippled leg, and in highly-dynamic environments.

期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/a2a848a9b0ea080048e08686ef4c946c
4.Cache-Enabled Dynamic Rate Allocation via Deep Self-Transfer Reinforcement Learning(通过深度自转移强化学习来实现缓存的动态速率分配)
作者:Zhengming Zhang,Yaru Zheng,Meng Hua,Yongming Huang,Luxi Yang
机构:Southeast University
摘要:Caching and rate allocation are two promising approaches to support video streaming over wireless network. However, existing rate allocation designs do not fully exploit the advantages of the two approaches. This paper investigates the problem of cache-enabled QoE-driven video rate allocation problem. We establish a mathematical model for this problem, and point out that it is difficult to solve the problem with traditional dynamic programming. Then we propose a deep reinforcement learning approaches to solve it. First, we model the problem as a Markov decision problem. Then we present a deep Q-learning algorithm with a special knowledge transfer process to find out effective allocation policy. Finally, numerical results are given to demonstrate that the proposed solution can effectively maintain high-quality user experience of mobile user moving among small cells. We also investigate the impact of configuration of critical parameters on the performance of our algorithm.
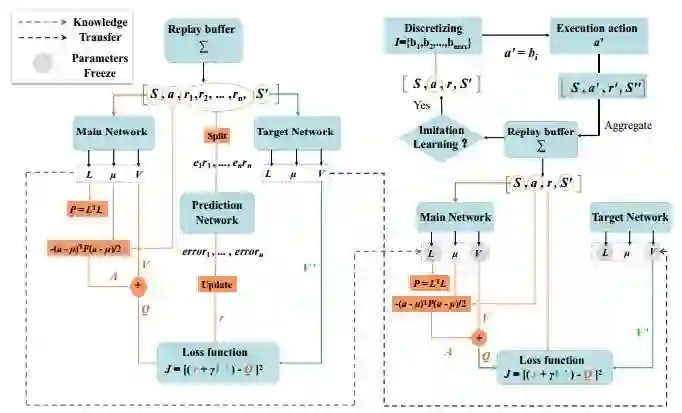
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/ee889b39f1abd03fa8fd105bb824cb8d
5.Video Captioning via Hierarchical Reinforcement Learning(基于分层强化学习的视频描述生成)
作者:Xin Wang,Wenhu Chen,Jiawei Wu,Yuan-Fang Wang,William Yang Wang
机构:University of California
摘要:Video captioning is the task of automatically generating a textual description of the actions in a video. Although previous work (e.g. sequence-to-sequence model) has shown promising results in abstracting a coarse description of a short video, it is still very challenging to caption a video containing multiple fine-grained actions with a detailed description. This paper aims to address the challenge by proposing a novel hierarchical reinforcement learning framework for video captioning, where a high-level Manager module learns to design sub-goals and a low-level Worker module recognizes the primitive actions to fulfill the sub-goal. With this compositional framework to reinforce video captioning at different levels, our approach significantly outperforms all the baseline methods on a newly introduced large-scale dataset for fine-grained video captioning. Furthermore, our non-ensemble model has already achieved the state-of-the-art results on the widely-used MSR-VTT dataset.
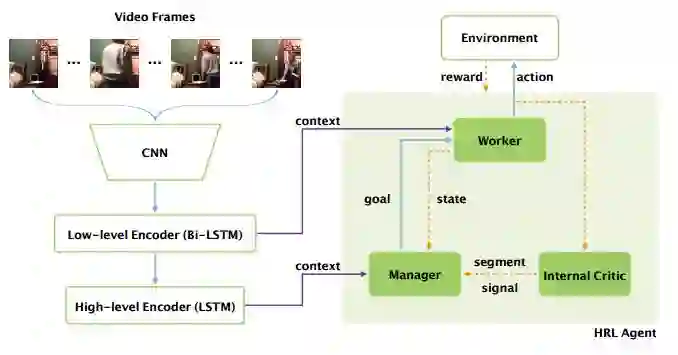
期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/0e06d68487c1f38c870eed320088047e
6.Deep Communicating Agents for Abstractive Summarization(深度沟通智能体的抽象概况)
作者:Asli Celikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi
机构:University of Washington
摘要:We present deep communicating agents in an encoder-decoder architecture to address the challenges of representing a long document for abstractive summarization. With deep communicating agents, the task of encoding a long text is divided across multiple collaborating agents, each in charge of a subsection of the input text. These encoders are connected to a single decoder, trained end-to-end using reinforcement learning to generate a focused and coherent summary. Empirical results demonstrate that multiple communicating encoders lead to a higher quality summary compared to several strong baselines, including those based on a single encoder or multiple non-communicating encoders.
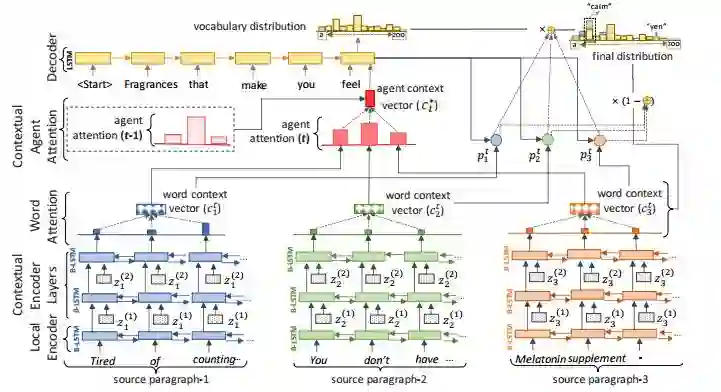
期刊:arXiv, 2018年3月28日
网址:
http://www.zhuanzhi.ai/document/2cb61ebaa88eb3db3f515f9f78fa641e
7.Dynamic Zoom-in Network for Fast Object Detection in Large Images(基于动态Zoom-in网络在大图像上的快速物体检测)
作者:Mingfei Gao,Ruichi Yu,Ang Li,Vlad I. Morariu,Larry S. Davis
摘要:We introduce a generic framework that reduces the computational cost of object detection while retaining accuracy for scenarios where objects with varied sizes appear in high resolution images. Detection progresses in a coarse-to-fine manner, first on a down-sampled version of the image and then on a sequence of higher resolution regions identified as likely to improve the detection accuracy. Built upon reinforcement learning, our approach consists of a model (R-net) that uses coarse detection results to predict the potential accuracy gain for analyzing a region at a higher resolution and another model (Q-net) that sequentially selects regions to zoom in. Experiments on the Caltech Pedestrians dataset show that our approach reduces the number of processed pixels by over 50% without a drop in detection accuracy. The merits of our approach become more significant on a high resolution test set collected from YFCC100M dataset, where our approach maintains high detection performance while reducing the number of processed pixels by about 70% and the detection time by over 50%.
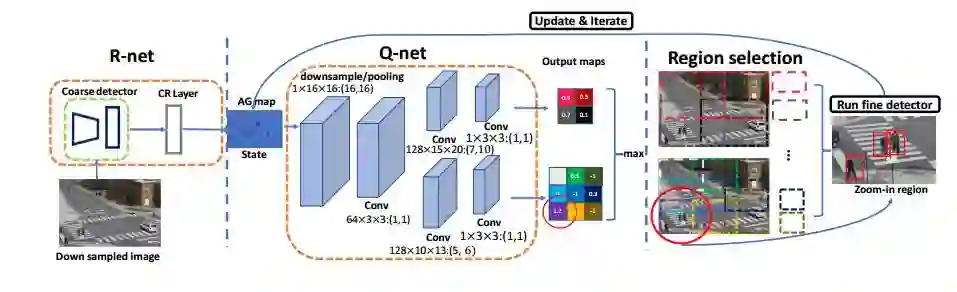
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/3f713d0b55396afaeab8803effe5cc38
8.Modeling Others using Oneself in Multi-Agent Reinforcement Learning(在多智能体强化学习中对他人进行建模)
作者:Roberta Raileanu,Emily Denton,Arthur Szlam,Rob Fergus
摘要:We consider the multi-agent reinforcement learning setting with imperfect information in which each agent is trying to maximize its own utility. The reward function depends on the hidden state (or goal) of both agents, so the agents must infer the other players' hidden goals from their observed behavior in order to solve the tasks. We propose a new approach for learning in these domains: Self Other-Modeling (SOM), in which an agent uses its own policy to predict the other agent's actions and update its belief of their hidden state in an online manner. We evaluate this approach on three different tasks and show that the agents are able to learn better policies using their estimate of the other players' hidden states, in both cooperative and adversarial settings.
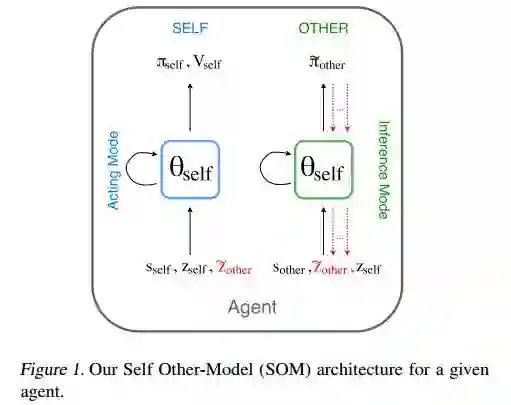
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/630e7bc3e8897b1c5c564c86a98cafaf
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!




