NLP类别不均衡问题之loss大集合

©作者 | 眼睛里进砖头了
单位 | 东华大学
研究方向 | 自然语言处理
NLP 任务中,数据类别不均衡问题应该是一个极常见又头疼的的问题了。最近在工作中也是碰到这个问题,花了些时间梳理并实践了下类别不均衡问题的解决方式,主要实践了下“魔改”loss(focal loss, GHM loss, dice loss 等),整理了下。所有的 Loss 实践代码在这里:
数据不均衡问题也可以说是一个长尾问题,但长尾那部分数据往往是重要且不能被忽略的,它不仅仅是分类标签下样本数量的不平衡,实质上也是难易样本的不平衡。
解决不均衡问题一般从两方面入手:
1. 数据层面:重采样,使得参与迭代计算的数据是均衡的;
2. 模型层面:重加权,修改模型的 loss,在 loss 计算上,加大对少样本的 loss 奖励。

数据层面的重采样

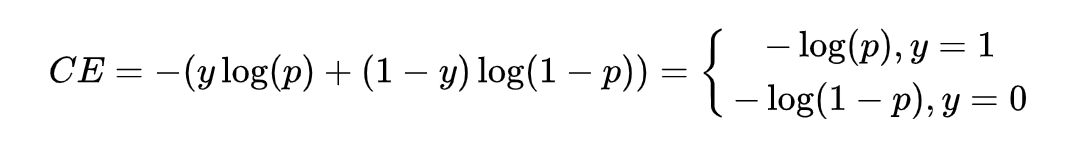
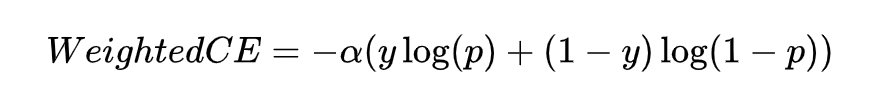
接下来,看下 Focal Loss 是怎么做到集中关注预测不准的样本?
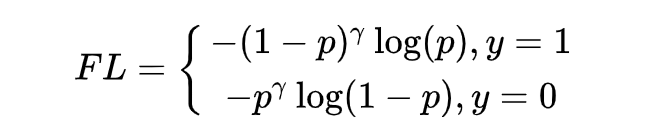
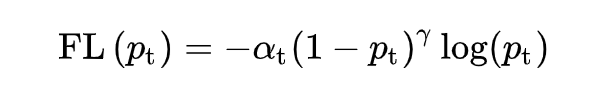
代码的实现也是比较简洁的。
def __init__(self, num_class, alpha=None, gamma=2, reduction='mean'):
super(MultiFocalLoss, self).__init__()
self.gamma = gamma
......
def forward(self, logit, target):
alpha = self.alpha.to(logit.device)
prob = F.softmax(logit, dim=1)
ori_shp = target.shape
target = target.view(-1, 1)
prob = prob.gather(1, target).view(-1) + self.smooth # avoid nan
logpt = torch.log(prob)
alpha_weight = alpha[target.squeeze().long()]
loss = -alpha_weight * torch.pow(torch.sub(1.0, prob), self.gamma) * logpt
if self.reduction == 'mean':
loss = loss.mean()
return loss2.2 GHM Loss
上面的 Focal Loss 注重了对 hard example 的学习,但不是所有的 hard example 都值得关注,有一些 hard example 很可能是离群点,这种离群点当然是不应该让模型关注的。
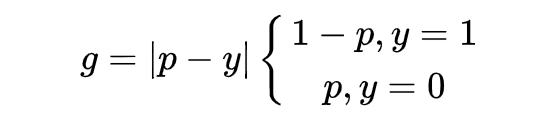
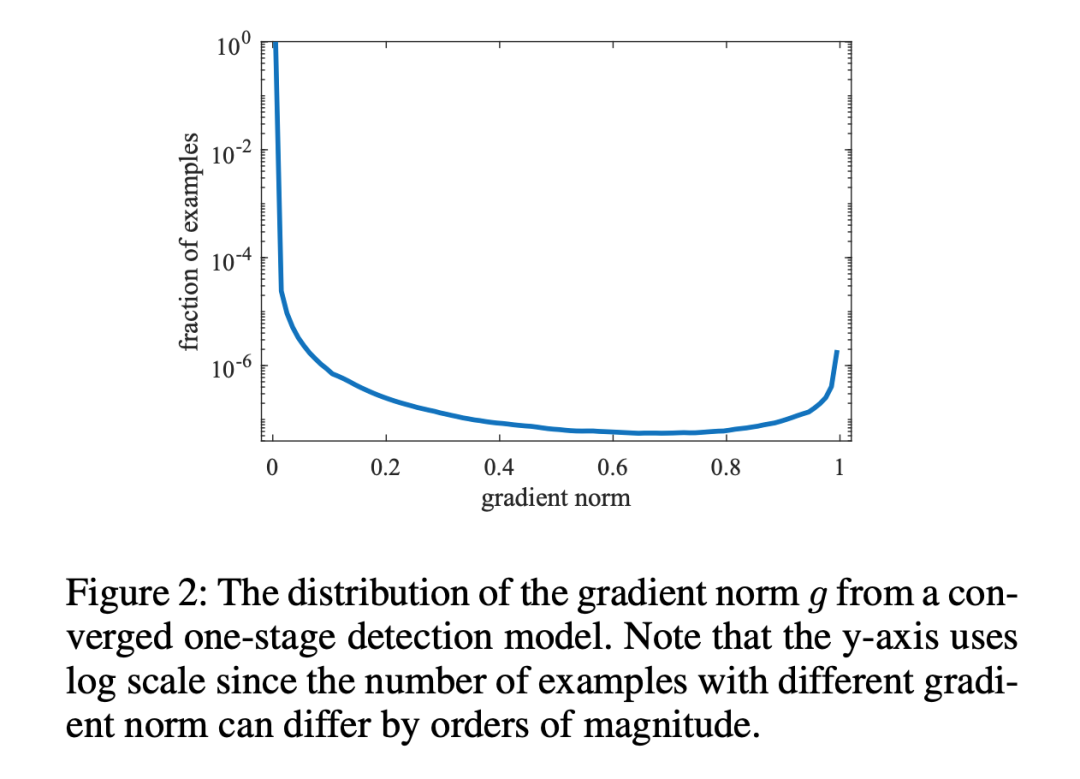
此时,对于每个样本,把交叉熵 CE×该样本梯度密度的倒数,就得到 GHM Loss。
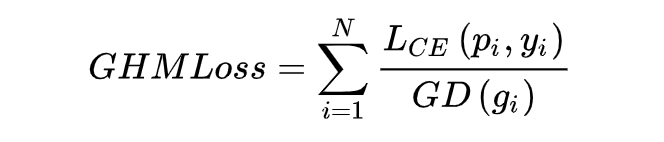
这里附上逻辑的代码,完整的可以上文章首尾仓库查看。
class GHM_Loss(nn.Module):
def __init__(self, bins, alpha):
super(GHM_Loss, self).__init__()
self._bins = bins
self._alpha = alpha
self._last_bin_count = None
def _g2bin(self, g):
# split to n bins
return torch.floor(g * (self._bins - 0.0001)).long()
def forward(self, x, target):
# compute value g
g = torch.abs(self._custom_loss_grad(x, target)).detach()
bin_idx = self._g2bin(g)
bin_count = torch.zeros((self._bins))
for i in range(self._bins):
# 计算落入bins的梯度模长数量
bin_count[i] = (bin_idx == i).sum().item()
N = (x.size(0) * x.size(1))
if self._last_bin_count is None:
self._last_bin_count = bin_count
else:
bin_count = self._alpha * self._last_bin_count + (1 - self._alpha) * bin_count
self._last_bin_count = bin_count
nonempty_bins = (bin_count > 0).sum().item()
gd = bin_count * nonempty_bins
gd = torch.clamp(gd, min=0.0001)
beta = N / gd # 计算好样本的gd值
# 借由binary_cross_entropy_with_logits,gd值当作参数传入
return F.binary_cross_entropy_with_logits(x, target, weight=beta[bin_idx])
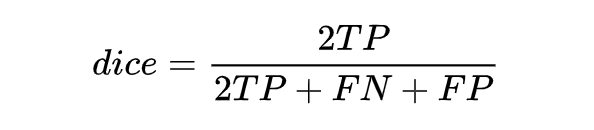
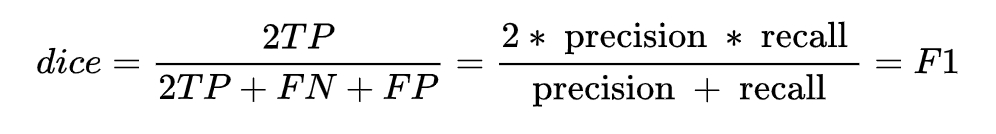
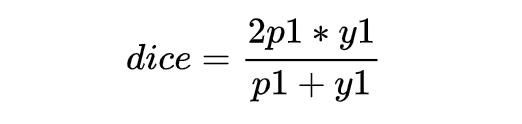
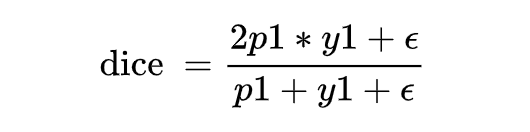
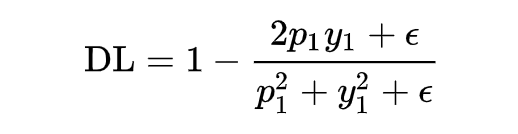
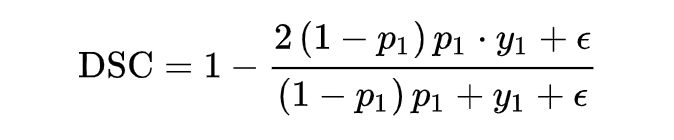
class DSCLoss(torch.nn.Module):
def __init__(self, alpha: float = 1.0, smooth: float = 1.0, reduction: str = "mean"):
super().__init__()
self.alpha = alpha
self.smooth = smooth
self.reduction = reduction
def forward(self, logits, targets):
probs = torch.softmax(logits, dim=1)
probs = torch.gather(probs, dim=1, index=targets.unsqueeze(1))
probs_with_factor = ((1 - probs) ** self.alpha) * probs
loss = 1 - (2 * probs_with_factor + self.smooth) / (probs_with_factor + 1 + self.smooth)
if self.reduction == "mean":
return loss.mean()

https://github.com/shuxinyin/NLP-Loss-Pytorch
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


