基于Lattice LSTM的命名实体识别



前 言
命名实体识别(Named Entity Recognition)作为自然语言处理中一项重要的基础任务,一直吸引着学术界的关注。命名实体识别一般认为是一个序列标注的问题,传统的方法有CRF(Conditional Random Field)。近年来随着深度学习的兴起,包括命名实体识别在内的序列标注模型从CRF迁移到了BILSTM-CRF等深度模型。当前在英文命名实体识别上,最好的模型是加上Character Embedding和ELMo (Embeddings from Language Models)2或者最近google新提出的BERT (Bidirectional Encoder Representations from Transformers)3 的BILSTM-CRF。
跟英文的命名实体识别不同的是,中文的命名实体识别跟分词息息相关,命名实体的边界也是分词的边界。一般来说,有两种方法,一种是word-based(基于词)的命名实体识别,另一种是character-based(基于字)的命名实体识别。word-based表示,首先对中文进行分词,然后对词(word token)进行序列标注。这种方法的缺点是:1. 分词容易造成错误传播,一旦分词分错了,实体就会被识别错;2. OOV(Out of Vocabulary)识别准确率低。character-based的方法是直接对字(character token)进行序列标注,这种方法的缺点是1. 相比较词(word token),丢失了词的信息;2. character embedding所含信息比较少;总体上两种方法各有优缺点。
我们为大家介绍一篇来自ACL 2018的文章,Chinese NER Using Lattice LSTM1。该文章提出了基于Lattice LSTM的命名实体识别模型,其模型是character-based的,但能够考虑通过词典匹配得到的词信息。一方面因为character-based的,所以不会因为分词造成错误传播,另一方面lattice LSTM模型能够考虑词的信息。实验结果显示,在多个数据集上,基于latticeLSTM的模型都取得了最好的效果。
首先,我们先回顾下基于序列标注的命名实体识别的几种主要方法。
Character-Based Model
1.>>>> Char
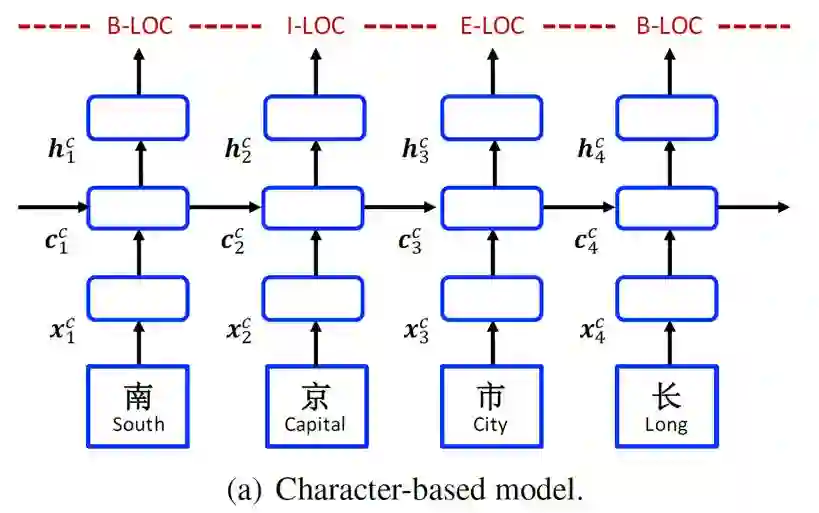
character-based模型网络结构如上图所示,input layer是单个字(character token)。
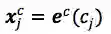
其中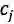
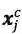
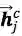
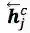
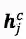
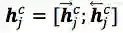
然后再接上CRF层进行序列标注。
2.>>>> Char + bichar
在encoding层,将character bi-gram embedding和character embedding 拼接起来。
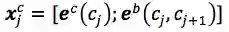
3.>>>> Char + softword
把分词的标记(BMES)作为特征,将segmentation label embedding和character embedding拼接起来。
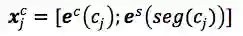
Word-Based Model
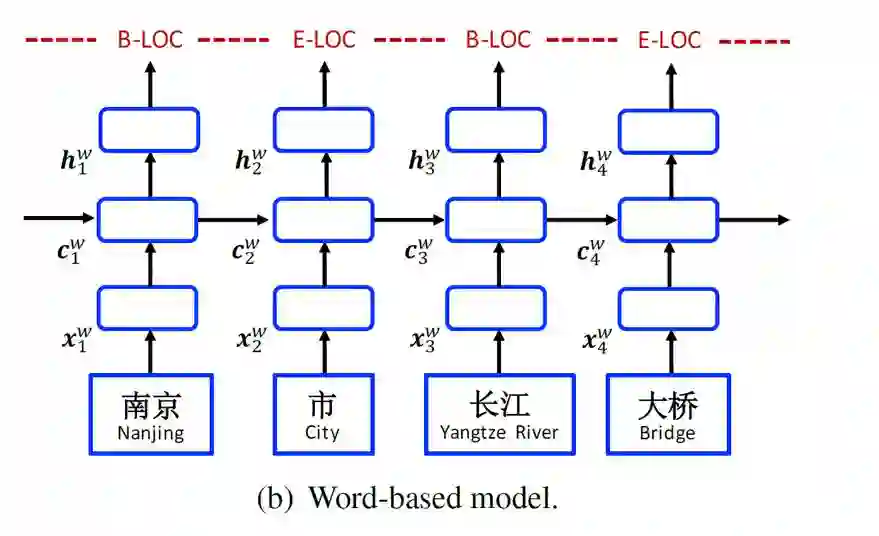
1.>>>>Word
word-based模型的网络结构跟character-based基本上一样,唯一不同的是在input layer,输入的是分好的词(word token)。
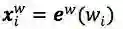
其中,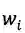
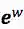
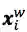
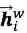
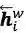
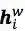
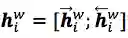
然后再接上CRF层进行序列标注。
前面提到,word-based方法对OOV效果不好,因为词(word token)相对于字(character token)更容易是OOV,在训练/预测的时候OOV的token都会映射到<unk>。当前主流的word-based方法都会加入character embedding来提高OOV的准确率
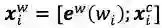
其中,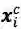
2.>>>>Word + char LSTM
将第i个词中的每个字首先经过embedding层,然后通过双向LSTM encode分别得到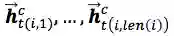
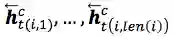
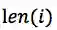
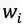
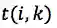
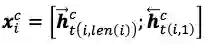
3.>>>>Word + char CNN
将第i个词中的每个字首先经过embedding层,然后通过CNN + max pooling得到对应的character embedding表示
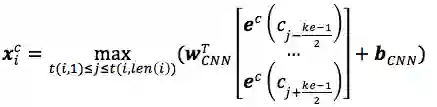
其中,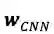
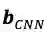
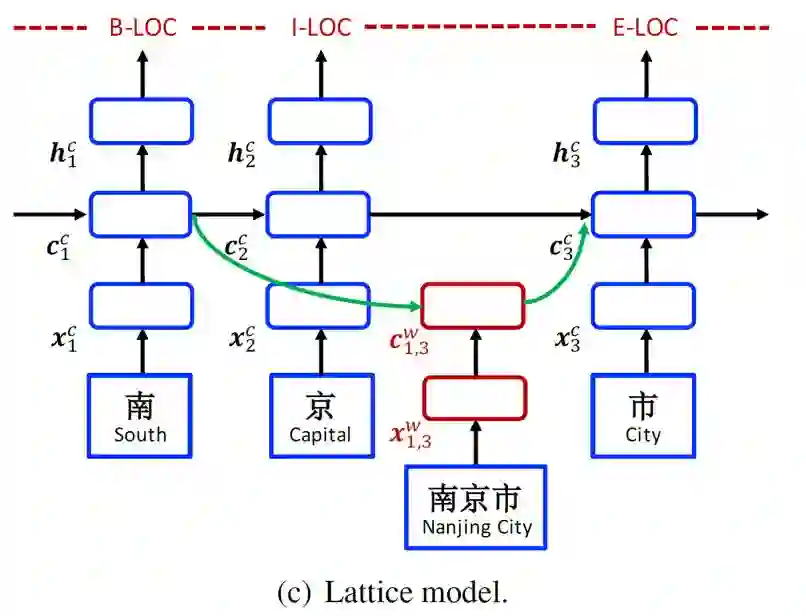
Lattice Model
接下来我们介绍本篇文章的主要方法Lattice Model。整个网络结构如下图所示,其结构可以看成是在character-based模型基础上加上了word-based cell和额外的gates来控制信息流。
在input层,是character序列
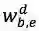
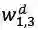
首先,我们回顾下基本的LSTM模型。
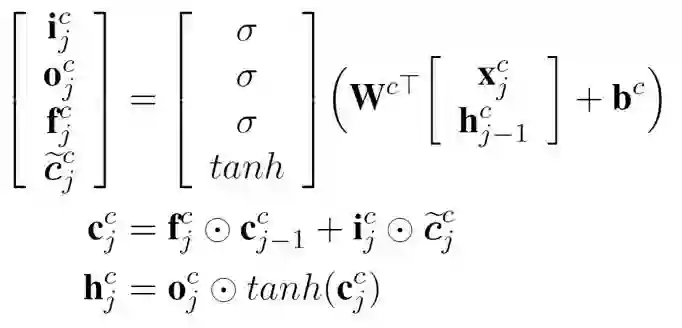
其中,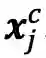
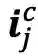
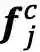
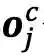
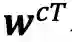
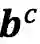
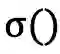
最核心的内容来了,上面提到会通过词典匹配得到词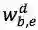
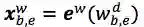
对于每个匹配到的词,计算其word cell 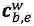
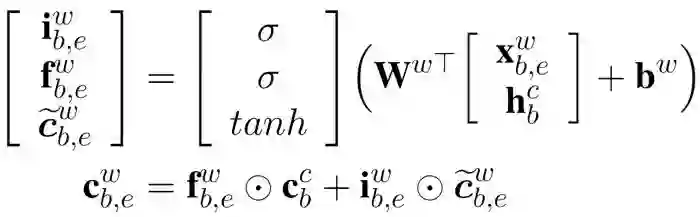
其中,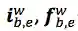
对于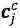
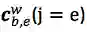
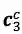
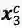
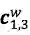
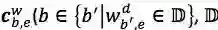
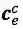
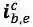
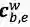
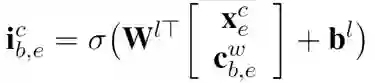
加上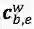
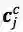
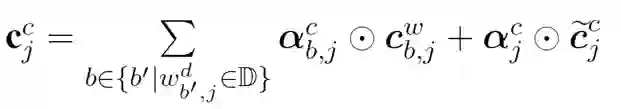
其中,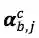
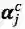
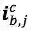
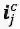
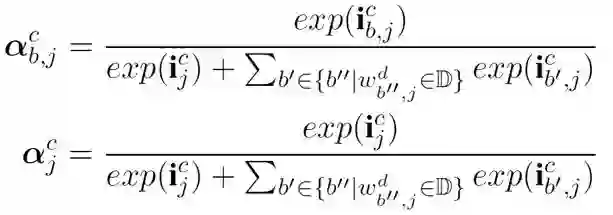
预 测 和 训 练
预测层跟大多数方法一样,是CRF层,预测序列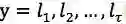
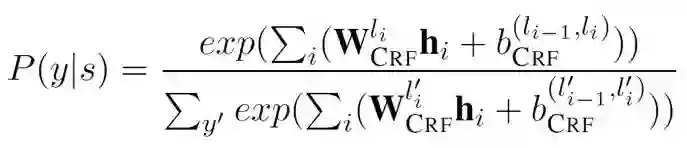
损失函数是对数似然
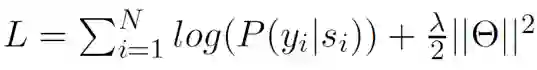
实 验
>>>> 数据
数据集 |
Train集标准分词 |
Dev集标准分词 |
Test集标准分词 |
OntoNotes |
有 |
有 |
有 |
MSRA |
有 |
无 |
无 |
Weibo NER |
无 |
无 |
无 |
Resume |
无 |
无 |
无 |
>>>> Dev 集实验结果
首先在OntoNotes的dev集上比较不同设置的结果,用来选取最好的设置。其中auto seg表示用training集训练一个分词工具,来对dev集进行分词。
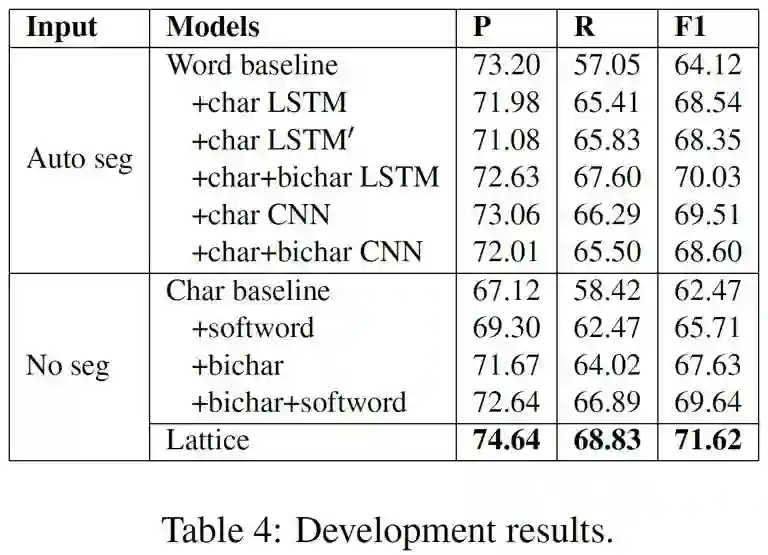
从上表结果显示:
1. 对于word-based模型,加入character embedding效果提升明显,其中word baseline + char + bichar LSTM效果最好;
2. 对于character-based模型,加入softword和bichar都有提升,其中char baseline + bichar + softword效果最好;
3. 本文提出的Lattice模型效果最好,F1值比最好的word-based和character-based模型分别提高1.59和1.98个百分点;
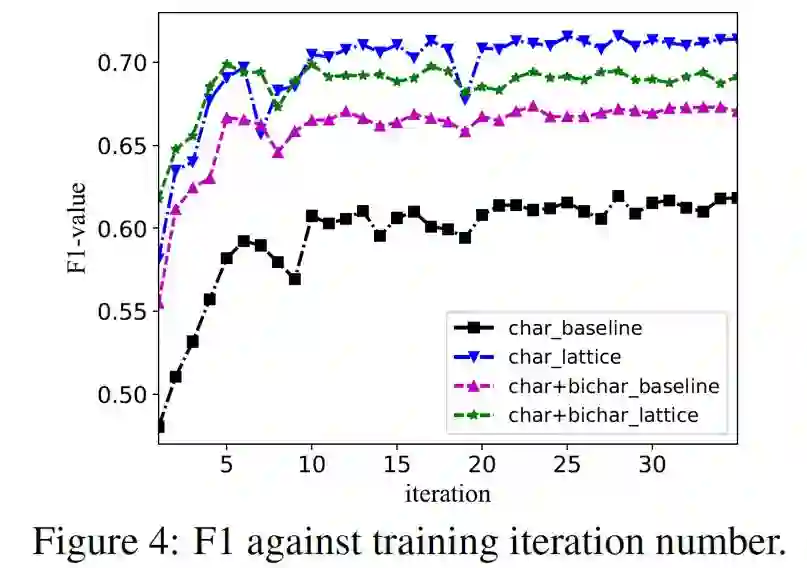
上图表示不同的模型随着迭代数增大F1值变化的情况,注意到char_lattice比char+bichar_lattice更好,一个可能的原因是lattice模型本身已经考虑到了词的信息,加入bichar,反而会增加noise。
>>>> Test 集实验结果
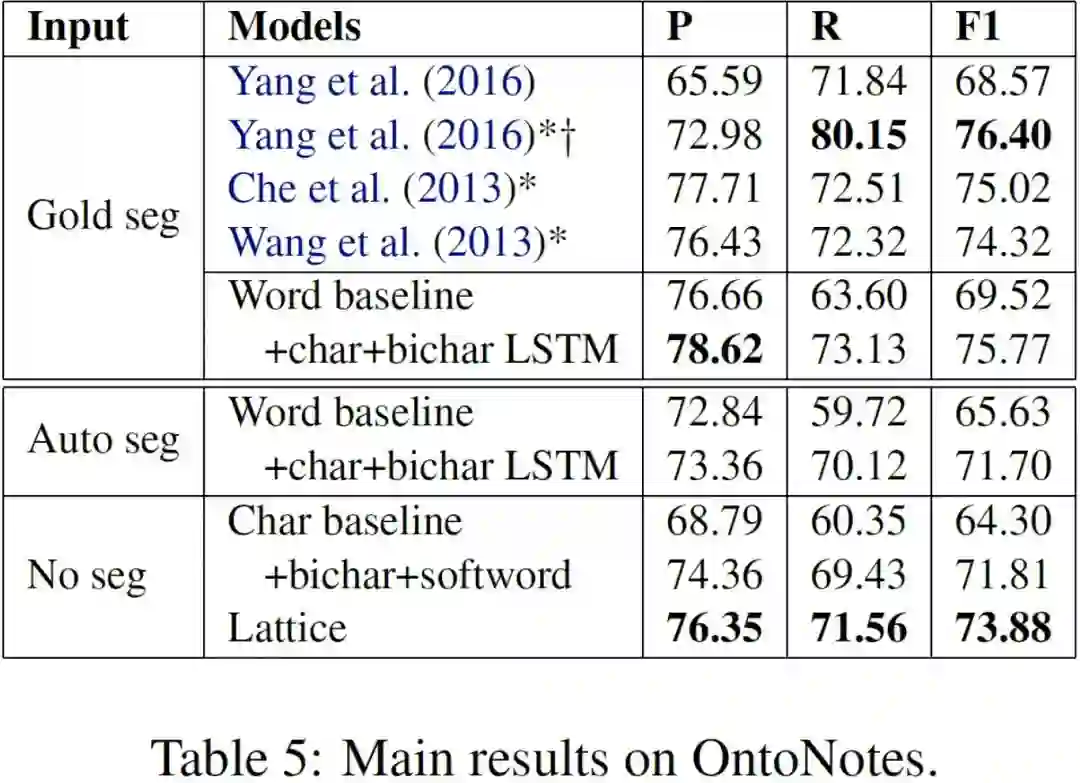
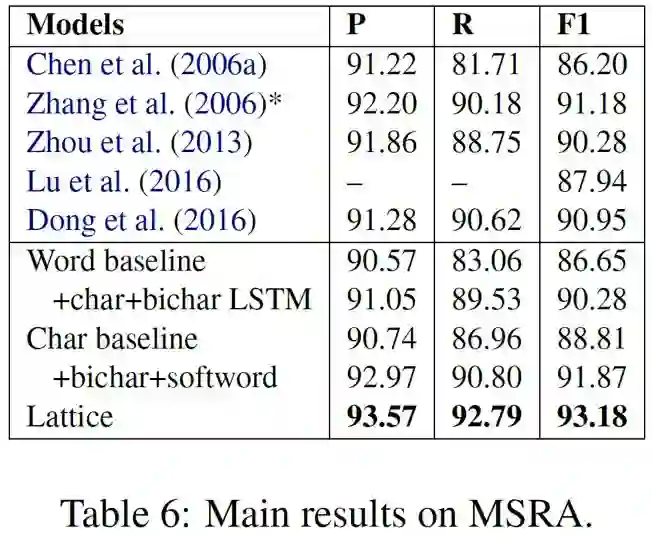
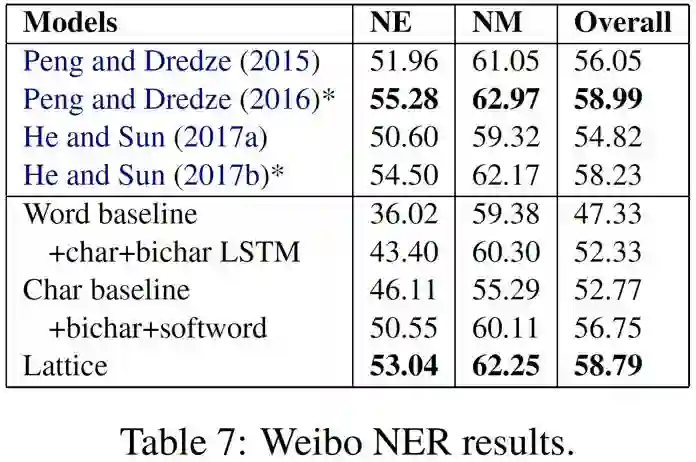
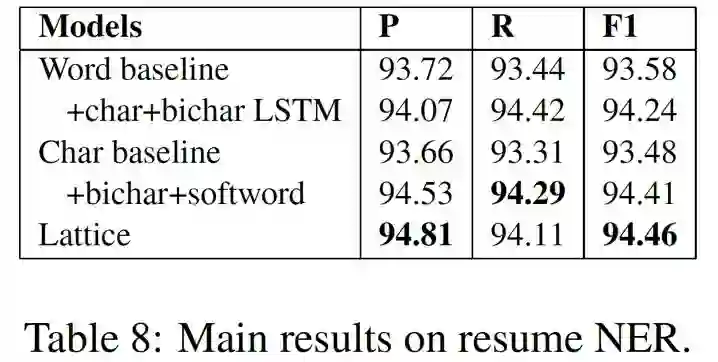
上面四个图分别表示在四个测试集上的最终实验结果,我们可以看出:
1. 在没有标准分词的情况下,Lattice取得了最好的结果;
2. 在有标准分词的情况下(OntoNotes),word-based的方法效果最好;
>>>> 实验分析
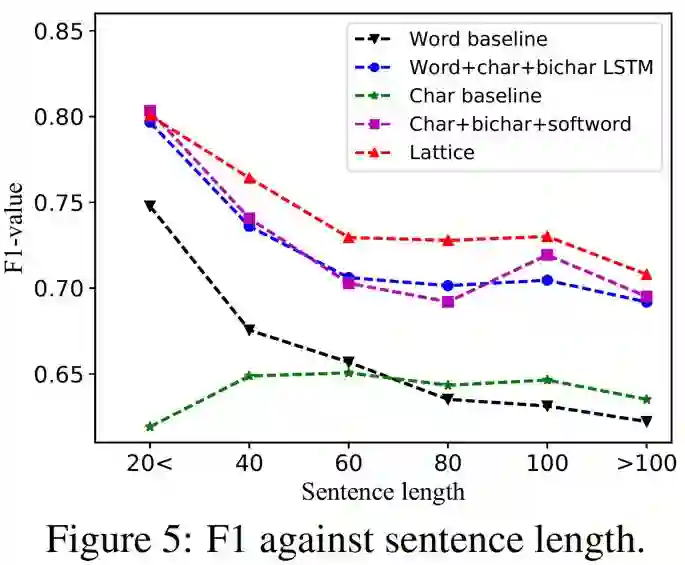
上图表示不同的模型在不同长度sentence上的F1值,可以看出:
1. Char baseline在不同长度的sentence上比较稳定,但F1值都比较低;
2. 其他几个模型都会随着sentence长度的增加,F1值会下降,但相比较而言,Lattice会稍微稳定一点;

上图是一个例子,首先对于”word + char + bichar LSTM”,分词分错了,所以实体也会识别错。对于”char + bichar + softword”,虽然单看“东莞台协会”没有问题,但“长职务后”显然不符合正确句式。而”Lattice”在这个例子中,由于”东莞”,”台协”,“会长”在词典中,所以最终能够预测正确。
总 结
这篇文章提出的Lattice LSTM还是比较新颖的,可以借助外部词典的信息,在中文命名实体识别的任务上取得了很好的实验结果。
Lattice LSTM由于是character-based(基于字)的,所以不会因为分词错误造成错误传播,另外能够考虑所有通过词典匹配到词的信息。该方法可以尝试用在其他序列标注任务中,作者也开源了相关的代码4,大家可以多尝试。最近ELMO和google刚提出的BERT很火,在英文的命名实体识别上提升效果很多,大家也可以在中文上尝试。
参考文献
1. Chinese NER Using Lattice LSTM, https://arxiv.org/pdf/1805.02023.pdf
2. Deep contextualized word representations, https://arxiv.org/pdf/1802.05365.pdf
3. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, https://arxiv.org/pdf/1810.04805.pdf
4. https://github.com/jiesutd/LatticeLSTM





