▐ 1. 背景
随着整个互联网行业的发展,各大互联网公司作为服务提供商,积累了越来越多能够服务用户的优质内容,如电商领域的各类商品、视频领域丰富的视频、直播等。而随着信息量的爆炸,算法技术作为连接内容和用户的桥梁,在服务质量的提升上发挥着至关重要的作用。随着业界在搜索、推荐、广告技术上多年的迭代积累,逐步形成了较为稳定的召回(匹配)、粗排、精排这一多阶段的系统架构,而召回模块及其相关的算法,在各类业务中处于链路最前端,其决定着整体服务质量的天花板。
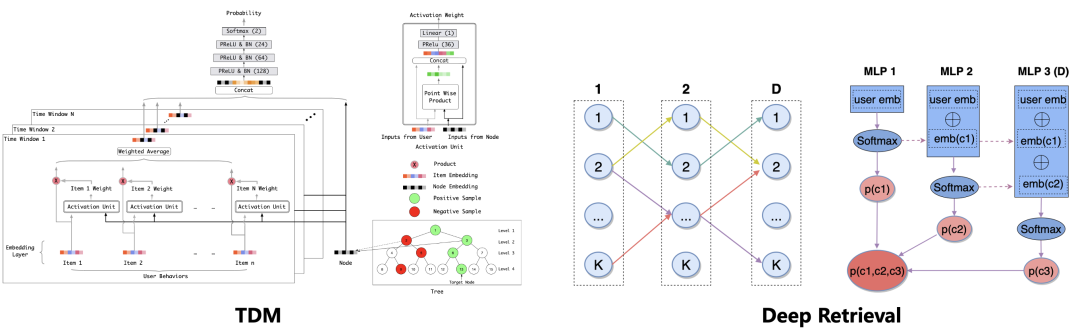
就召回技术而言,其核心问题是如何从大规模的候选集中,找到一个足够优质且大小有限的子集供后链路做进一步处理。因此,召回阶段与其他模块的本质差异,在于其面对的是极大的全量候选集。业界在解决这一问题的过程中,经历了启发式规则类召回、协同过滤类召回、模型类召回等多个阶段。近年来,随着机器学习,尤其是深度学习技术的发展,学术界及工业界已经全面进入到了 model-based 召回算法的研究与应用阶段。目前,业界存在两种主流的模型召回解决思路:两段式解决方案和一段式解决方案。其中以向量检索为代表的两段式解决方案将模型结构限定为双塔结构,然后通过高效的大规模内积近邻检索来完成 Topk 查询。其主要问题是模型能力受到了较强的限制,因此模型能力天花板受限。为了突破模型结构的束缚,一些同时建模索引结构与模型的一段式召回方案被提出,其中以我们阿里妈妈展示广告团队此前提出的 TDM 系列算法为代表,通过显式建模索引结构来提供高效的剪枝能力,减少在线打分量进而承载复杂模型,打开了召回精度的天花板。
在持续的大规模召回算法探索与迭代过程中,我们逐渐发现,类似 TDM 的一段式解决方案,在具备高精度召回能力的同时,由于索引结构与模型训练的强耦合,导致离在线链路过于厚重,对维护、迭代以及快速的业务支持带来了比较大的挑战。因此在2021年,我们一直在思考的一个主题是:有没有一种更进一步的召回解决方案,能在支持复杂模型的同时,实现对模型训练与索引结构学习的解耦。基于这一理念,我们研发了二向箔算法体系,在保留复杂模型召回能力的同时,将索引学习和模型训练解耦,提供了轻量化的任意复杂模型召回解决方案。二向箔算法体系已在阿里妈妈展示广告业务中全量上线应用,成功支持了双十一大促,相关算法升级带来了信息流核心商业化场景 RPM+3.1%/CTR+2.4% 的业务效果提升。
▐ 2. 模型召回的形式化目标及主流解法 2.1 模型召回的形式化目标
召回模型技术由于其应用模式,天生具备“集合属性”,即在单纯的“预估”概念之上,还需要更进一步地基于预估结果从全量候选集中拿到优质子集。首先给召回模型技术的目标做一个简单的形式化定义:假定函数
为一个针对用户
和候选项
的价值度量函数,则召回目标可以定义为
其中
为全量候选集。总的来说,这一目标可以概括为:对于每一次请求,从候选集中找到给定价值度量下价值最高的一个子集。当然,在实际的召回系统与算法迭代中,也还存在一些启发式的召回模式如 i2i 召回,以及对于集合的多样性等指标要求等,本文暂不进行探讨。从上述的召回目标定义中不难发现,召回阶段的模型技术迭代,需要考虑两个重要的问题:1)对于召回模型而言,如何通过更好的网络结构、训练样本或loss设计,使得模型能更好地拟合或者反映真实的价值度量函数,即如何让模型预估
更接近 ground truth 的
;2)当训练好的预估模型
给定时,如何得到更精准的
集合,即常规意义上的检索问题。
业界的召回模型技术发展,在根据上述召回目标进行优化时,迭代出了两种主流的解决思路。可将其概括为两段式的解决方案和一段式的解决方案,接下来会进行一个简单的介绍。
2.2 两段式解决方案
所谓两段式的解决方案,是将目标中的
部分和
训练部分完全分开来考虑,其代表做法是向量检索的模式,即通过特定的模型结构设计,将价值度量函数表达成用户表征向量与候选 item 向量内积计算的模式,然后通过高效的大规模内积近邻检索来完成 Topk 查询。针对向量内积的 KNN 检索,有不少通用高效且成熟的解决方案,如开源的 Faiss[1] 和阿里内部的 Proxima[2]。因此,对于两段式的召回方案,大家迭代的重点一般都聚焦在模型结构、训练样本、损失函数的迭代上,比如:MIND[3]、ComiRec[4]、CurvLearn[5] 等优秀的工作,都是在这一框架下往不同的方向做了一些尝试和突破,如用户多兴趣表征、内积之外的相似度量空间等。
这类两段式的召回解决方案,由于其对召回问题分阶段的建模思路非常清晰,且各阶段都有相对成熟的工具和方法来支持迭代,因此在实际系统中被广泛使用。但是对于这一类建模方式,在原理上存在两个不足:
1)第一阶段向量形式的
模型训练过程中,一般不会考虑第二阶段检索过程的精度损失,因此可能会导致近似近邻检索(ANN)的误差较大,这也是通常所说的两阶段目标不一致的问题。针对这一问题,业界有一些工作已经尝试解决,例如在模型训练阶段就把检索误差纳入考虑[6]等。但是在实际应用中,即使训练阶段不考虑检索误差,一些ANN检索工具如 Proxima[2] 一般都能将精度做到 95% 甚至更高。所以在实际应用中两个阶段目标不一致并不算是一个严重的问题;
2)由于 ANN 检索的需求,
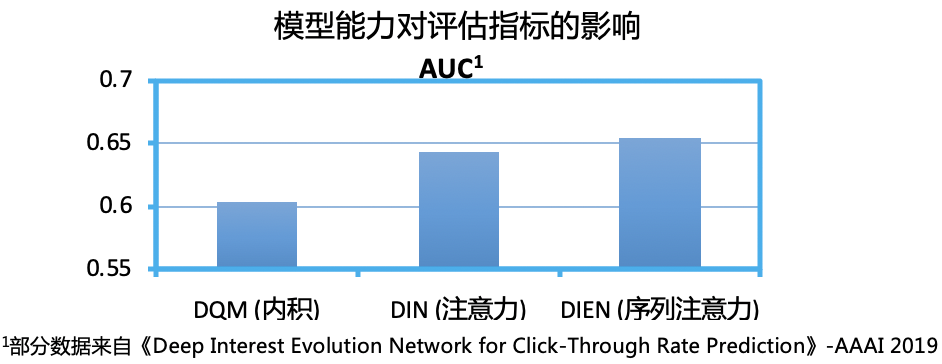
模型结构最终需要被设计成用户向量与 item 向量之间直接计算的模式,而这一要求对模型能力造成了较大的限制。事实上,如果不考虑检索模式对模型结构的要求,召回模型结构设计与后链路的一些模型如点击率、转化率预估模型等,可能并没有太本质的差异,但正是由于向量结构限制的存在,使得召回模型能力的天花板受到了较大限制。虽然目前还没有发现严格的证明与推导,能够论证向量结构到底在多大程度上影响了模型能力,但很多的实践结果都表明了这一限制切实存在且影响很大。下图中,我们给了一个简单的实验数据验证,来说明模型结构限制对模型能力的影响程度。不难发现,当结构从内积升级成带 target attention 的 DIN 结构后,模型精度有了一个大的提升。
2.3 一段式解决方案
鉴于两段式解法存在的目标不一致、模型结构受限的问题,业界在技术迭代的过程中,也发展出了一段式的召回解决方案,其中代表性的工作为我们团队之前提出的 TDM 系列算法[7-9]和字节跳动提出的 Deep Retrieval 算法[10]。所谓的“一段式”,是相较两段式的价值度量模型训练、Topk 检索分开考虑而言,直接面向检索目标来同时学习索引结构和检索模型。这类方法一个比较大的特点是需要定义“参数化的索引结构”,并在训练中和模型进行同步优化。像 TDM 中的树结构、DR 中的多层编码结构,以及索引结构中虚拟节点的 embedding,都属于索引结构参数的一部分。此外,在 TDM、DR 中,item 与树的叶节点、与最底层编码节点之间的挂载关系映射函数,同样属于索引结构参数的一部分,是需要通过训练过程来优化的。正是由于索引结构与模型联合优化的模式存在,这类一段式解决方案通常不存在两阶段目标不一致的问题。同时,显式建模的检索过程往往能实现高效的候选集剪枝,所以可以使用计算力要求更高的复杂模型结构,而不局限于向量计算的模式。
一段式的解决方案同时解决了两段式中存在的两阶段目标不一致、模型结构受限两大问题,但在长期实践过程中,也发现了这一方式存在的不足,主要也是有两点:
1)索引结构与模型联合训练,从原理上实现了对召回目标的 end-to-end 一致优化,但是也给训练带来了额外的系统、时间成本。在 TDM 和 DR 中,都是通过 EM 算法来交替优化索引结构、检索模型,最终实现索引和模型的共同收敛,这一过程通常需要过多轮训练,相比两段式方案中的
模型训练及训练后的一次性索引构建而言,一般会需要更多的时间。此外,在训练引擎中实现索引结构训练算法,并同时考虑新增item在索引中的引入问题,会带来不少额外的工程成本;
2)模型结构不再局限于内积形式,是一段式解决方案在召回精度上最大的优势,但是实际上对模型结构依然有一些要求。由于索引结构中间节点是虚拟节点,因此不能方便地使用一些在向量模型中普遍应用的目标 item 侧的 side information 特征,如淘内的商品类目属性、店铺属性、title 等,而这类特征通常在实践中被证明是非常有效的。虽然在实际工程应用中,依然有一些办法能利用上这类特征,如进行 top 特征上溯等,但同时也意味着额外的系统复杂性。
▐ 3. 二向箔算法体系3.1 为什么叫二向箔
二向箔是科幻小说《三体》中的一种降维打击武器,能将空间结构从三维压缩成二维。将上述两种召回解法和维度做一个简单类比:对于基于向量的两段式解决方案,由于检索范式比较固定,因此大家在迭代的过程中主要考虑的是如何在向量结构的框架下,去迭代模型能力,近似于在一维空间中做优化,技术轻量但天花板受限;而对于一段式的解决方案,由于显式索引结构和复杂模型的引入,在迭代中通常需要同时将索引学习、模型结构优化、系统可提供算力的约束这三者同时纳入考虑,近似于在三维空间中做优化,效果天花板高但系统过于厚重。在过去的算法迭代中,通过对上述两类方案的长期探索与应用,我们愈发频繁地在思考一个问题:有没有一种更简洁有效的解决方案,能够在保持一段式解决方案中复杂模型召回能力的同时,不需要在训练中考虑索引结构的优化,进而降低整个系统的复杂度并提升迭代效率?这也是“二向箔(Dual Vector Foil, DVF)”算法体系名称的由来,我们希望在新的体系下,召回算法可以不受限制地迭代
模型,同时只需要考虑系统可提供的算力这一唯一约束。面对这一问题,我们找到了一个可行路径:保留索引的同时,将索引和模型训练解耦,即给定任意召回模型
,通过模型无感知的索引结构构建及 相对应的检索能力,来支持高效、高质量的 KNN 检索,返回模型打分最高的 K 个结果
。
3.2 Post-training的索引构建
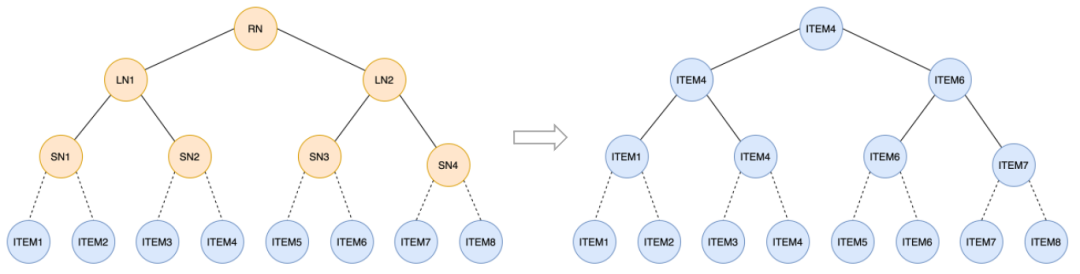
为了使模型训练不再依赖于索引,我们选择在模型训练后再构建没有任何虚拟节点的索引。一种很自然的想法是,将 TDM 树索引构建方式修改为通过层次 k-medoids 聚类的方式构建,其中叶节点依然为所有 item,但中间节点不再是虚拟节点,而是类簇的中心 item。但是,这种索引构建方式要求 item embedding 有层次化的类簇结构,实际上模型在训练时并没有加入相关约束,因此学出的 item embedding 并没有层次化类簇结构。从离线实验结果来看,这种索引构建方案的效果也比较差。
k-mediods层次聚类构建树索引
因此,我们的目光转向了对模型和 item embedding 都没有任何约束的图检索。具体来说,我们选用检索精度较高的 HNSW 检索图[11]来根据所有候选项的 embedding 构建索引(构建算法见原始论文)。如下图所示,HNSW 检索图是一个层次化的图检索结构,第0层包含所有节点,上层节点为下层节点的随机采样,每层采样比固定(如32、64);每层都是一个近似 Delaunay 图 [12],图中每个节点都有节点与之相邻,且相邻节点距离相近(如欧式距离)。
HNSW层次化图检索结构
3.3 检索实现
检索过程如下,给定打分模型
、HNSW 检索图
、用户
,从上往下逐层检索(通过 SEARCH-LAYER 函数)得到每层打分最高的候选项
,作为下一层的检索起始点;最后,将最底层的检索结果中打分最高的
个候选项作为该用户
的最终检索结果。
每层的检索算法如下,给定打分模型
、用户
、检索起始点
。使用
记录本层访问过的节点,
记录待拓展近邻的候选集,
动态记录本层检索结果。初始化
、
、
均为检索起始点
。
核心检索过程包含多次循环。每次循环中,首先获取候选集
中所有节点的所有未访问过的近邻
,并将
中所有节点设为已访问,然后维护
为旧
和
中打分最高的
个节点,最后更新待拓展近邻的候选集
为
,即
中打分较高的节点集。因此,每层检索共包含
次近邻查询、模型打分和集合交并差操作,这些操作在 Tensorflow 中可以高效实现。
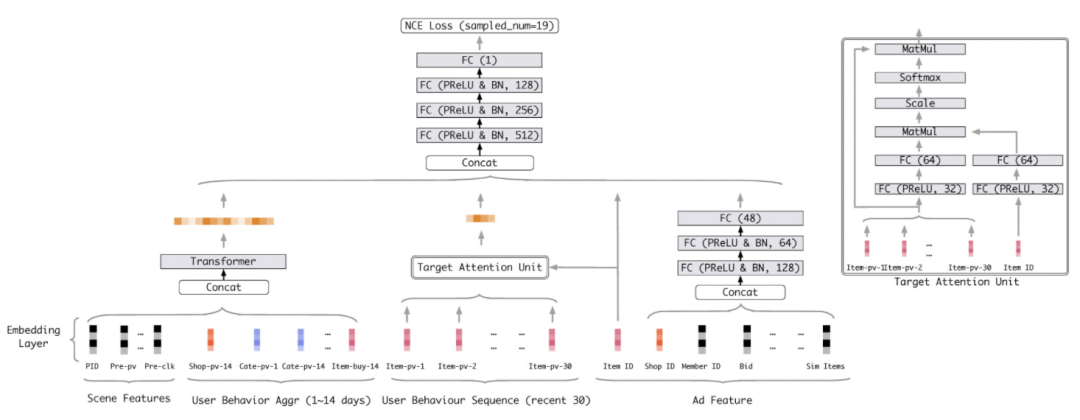
3.4 模型结构 采用的打分模型结构如下图,其主要由以下四部分构成:
用户聚合特征提取: 用户聚合特征包含用户性别、nickname 等聚合特征。在获取原始 embedding 后采用 transformer 提取 user 侧深度特征。
用户行为序列特征提取: 用户行为序列特征与目标 target 间采用了 target attention 的方式进行交互,以获取与目标 target 最相关的行为特征。该部分模型结构见下图右边,将序列特征中的 item 和 target 都通过 MLP 进行特征提取后,利用 Scaled Dot-Product Attention 得到最终用户行为序列特征。
Target 特征提取: 使用多层 MLP 进一步提取 target 侧的特征。这是与 TDM 等一段式召回方案中模型结构区别最大的部分。由于 TDM 中模型训练与索引强耦合,且索引中存在虚拟中间节点,因此 item 侧 side information 特征比较难以直接应用,需要一些类似 top 特征上溯的机制来支持。在二向箔算法体系对模型结构没有任何限制,因此可以很自然的加入各种 item 侧特征。
MLP 打分: 将上述三路深度特征合并后,经由多轮 MLP 得到最终打分。
二向箔模型结构
▐ 4. 二向箔工程链路4.1 整体链路
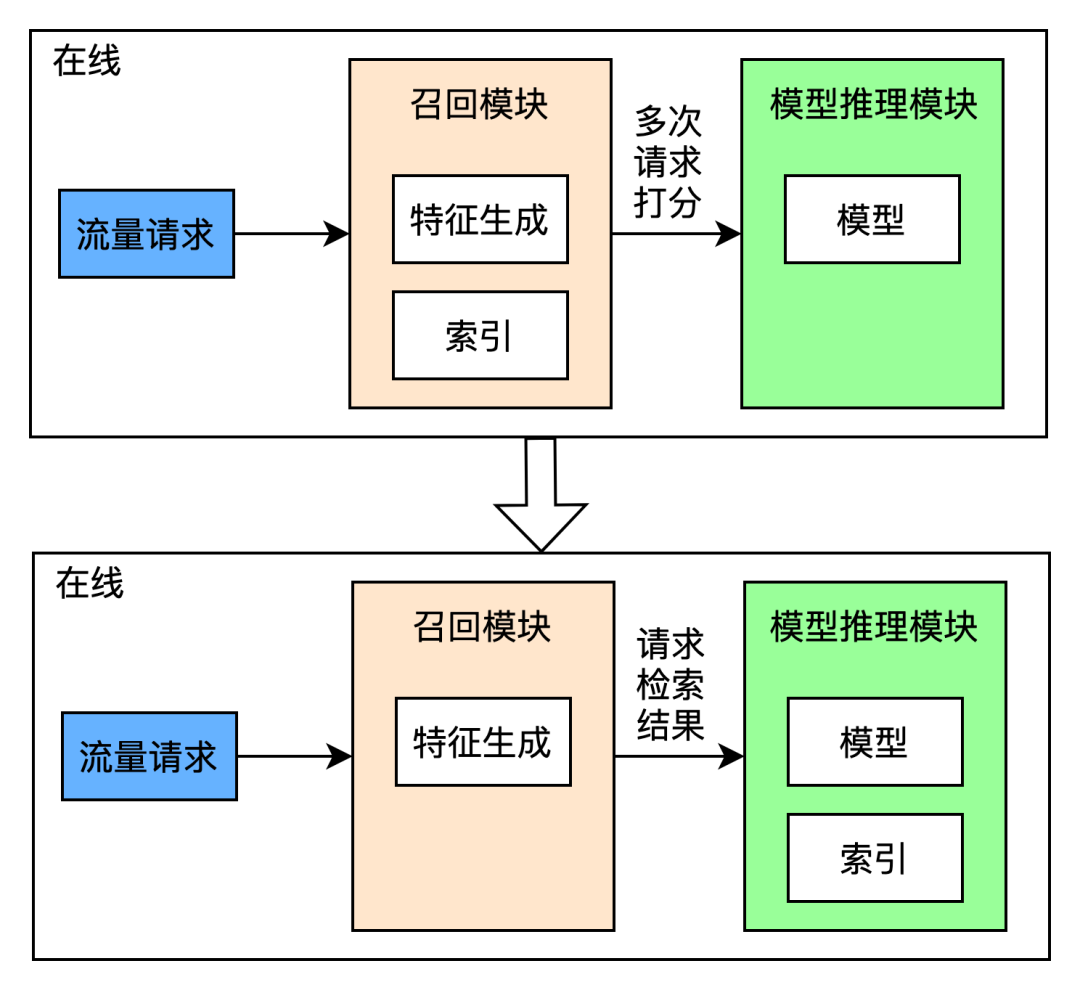
从链路设计上, 我们将索引与模型两个部分放入模型推理模块中,实现模型推理模块的“features in、tokens out”,减少了请求的传输成本,相较之前的链路,通信部分 rt 减少 12ms。从整体链路上看,“features in、tokens out”的方式简化了链路,即召回模块只负责特征生成及对返回 token 的正/倒排查询,将所有打分及检索逻辑在模型推理模块完成。该设计与排序模型的做法是一致的, 这种简化的链路设计完全兼容向量 ANN 检索。与此同时,索引与模型在同一模块进行部署避免了跨模块同步更新时出现系统卡顿或者版本一致性问题的可能。
4.2 在线检索与打分流程 4.2.1 图表示
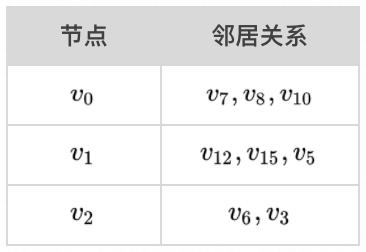
我们利用 Tensorflow 的不规则张量(ragged tensor)来表示检索图
的节点及邻居关系。ragged tensor 主要由 values 和 row splits 两个 tensor 构成,对应到二向箔的场景,values 是 flatten 了所有节点的邻居节点的集合,同时用 row splits 的下标来表示节点
本身。举例说明:
values:[7, 8, 10 ,12, 15, 5, 6, 3]
其表示的图关系如下:
4.2.2 检索
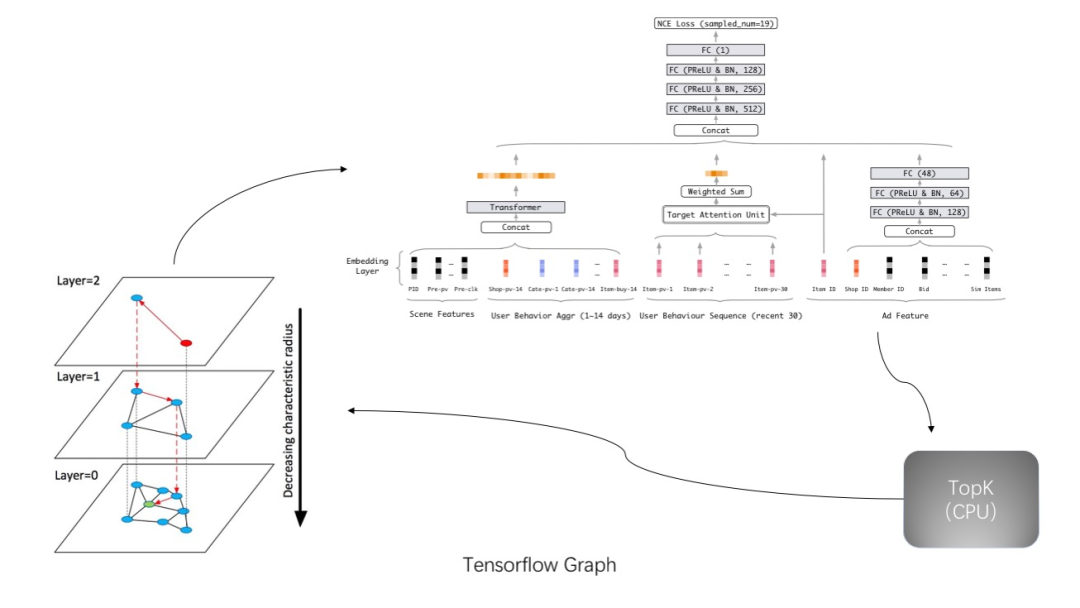
如下图所示,在实际运行时,在 CPU 端进行检索以得到扩展且未曾打分的邻居集合
,然后在 CPU 端 gather 出对应的 embedding,通过 PCIe 将 embedding 由 host 传至 device(GPU),在 GPU 上完成打分,并同样通过 PCIe 将打分结果从 GPU 传至 CPU,然后进行 TopK 运算,进而进入下一轮检索。具体实现中,将检索过程归纳为了多个算子,如:set difference、set union等。针对原生 Tensorflow 没有或者性能较差的 Op 进行了定制化,整个检索过程均由 Tensorflow Op 构成。此外,set 相关 Op 也经历了多轮迭代,最终采用了 bitmap 来实现了 set difference/set union 相关逻辑,详细的压测数据将会在后文给出。
4.2.3 打分
采用了 DNN 模型进行打分,该 DNN 模型由 user 侧的 transfomer、target attention、多层 fc 构成。模型结构见 3.4 节。在打分过程中,target 没有实时特征,也没有 feature generation 的过程,而是在离线计算所有 target 侧 embedding,并在 host 上以 tensor 的形式缓存。而 user 侧则接入了实时序列特征来保证兴趣捕捉的实时性。
▐ 5. 离在线实验及性能指标对比5.1 离线实验 5.1.1 实验设置
样本构造: 我们采用用户兴趣最大化召回样本进行模型训练和效果测试。正样本包含两部分,一部分是用户在手淘首页猜你喜欢场景点击过的 item,另一部分是用户在全网存在收藏、加购、购买行为对应的样本。训练时,一条样本仅包含一个 ground truth,而负样本是从其他用户的 ground truth 中带权重随机采样得到。
Recall计算: 在测试时,根据离线 recall 来评估检索效果。由于一条样本只有一个 ground truth,因此 recall 其实与正样本的命中率等价。在下述离线实验中,采用召回 top-1500 item 中正样本的命中率作为 recall。
训练、测试流程: 通过多机多卡同步训练模式对模型进行训练。训练结束后,计算所有 item 的经过网络变换后的 embedding 并保存。接着根据保存的 embedding 构建索引,并基于索引对十万条测试样本进行检索,计算平均 top-1500 recall。此外,为了验证索引检索的有效性,还测试了线上不可行的全库打分方案的 recall 作为对比。
5.1.2 实验结果
为了高效进行大规模内积近邻检索,现有两段式解决方案的模型结构被限制为用户向量与 item 向量之间直接内积计算的向量结构,而这一要求大幅限制了模型表达能力。而在二向箔算法体系下,模型结构没有任何限制,可以和后链路的点击率、转化率预估等任务用相似的模型。上述结果对比了 DNN 结构和向量结构的离线 recall。其中 DNN 结构为本文采用的模型结构(见第 3.4 节);多兴趣向量结构与DNN结构拥有相同的特征输入,同时采用 transformer 来提取用户的多峰兴趣向量(参考 comiRec[4]),然后多个兴趣向量分别召回 top-1500 再统一排序产出最终 top-1500。由上表可知,去掉向量结构限制后,召回模型的检索精度天花板获得大幅提升,全量打分情况下离线 recall 绝对值提升 5.71%,DNN 结构下二向箔检索的离线 recall 也比向量结构下的全量打分 recall 高 3.03%。
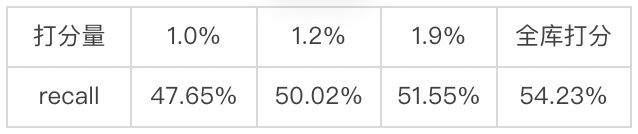
在二向箔算法体系下,仅需 1.9% 打分量就可以达到 95% 的检索精度(51.55% / 54.23%)。说明虽然构建索引时只基于 item 侧 embedding,没有引入 user 侧和 ad 侧的交互或者打分信息,但是也足以胜任检索过程中大幅减少打分量的需求。
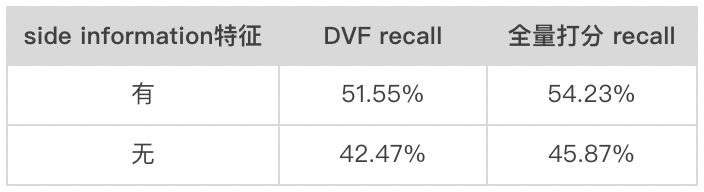
目标item侧的side information特征的重要性
虽然 TDM 和 DR 等一段式解决方案的模型结构不再局限于内积形式,但由于索引和模型强耦合,且索引中存在虚拟中间节点,导致不易使用目标 item 侧的 side information 特征 。而在二向箔体系下,由于图索引对模型结构没有任何限制,因此可以很自然的加入 item 侧的 side information 特征。由上表可知,去掉 item 侧的 side information 特征后,全量打分 recall 和 DVF 检索 recall 都大幅下跌(绝对值约 9%),这一定程度体现出了二向箔算法体系相对于 TDM 和 DR 等一段式解决方案的优越性。
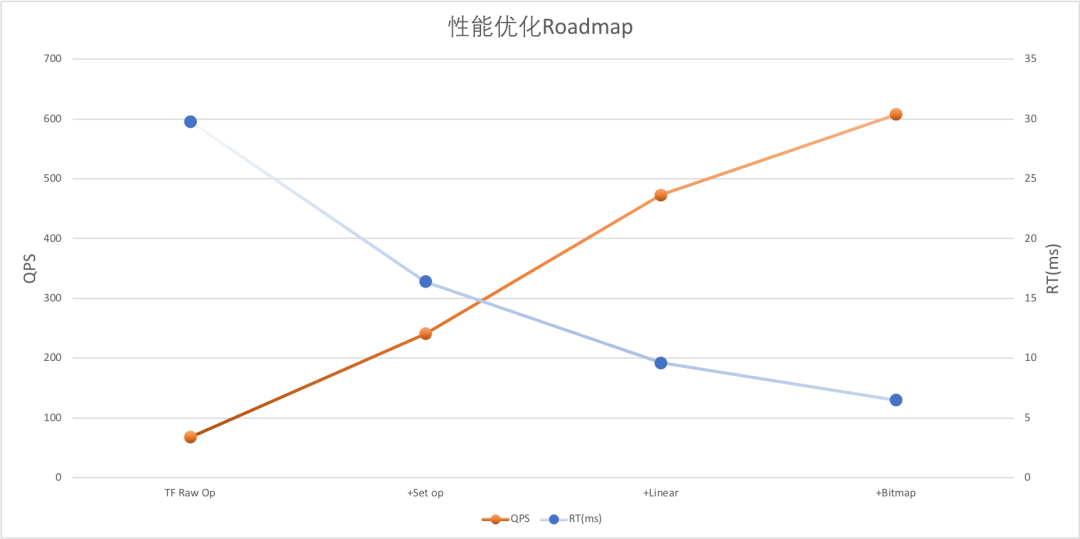
5.2 在线性能优化 在线性能优化主要是分为如下几个阶段:
TF Raw Op :利用 TF Raw OP 串联了整个流程,离线验证了二向箔算法体系的正确性与可行性。
+Set Op: TF Raw Op 中涉及到检索的 Op(例如,Set/Where)性能较差,替换为了自己开发的 Custom Op 等。
+Linear attention: 针对模型打分部分性能较差的问题,通过 linear attention 的方式解决了模型 GPU 访存的短板。
+Bitmap OP: 在 Set Op 基础上,对检索 Op 再升级,进一步升级了性能。
注:以上数据压测环境及设置为:T4 单卡、半精度推理、开启 XLA 优化、单次召回打分总量约 1.7 万
5.2.1 索引 索引优化主要分为两个阶段:
通过对 TF Raw Op 版本 profiling,发现最大的性能瓶颈是检索相关的 Op。因此,我们将检索过程归纳为了多种 Set Op,包括 set difference、set union等,并以 Tensorflow Custom Op 的形式实现了相关功能,保证检索与打分是在同一个 TF Graph 中完成。通过这种方式,将性能从 RT 39.8ms、QPS 68 提升至 RT 16ms、QPS 241,达到基本可用的状态。
Bitmap Op 是在模型优化为 linear attention 结构后对检索部分的再升级。在模型优化为 linear attention 后,此时单机压测发现,极限 QPS 下 GPU 利用率会在 77% 左右无法继续提升,分析可得此时 CPU 的检索能力成为整个模型的瓶颈。由上文介绍可知,整个在线检索所用图的节点是用下标来作为唯一 id 的,即每个节点
对应一个 int32 的正整数
。基于此特点,我们利用 bitmap 来重构了模型检索过程中所涉及到的集合操作,包括 set difference、set union。
具体而言,我们生成一个 size 为
的 tensor 其数据类型位 int32。对于节点
,其对应的 bit 位是 tensor 中下标为
(整除)的数值的第
(取余)位。在线初始化时将整个 tensor 置于 0,一旦被检索则将被检索的节点所对应的 bit 位标记为 1,从而实现了 set difference、set union 等功能。该改进使得模型在极限 qps 下 GPU 的利用率可以达到 95%,解决了模型检索的短板,使得最终版本在单次召回打分总量 1.7w 的情况下,T4 单卡 RT 6.5ms、QPS 608。
5.2.2 模型
二向箔项目在模型侧的最根本改变之一是引入了 target attention 结构,这是召回端引入复杂模型的最大优势之一,即通过 attention 机制来建模 user sequence 与 target 之间的关系。但 attention 结构会制约模型 GPU 打分的性能。以召回模型所用的 attention 结构举例:
:即模型的 target,shape 为[batch, dim]
:即用户的行为序列,shape 为[seq, dim]
对于大规模召回问题而言,batch 维度往往是非常大的,当前 DVF 模型的单次打分最大可达万级,因此 batch 的维度很容易成为性能的瓶颈。常规的 attention 结构,在产生最终 attention score 的过程中会多次生成有 batch 维度的中间结果。而当前,妈妈在线 GPU 服务主要以 T4 卡集群为主,对于 T4 卡而言其 DRAM 带宽较低,使得数据访问很容易成为性能瓶颈。而在召回场景下,其实际情况也是如此,尤其是在引入了 attention 结构后,不可避免的会产生第0维为 batch 的 tensor。解决这个问题的途径分为两种:1)通过 kernel fusion,尽量少的产生中间结果,直接生成最终的 attention score;2)从算法上设计访存更友好的 attention 结构,减少中间结果的产生。其中,方案一虽然可以减少访存和 kernel launch 开销,但是不够灵活,且由于 attention 机制中往往涉及到很多非线性操作,因此 kernel fusion 的难度较大。因此,最终我们采用了方案二,借鉴了 NLP 领域中的 linear attention 方式,减少了第0维为 batch 的中间结果的产生,优化了模型在 GPU 部分的性能。最终,我们通过 attention 结构的优化将性能由 RT 16.4ms、QPS 241 优化至 RT 9.6ms、QPS 473,满足了在线扩流需求。
5.2.3 XLA auto-padding
XLA(Accelerated Linear Algebra)是 Google 推出的高性能机器学习领域编译器,它可以在不更改源代码的条件下,通过 kernel fusion 的方式加速 Tensorflow 模型。
阿里妈妈展示广告从去年开始就大量使用 XLA 技术进行在线加速,对于我们的模型而言,XLA优化可以带来2倍以上 QPS 的提升。但 XLA 代码生成有一个限制:整个 Tensorflow graph 中不能出现 dynamic shape。然而,在现实生产环境中,dynamic shape 无处不在,一旦在线出现未曾 cache 的 shape,XLA 机制会触发 Just-In-Time (JIT) 代码生成,这会导致在线服务出现强烈抖动,会影响共同部署的所有模型的性能。之前,阿里妈妈RTP团队通过 padding + warmup 的形式来解决这个问题,即在模型输入时(对应 Tensorflow 的 placeholder)对输入维度进行 padding,在线只会将几种固定的shape输入到模型中,从而绕过了 JIT。
但对于召回模型而言,其情况要复杂的多。召回模型 dynamic shape 的出现并不是在模型输入时(placeholder),而是在检索过程中,也就是前文提到的每一轮扩展出来的打分的集合N,其 size 是不固定的,且完全由流量控制。为了解决该问题,我们与阿里妈妈RTP团队共建了 XLA auto-padding 功能。其主要工作原理如下:
在线: XLA auto padding 会将 shape 变化相同的 tensor(例如,召回模型的batch维度)统一 padding 到某一个事先规定的维度(事先规定了多组 padding 维度,在线根据 batch 大小,padding 至其距离最近的维度),然后调用对应的已 cache 住的经由 XLA 优化的模型结构(由 warmup 过程产生),在模型执行到某一个 XLA cluster 外后,对其按照原来维度进行 slice,从而得到正确结果。
Warmup: XLA auto-padding 功能的 warmup 过程实际是为了生成 XLA cluster 输入端的 shape 信息。在模型上线前,会在试验田利用压测流量,直接触发模型的 JIT,将事先规定好的 padding 维度所对应的的 XLA cluste r输入的 shape 信息落盘,并进行打包作为模型文件随模型一起上线,相当于利用压测流量进行 warmup。模型上线时,会在加载模型时利用 warmup 过程生成的 XLA cluster 输入的 shape 信息对在线模型进行 warmup 并 cache 在 GPU 中,这样在线就无需利用流量进行 warmup 了,进而规避了在线 JIT 过程。
通过 XLA auto-padding 功能,将 XLA 能力拓展至了 dynamic shape 的场景,从而使得 XLA 加速能力可以更好的应用至生产环境中。
▐ 6. 总结与展望6.1 总结
从模型角度看,二向箔算法体系在大规模召回场景中做到了真正意义上的任意复杂模型的 KNN 检索。此外,Post-training 的索引构建模式使得整个解决方案非常轻量级,模型迭代更为高效,即在迭代模型结构的过程中无需考虑模型与索引的联合优化,从而可以将精力更多的投入到样本和目标构建、特征体系设计及模型结构迭代上。从检索角度看,二向箔范式的检索效率较高且精准,虽然不是端到端地将检索与模型一起训练,但从实验结果和实际应用看,非端到端的训练对召回精度的影响并不大。并且,正是由于索引构建与模型训练的解耦,使得离在线链路均变得更简洁清晰。从技术沉淀角度看,二向箔范式沉淀了一系列解决召回问题的技术栈,并且完全基于 Tensorflow 框架,可以很容易的迁移到其他业务场景中,具有较高的推广潜力。
6.2 展望
对于模型迭代而言,未来二向箔范式将从模型结构升级与在线算力优化两个方面进行迭代。模型层面,我们将迭代更为精准的模型结构,并在召回模型的学习目标上更加对齐业务需求。算力优化层面,目前在 T4 卡上基于 CuBLAS、XLA 等优化手段的性能升级已基本见顶,未来将在召回端引入阿里自研的 NPU 计算能力,提升算力的经济性。
对于索引迭代而言,二向箔发展的方向是打分量与检索精度的双向优化。从算法角度来说,当前的检索模式还是具有较大的探索空间的。例如,当前用 L2 距离建图是否有可以改进的空间,是否可以通过部分采样样本的模型打分建图;检索过程中一旦陷入局部最优会有较多的 quota 是重复的,是否可以进一步扩大有效的 quota 减少 overlap 等。从算力角度看,二向箔范式将会进一步支持更大规模的检索问题,从提升检索量及打分量的角度,释放在线效果。
下一步,我们将会推广二向箔算法体系的业务服务范围,更进一步地,二向箔模式完全基于 Tensorflow 框架,因此具有较高的推广及开源潜力。未来,希望可以为开源社区提供一套轻量级的支持任意复杂模型的大规模召回解决方案。
7. 引用 [1] https://github.com/facebookresearch/faiss
[2] https://www.alibabacloud.com/blog/proxima-a-vector-retrieval-engine-independently-developed-by-alibaba-damo-academy_597699
[3] Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
[4] Controllable Multi-Interest Framework for Recommendation
[5] https://github.com/alibaba/Curvature-Learning-Framework
[6] Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
[7] Learning Tree-based Deep Model for Recommender Systems
[8] Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
[9] Learning Optimal Tree Models under Beam Search
[10] Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations
[11] Efficient and Robust Approximate Nearest Neighbor Search using Hierarchical Navigable Small World Graphs
[12] https://en.wikipedia.org/wiki/Delaunay_triangulation
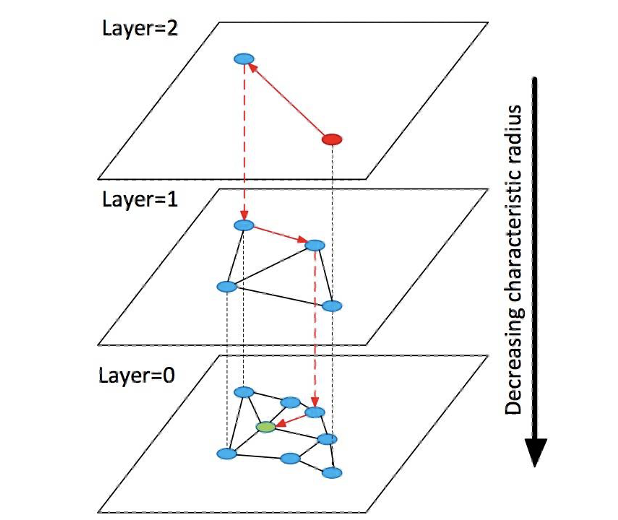 HNSW层次化图检索结构
HNSW层次化图检索结构