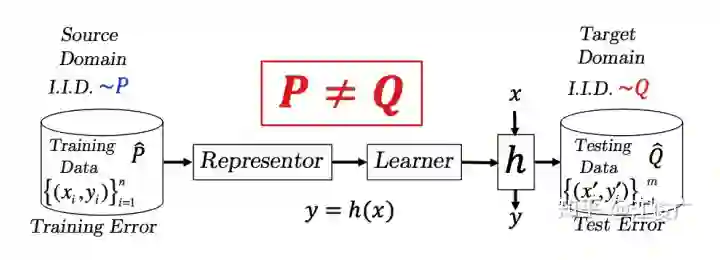
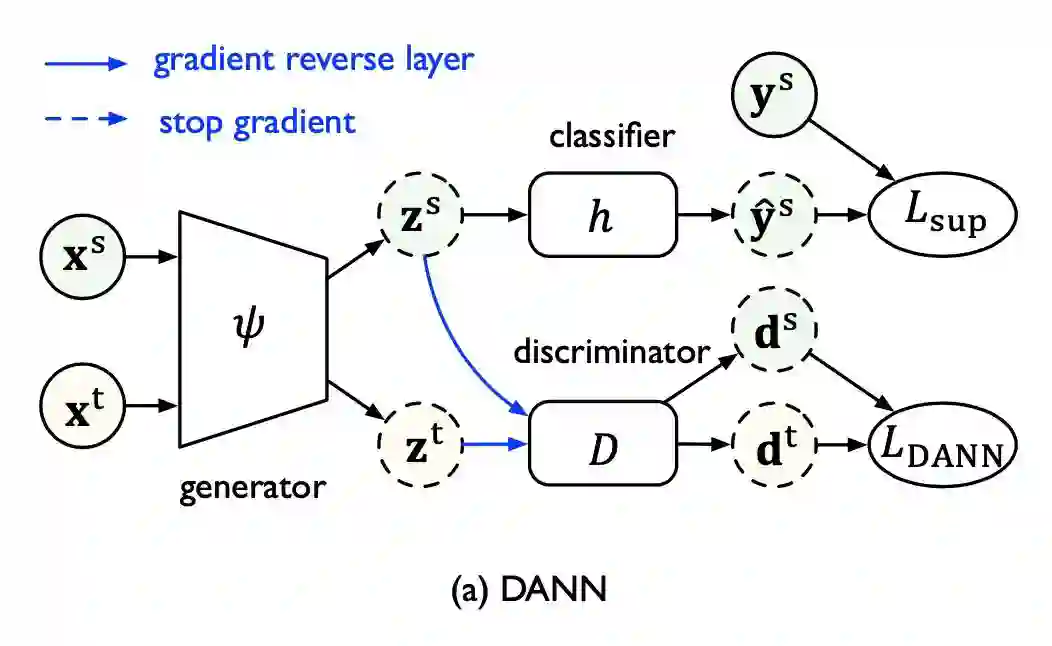
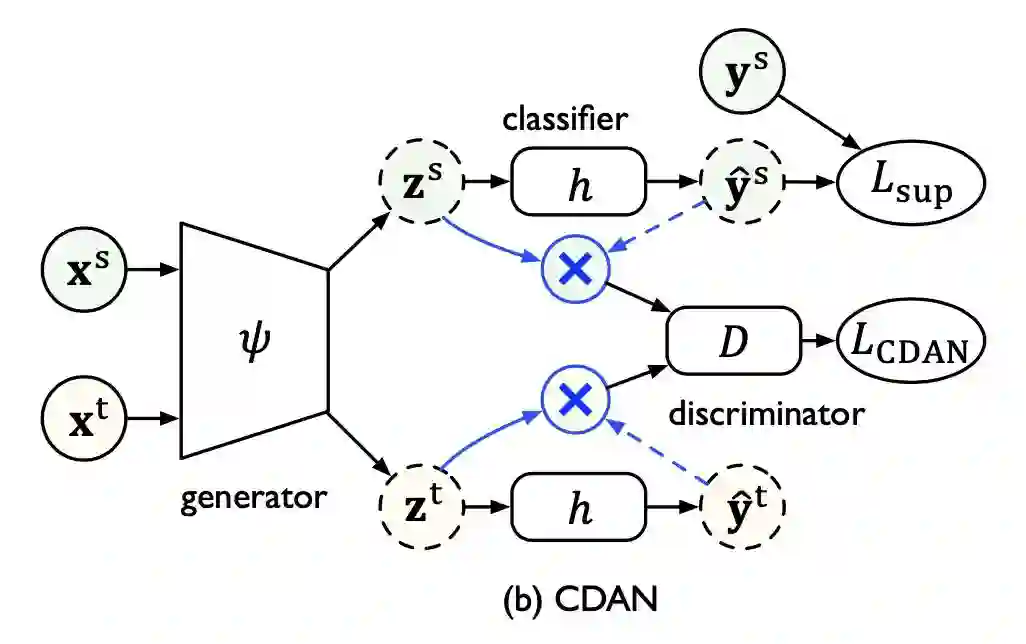
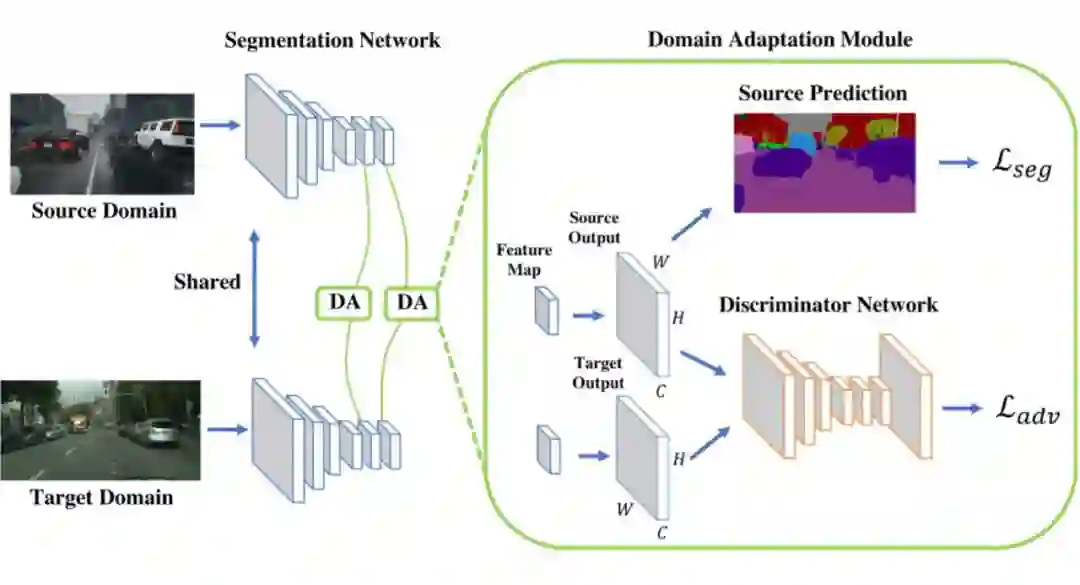
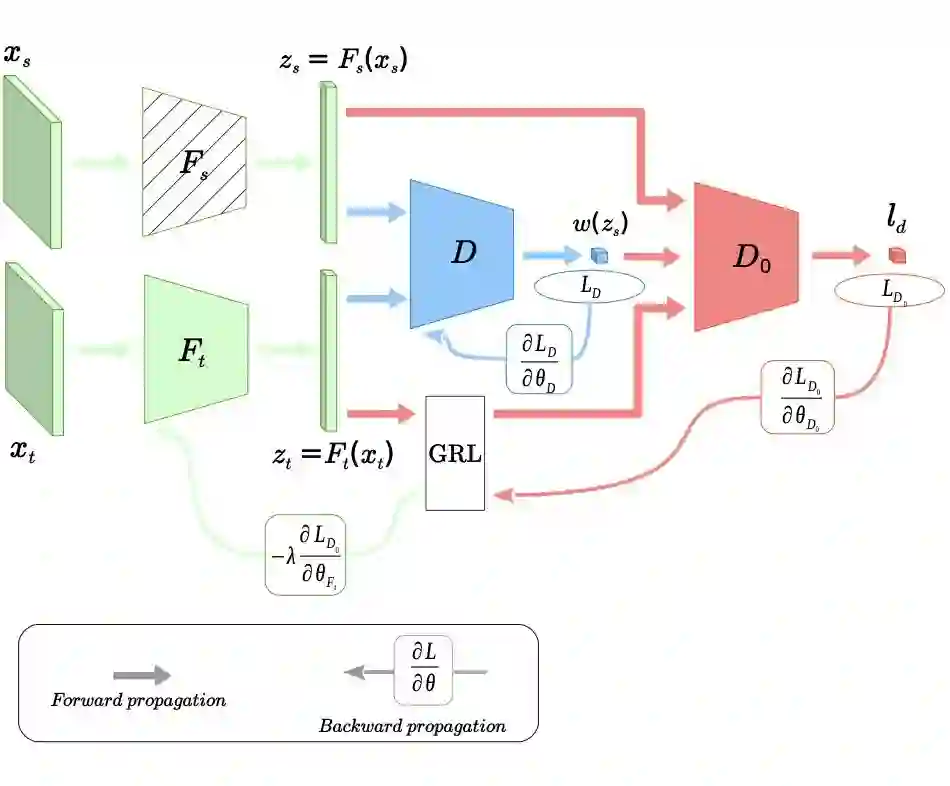
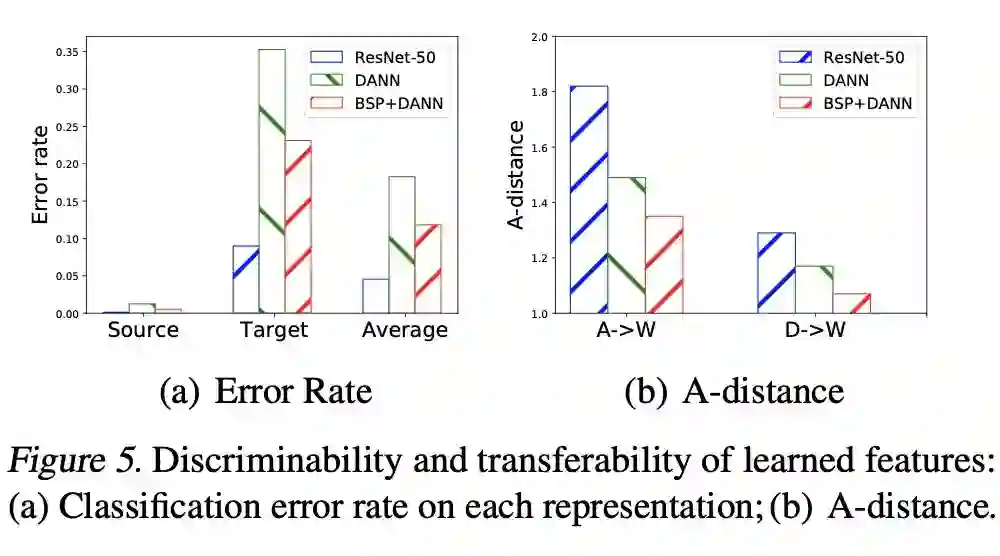
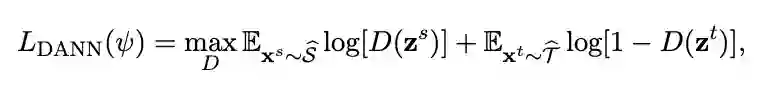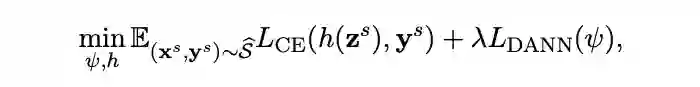这些在迁移学习文献综述 Transferability in Deep Learning: A Survey 中进行了详细介绍,后续也会为这些方法推出相关的介绍文章。 对抗域自适算法的理论基础可以参考姐妹篇文章迁移学习:域自适应理论简介 Domain Adaptation Theory。 本文力求用通俗的语言介绍对抗域自适应方法最重要的几个算法的设计以及它们的改进。因此,不了解域自适应理论不影响阅读本文。
相比于统计距离(比如 DAN [7],JAN 等),基于域判别器学习得到的距离需要更多的数据(不论是源域还是目标域)。因此在数据量相对较少的场景下,反而是基于统计距离的域自适应方法效果更好。强调相对的原因是,数据量相对的多少不仅取决于总的数据量,还取决于类别数,比如 DomainNet 数据量虽然大,但是类别数也多,导致在 DomainNet 上反而是 DAN 比 DANN 效果更好。
[1] abSagawa, S., Koh, P. W., Lee, T., Gao, I., Xie, S. M., Shen, K., Kumar, A., Hu, W., Yasunaga, M., Marklund, H., Beery, S., David, E., Stavness, I., Guo, W., Leskovec, J., Saenko, K., Hashimoto, T., Levine, S., Finn, C., and Liang, P. Ex- tending the wilds benchmark for unsupervised adaptation. In NeurIPS Workshop on Distribution Shifts, 2021. [2] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropaga- tion. In ICML, 2015.[3] Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. In NeurIPS, 2014.[4] Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I. Jordan. Conditional adver- sarial domain adaptation. In NeurIPS, 2018.[5] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic seg- mentation. In CVPR, 2018.[6] Zhang, J., Ding, Z., Li, W., and Ogunbona, P. Importance weighted adversarial nets for partial domain adaptation. In CVPR, 2018.[7] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael I. Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015.[8] Junguang Jiang, Yifei Ji, Ximei Wang, Yufeng Liu, Jianmin Wang, and Mingsheng Long. Regressive domain adaptation for unsupervised keypoint detection. In CVPR, 2021[9] Xinyang Chen, Sinan Wang, Mingsheng Long, and Jianmin Wang. Transferability vs. discriminability: Batch spectral penalization for adversarial domain adaptation. In ICML, 2019c.[10] Junguang Jiang, Baixu Chen, Jianmin Wang, and Mingsheng Long. Decoupled adaptation for cross-domain object detection. In ICLR, 2022.[11] Junguang Jiang, Yang Shu, Jianmin Wang, Mingsheng Long, Transferability in Deep Learning: A Survey https://arxiv.org/abs/2201.05867