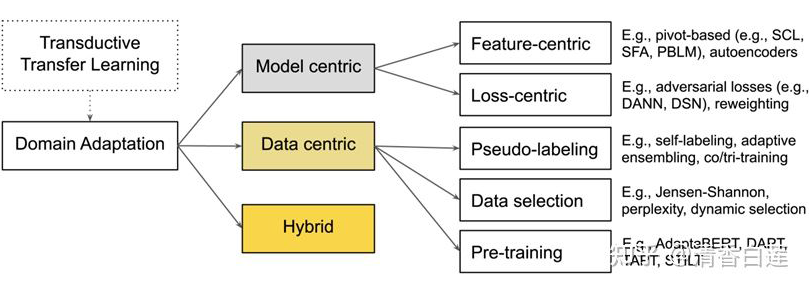
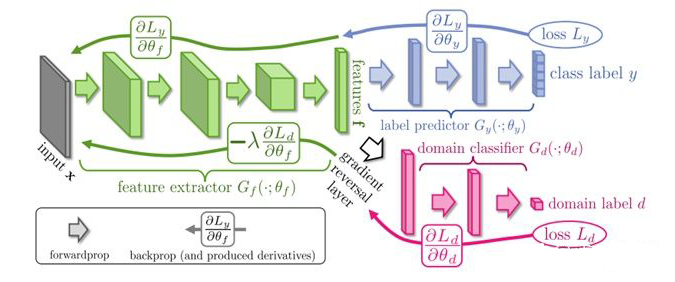
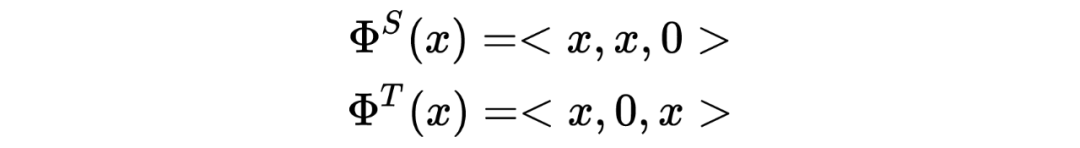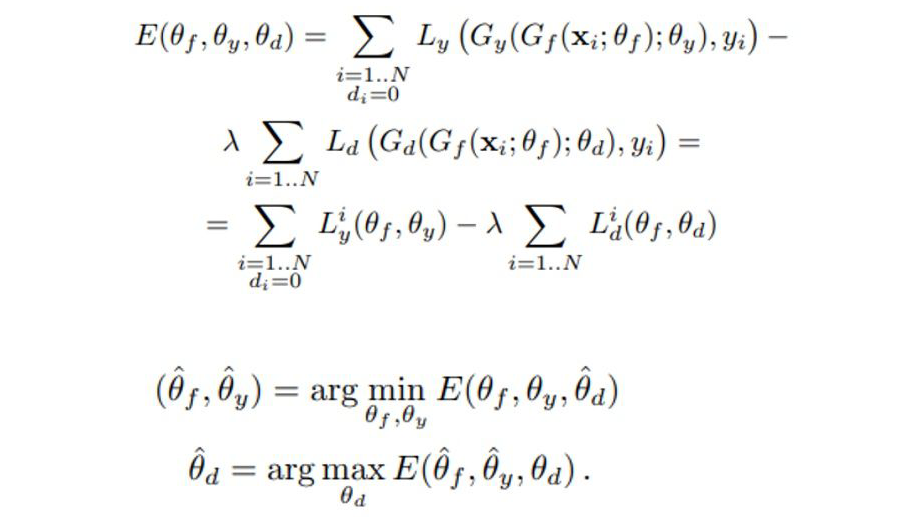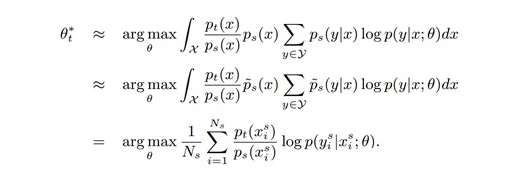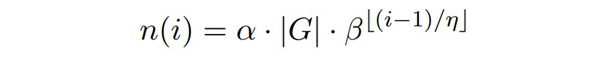沿着这两个方向,Feature-centric 方法包含两类子方法:Pivots-based DA 与 Autoencoder-based DA 。 Pivots-based DA 旨在通过使用源领域与目标领域的无标签数据去寻找两个领域通用的特征。最简单的便是 Frustratingly Easy Domain Adaptation (FEDA),假设 x
是原始特征特征,那么源领域与目标领域在增强后的特征空间可表示为
其中第一组特征表示通用共享特征,其他为各个领域特有的特征。如果有 K 个领域,那么增强后的特征空间的维度将是原始特征空间的 K+1 倍,实际每个实例在增强后的特种空间内是一个稀疏向量,优化后并不会增加太多内存开销。这个方法虽然很简单,但却取得了很好的效果,已成为一个很强的 baseline。
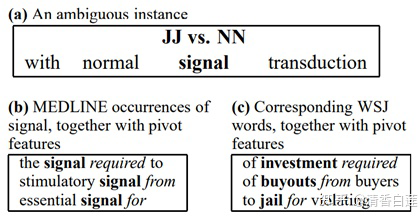
Structural Correspondence Learning(SCL)是比较 General 的方法,它可以应用在目标领域没有带标签数据的场景。这种方法比较 tricky,需要手动的构建 Pivot Feature。所谓 Pivot Feature 就是频繁地在多个跨领域出现并且行为表现也相似的特征。以下面这句摘自 MEDLINE 语料中的句子为例 The oncogenic mutated forms of the ras proteins are constitutively active and interfere with normal signal transduction. 这句话里面的 “signal” 在此处是名词,但如果词性标注模型是用 WSJ 语料训练的,会将其错误的识别为形容词。对比 MEDLINE 语料中 signal 这个词的上下文与 WSJ 语料中名词的上下文,可以发现一些共同的 Pattern,比如都出现在 required、from 与 for 这些词前面,因此可以用这些共同的 Pattern 作为 Feature,训练的模型就可以获得很好的跨领域泛化能力。这些 Pattern 就是 Pivot Feature。
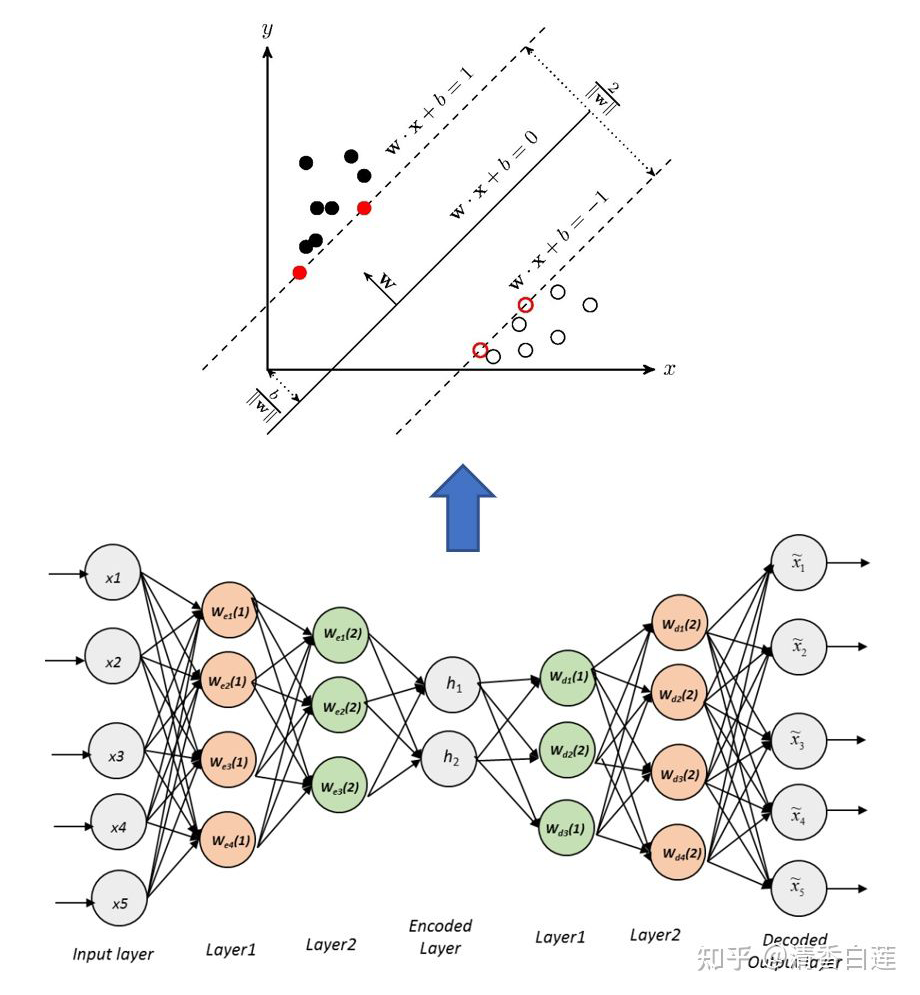
Autoencoder-based DA:众所周知,深度学习可以捕捉到输入数据中潜在的生成因子,这些因子可以解释数据的多样性。Denoising Autoencoder(DAE)就是一种通过无监督地学习输入数据的潜在表征,从而捕捉这些潜在因子的模型。Autoencoder-based DA 假定这种表征具有跨领域的泛化能力,其具体步骤分为两步:
[1] Alan Ramponi, Barbara Plank. Neural Unsupervised Domain Adaptation in NLP—A Survey.
[2] Hal Daume´ III. Frustratingly Easy Domain Adaptation.
[3] John Blitzer, Ryan McDonald, and Fernando Pereira. 2006. Domain adaptation with structural correspondence learning.
[4] Xavier Glorot, Antoine Bordes, and Yoshua Bengio. 2011. Domain adaptation for large-scale sentiment classification: A deep learning approach.
[5] Jing Jiang and ChengXiang Zhai. 2007. Instance weighting for domain adaptation in nlp.
[6] Sebastian Ruder and Barbara Plank. 2018. Strong baselines for neural semi-supervised learning under domain Shift.
[7] Suchin Gururangan, Ana Marasovi´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks.