小模型实现大一统!Meta RL华人一作FBNetV5一举包揽CV任务3个SOTA
新智元报道
新智元报道
编辑:小咸鱼
【新智元导读】Meta现实实验室(Meta Reality Lab)华人一作提出FBNetV5,这是一种在一次运行中同时为多个任务搜索架构的神经架构搜索(NAS)算法。针对三个基本的视觉任务:图像分类、物体检测和语义分割,FBNetV5搜索到的模型在所有三个任务中都超过了目前的SoTA水平。
神经网络模型经常被研究人员戏称为「堆积木」,通过将各个基础模型堆成更大的模型,更多的数据来取得更好的效果。

为了减轻人工构建模型的工作量,用AI技术来搜索最优「堆积木」方法就很有必要了。
神经架构搜索 (NAS) 就是这样一种技术,随着研究的发展,神经结构搜索(NAS)已被广泛用于设计准确高效的图像分类模型。
然而,将神经架构搜索 (NAS)应用于新的计算机视觉任务仍然需要大量的努力。
这是因为之前的NAS研究,都是优先考虑图像分类任务,而在很大程度上忽略了其他任务;优化好的架构也无法顺利迁移到其他任务的特定任务组件;以及现有的NAS方法通常被设计为「无代理」,所以需要付出巨大的努力才能与每个新任务的训练管道集成。
为了应对这些挑战,Meta Reality Lab提出了FBNet系列最新版——FBNetV5,这是一个NAS框架,可以搜索满足各种视觉任务的神经网络架构,大大降低计算成本。

https://arxiv.org/pdf/2111.10007v1.pdf
通过对三个基本视觉任务(图像分类、目标检测和语义分割)的评估,FBNetV5在单次搜索中搜索的模型在所有三个任务中都优于以前的最先进水平:图像分类(与FBNetV3相比,在相同的FLOPs下,ImageNet top-1的准确率为1.3%),语义分割(ADE20K val mIoU比SegFormer高出1.8%的同时,减少3.6倍的FLOPs)和目标检测(与YOLOX相比,COCO val. mAP提升1.1%,减少1.2倍FLOPs)。
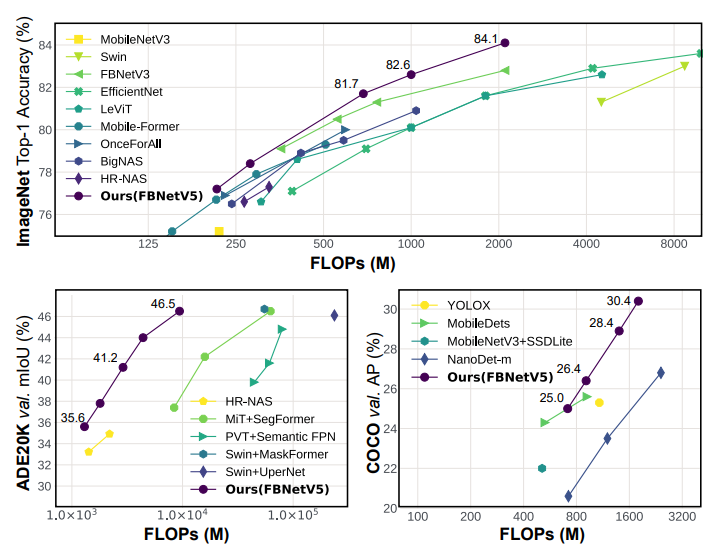
在FBNetV5的单次搜索中搜索的架构在三个任务上优于SoTA性能:ImageNet图像分类、ADE20K语义分割和COCO目标检测。
FBNetV5框架
FBNetV5框架
FBNetV5本质是一个全新的NAS框架,它可以在一次搜索中同时搜索多个任务的主干拓扑。该工作面向三个基本的计算机视觉任务:图像分类、目标检测和语义分割。
FBNetV5是从Meta AI自家最先进的图像分类模型,即FBNetV3开始,构建一个由多个分辨率的平行路径组成的超网(supernet),类似于HRNet。
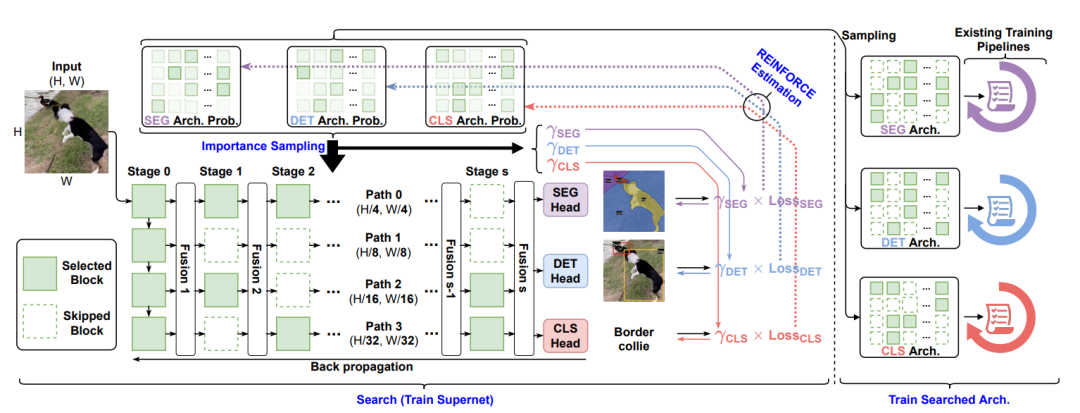
FBNetV5概述。通过在多任务数据集上训练超网来搜索多个任务的主干拓扑。每个任务都有自己的体系结构分布,从中抽取特定于任务的体系结构,并使用目标任务的现有训练管道对它们进行训练。
基于超网,FBNetV5通过将一组二进制掩码参数化,来搜索每个目标任务的最佳拓扑,该掩码的指示代表是否保留超网中的某个构建块。
为了将搜索过程从目标任务的训练流水线中分离出来,他们通过在具有分类、目标检测和语义分割标签的多任务数据集上训练超网来进行搜索。
为了使计算成本和超参数调整工作与任务数量无关,研究人员提出了一种超网训练算法,该算法在一次运行中同时搜索任务体系结构。

超网训练伪代码
在超网训练之后,再单独训练已经搜索到的针对于特定任务的网络结构,以测试它们的性能。
大量实验表明FBNetV5产生的紧凑模型可以在所有三个目标任务上实现SoTA性能。值得注意的是,所有性能良好的架构都是在一次运行中同时搜索的,然而它们却击败了为每项任务精心搜索或设计的SoTA神经架构。
实验结果
实验结果
Meta Reality Lab在基于Pytorch和Detectron2的D2Go中实现了搜索过程和目标任务的训练管道。
对于搜索(训练超网)过程,研究人员构建了一个从FBNetV3-A模型扩展而来的超网,在16个V100 GPU上训练,大概需要10个小时完成。
针对ImageNet分类、ADE20K语义分割和COCO目标检测,FBNetV5搜索的体系结构会与现有的NAS搜索和手动设计的紧凑模型进行比较。
通过训练一次supernet,为每个任务采样一个拓扑来搜索所有任务的拓扑,并将搜索到的拓扑转移到不同大小的不同版本FBNetV5模型中。
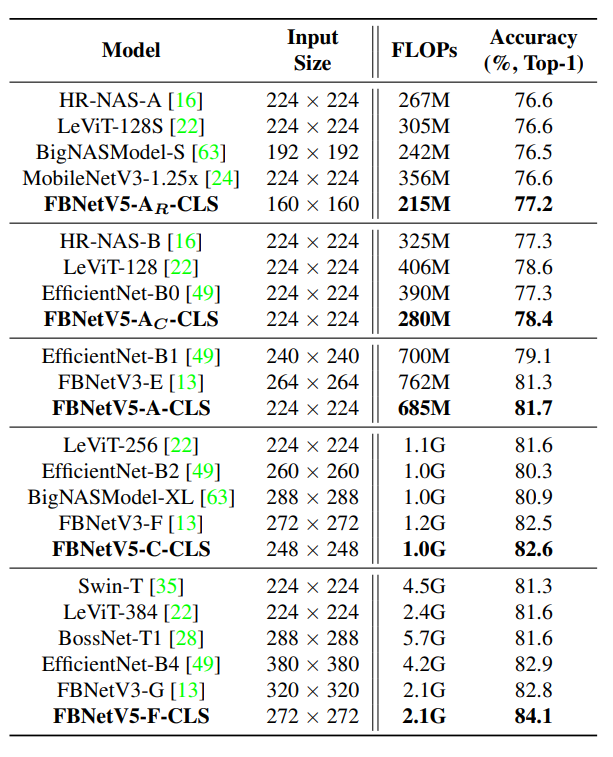
在ImageNet图像分类任务上与SoTA模型的比较。
FBNetV5使用FBNetV5-{A,C,F}的不同版本命名,并通过从FBNetV5-A分别收缩分辨率和通道大小来构建两个更小的模型FBNetV5-AR和FBNetV5-AC,并最终使用FBNetV5-{version}-{task}的格式来命名模型。
与所有现有的紧凑模型(包括自动搜索和手动设计的模型)相比,FBNetV5在ImageNet 分类中提供了具有更好精度与FLOPs平衡的架构。与FBNetV3-G相比,在相同FLOPs下,top-1精度提高了1.3%。
在ADE20K语义分割任务中,FBNetV5与以MiT-B1为主干的SegFormer相比,mIoU提高了1.8%,FLOPs减少了3.6倍。
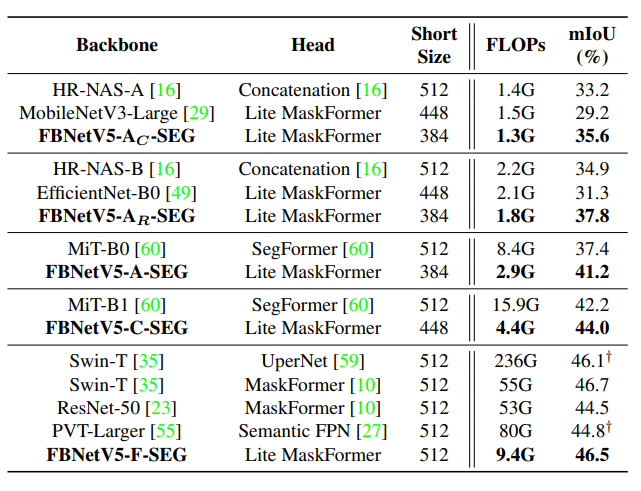
在ADE20K语义分割任务上与SoTA模型的比较。
在COCO目标检测任务中,FBNetV5与YOLOX-Nano相比,获得了1.1%的mAP增益,但是FLOPs减少了1.2倍。
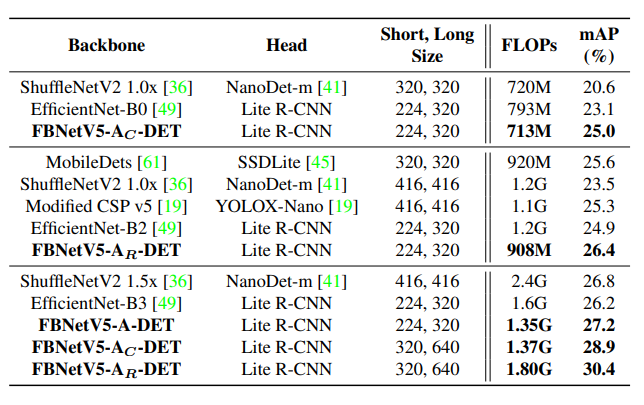
在COCO目标检测任务上与SoTA模型的比较。
为了验证FBNetV5搜索算法的有效性,研究人员将提出的多任务搜索与单任务搜索和随机搜索进行了比较。
与随机搜索相比,使用相同的FLOPs,来自多任务搜索的模型明显优于随机采样模型,在图像分类上实现了0.3%的性能增益,在语义分割上实现了1.6%的性能增益,在目标检测上实现了0.4%的性能增益。
与单任务搜索相比,通过多任务搜索搜索到的模型提供了非常相似的性能(例如,在ADE20K 上相同mIoU下,2.8 GFLOPs对2.7 GFLOPs),同时将每个任务的搜索成本降低了T倍。T代表任务的数量。
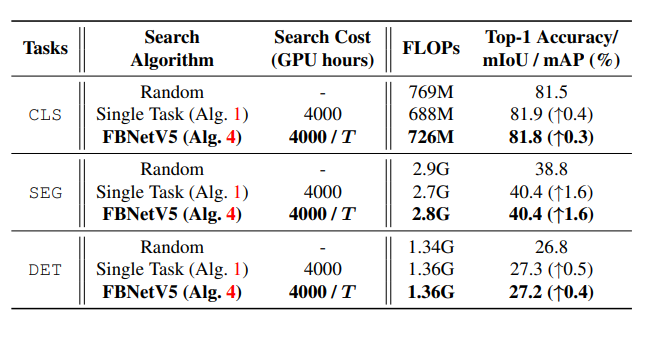
当在ImageNet图像分类(CLS)、ADE20K语义分割(SEG)和COCO目标检测(DET)中进行基准测试时,FBNetV5搜索算法的有效性。T代表任务数。
最终搜索到的结构如下:
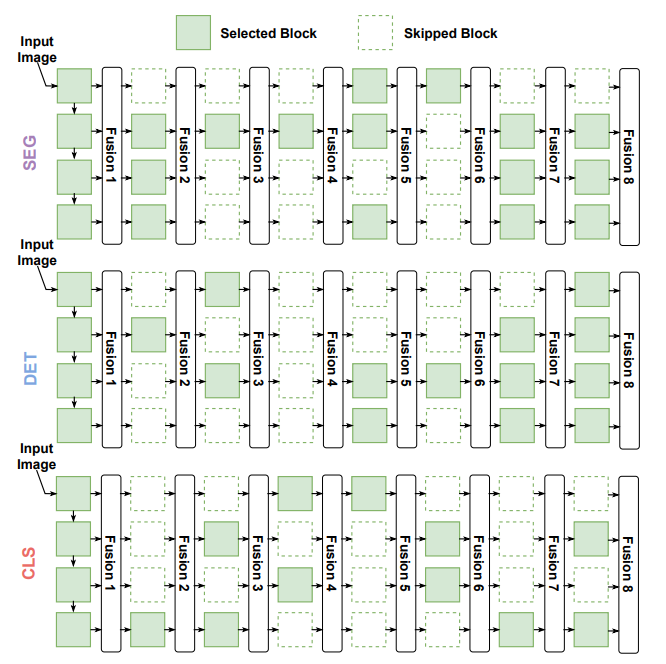
语义分割(SEG)、目标检测(DET)和图像分类(CLS)任务的搜索架构的可视化。
未来,研究人员在FBNetV5的基础上,还会探索更细粒度的搜索空间,例如,搜索分块的信道大小,这可以进一步提高搜索模型的性能。
参考资料:
https://arxiv.org/pdf/2111.10007v1.pdf



