深度 | L2正则化和对抗鲁棒性的关系
选自thomas-tanay
作者:THOMAS TANAY、LEWIS D GRIFFIN
机器之心编译
虽然近年来对抗样本已经引起了广泛关注,并且它对机器学习的理论和实践来说都有很大意义,但迄今为止仍有很多不明之处。为此,来自伦敦大学学院(UCL)的医学与生命科学跨学科研究中心(CoMPLEX)的Thomas Tanay、Lewis D Griffin写下了本文,旨在提供一个关于对抗样本线性问题的清晰、直观概览。他们分析了 L2 正则化对对抗鲁棒性的影响,以及对抗鲁棒性和经验风险之间的权衡,并将结论扩展到神经网络,希望为后续工作打下坚实的基础。文中使用了简单而典型的例子,在原网页上包含大量交互可视化示例,对加强直观理解很有帮助。
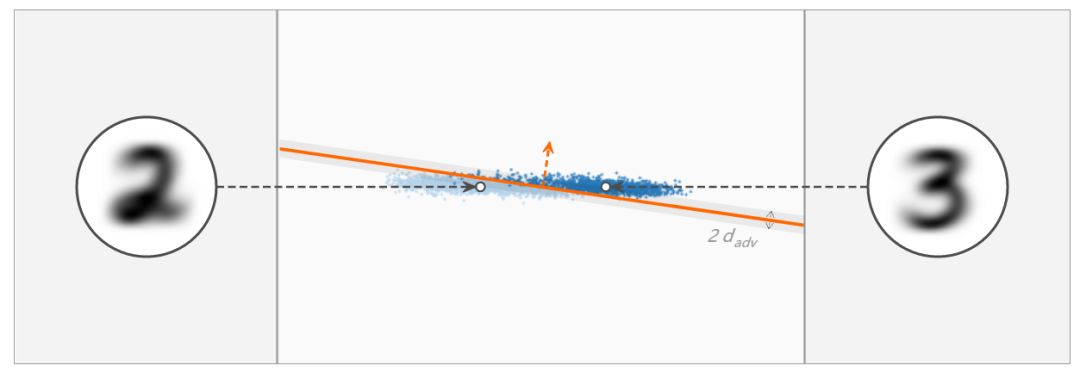
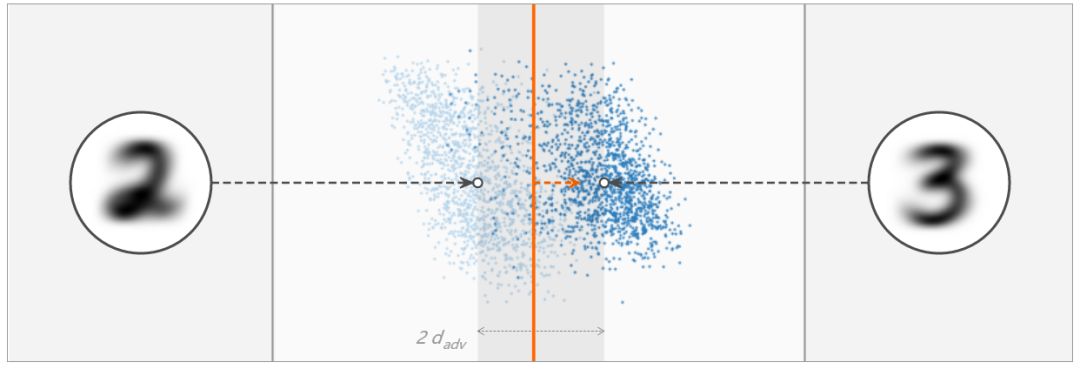
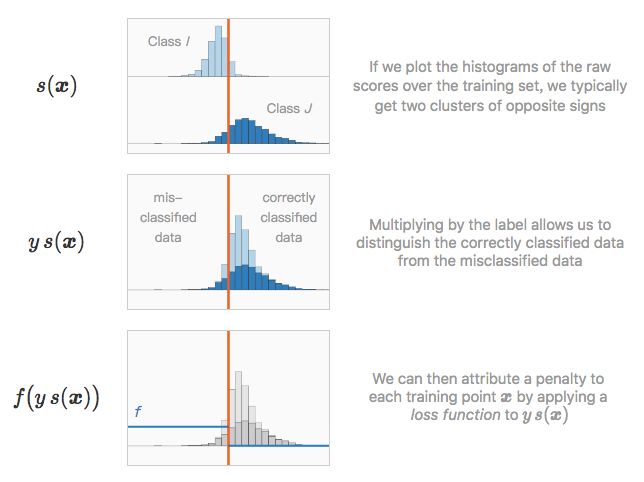
两个高维聚类由一个超平面分离,考虑超平面和图中水平线之间的夹角,在线性分类中,这个夹角取决于 L2 正则化的程度,你知道为什么吗?上图:L2 正则化程度较小;下图:L2 正则化程度较大。
深度学习网络已被证实容易受到对抗样本攻击:小的图像干扰能够大幅改变目前测试过的所有模型的分类 [1, 2]。例如,以下预测就是由为识别名人而训练的当前最佳网络做出的 [3]:
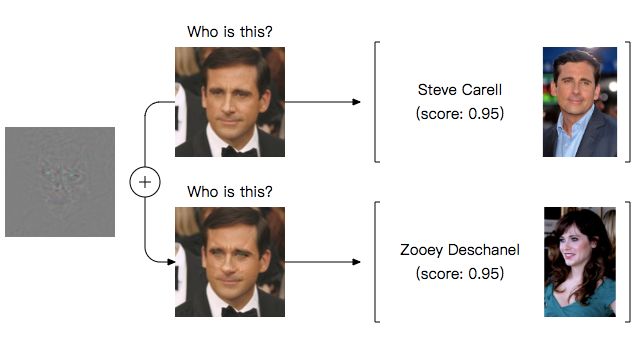
该结果令人困惑有两个原因。第一,它挑战了一个普遍的观点,即对新数据的良好泛化和对小干扰的鲁棒性是并行不悖的。第二,它对真实世界中的应用构成了潜在威胁 [4, 5, 6]。例如,MIT 的研究者们最近构建了在广泛的角度和视点分布下被错误分类的 3D 对象 [7]。理解这种现象并提高深度网络的鲁棒性由此成为一个重要的研究目标。
目前已有几种方法投入研究。相关论文提供了关于此现象的详细描述 [8, 9] 和理论分析 [10, 11, 12]。研究者已经尝试构建更加鲁棒的架构 [13, 14, 15, 16] 或在评估中检测对抗样本 [17, 18, 19, 20]。对抗训练已经作为一种惩罚对抗方向的正则化新技术被引入 [2, 5, 21, 22]。然而不幸的是,这一问题还远远没有解决 [23, 24]。面对这一难题,我们提出从最基本的问题入手:先克服线性分类困难,然后再逐步解决更复杂的问题。
玩具问题
在线性分类中,对抗干扰通常被理解为高维点积的一个属性。一个普遍的观点是:「对于高维问题,我们可以对输入进行很多无穷小的改变,这些改变加起来就是对输出的一个大改变。」[2] 我们对这种观点存疑,并认为当分类边界靠近数据流形,即独立于图像空间维度时,存在对抗样本。
设置
让我们从一个最简单的玩具问题开始:一个二维图像空间,其中每个图像是 a 和 b 的函数。
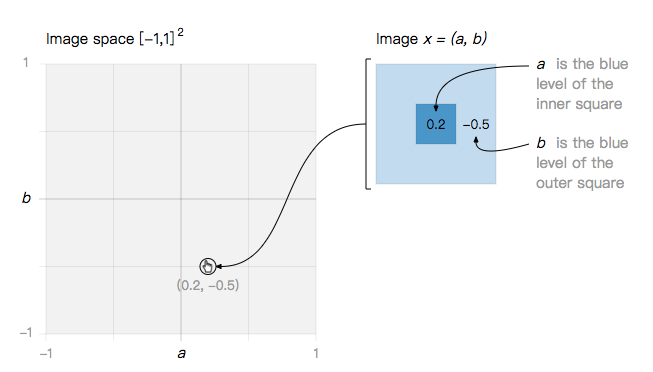
在这个简单的图像空间中,我们定义了两类图像……
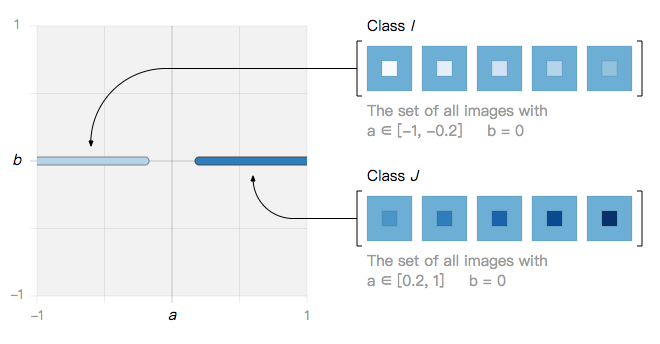
···它们可以被无限个线性分类器分开,例如分类器 L_θ。
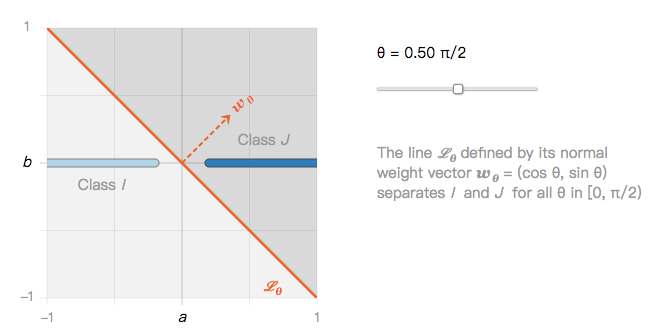
由此产生第一个问题:如果所有的线性分类器 L_θ 都能将 I 类和 J 类很好地分离,那它们对抗图像干扰的鲁棒性是否相同?
投影图像和镜像图像:
考虑 I 类中的图像 x。在相反类中与 x 最接近的图像是 x 在 L_θ 上的投影图像 x_p:
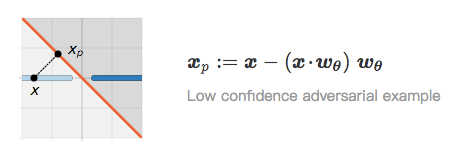
当 x 和 x_p 非常接近时,我们称 x_p 是 x 的对抗样本。尽管 x_p 被归为低置信度(它位于边界上),但高置信度对抗样本可能更引人关注 [24]。接下来,我们将通过 L_θ 重点介绍 x 的镜像图像 x_m:
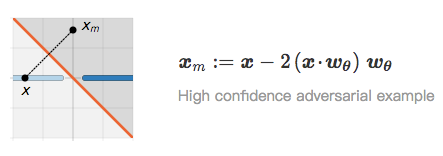
通过构造镜像图像,x 和 x_m 到边界的距离相同,并且被分为相同的置信度水平。
θ函数的镜像图像
回到玩具问题,现在我们可以绘制图像 x 及其镜像 x_m 作为 θ 的函数。
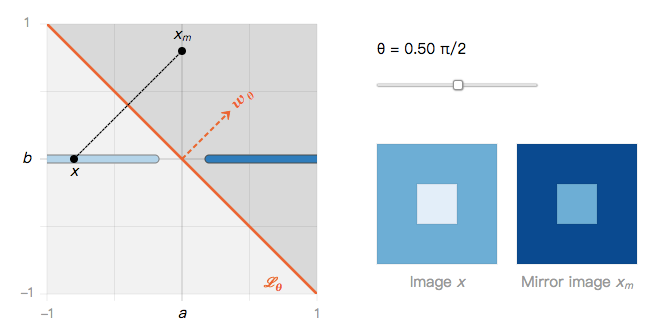
从图中可以发现,x 和 x_m 之间的距离取决于角度 θ。这两个边缘案例非常有趣。
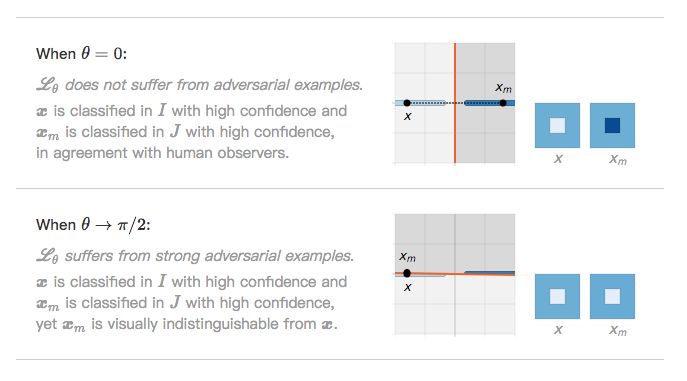
由此产生第二个问题:如果在 L_θ 严重倾斜时存在对抗样本,那么实际上是什么使 L_θ 倾斜?
过拟合与 L2 正则化
本文的假设是,由标准线性学习算法(如支持向量机(SVM)或 logistic 回归模型)定义的分类边界通过过拟合训练集中的噪声数据点而倾斜。该假设在 Xu 等人 [26] 撰写的论文中找到了理论依据,该文将支持向量机的鲁棒性与正则化联系起来。此外,还可以通过实验来检验该假设:旨在减少过拟合的技术,如 L2 正则化,有望减少对抗样本现象。
例如,考虑包含一个噪声数据点 P 的训练集。
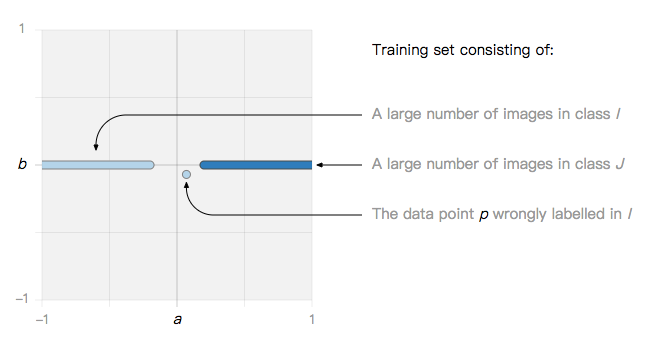
如果我们在这个训练集上训练 SVM 或 logistic 回归模型,我们观察到两种可能的现象。
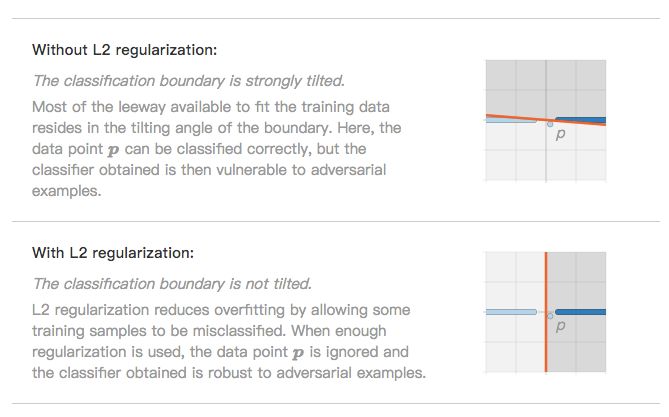
此时,人们可能会合理地怀疑:位于二维图像空间上的一维数据流形与高维自然图像有什么关系?
线性分类中的对抗样本
下面,我们将证明在前一个玩具问题中介绍的两个主要观点在一般情况下仍然有效:在分类边界与数据流形非常接近且 L2 正则化控制边界倾斜角度时会出现对抗样本。
缩放损失函数
让我们从一个简单的观察入手:在训练期间,权重向量的范数充当损失函数的缩放参数。
设置
若 I 和 J 是两类图像,C 是定义 Rd 中线性分类器的超平面边界。C 由正常权重向量 w 和偏置 b 指定。对于 Rd 中的图像 x,我们将 x 到 C 的原始分数称为值:
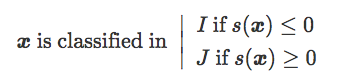
现在,考虑 n 对 (x,y) 组成的训练集 T,其中 x 是图像,并且 y={−1 if x∈I|1 if x∈J} 是其标签。我们对以下数量在 T 上的分布感兴趣:
由此为分类器 C 引出经验风险 R(w,b) 的概念,被定义为训练集 T 上的平均惩罚项:
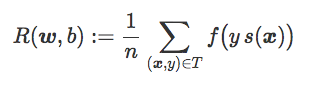
总的来说,学习一个线性分类器包括:为精心选择的损失函数 f 找到权重向量 w 和偏置 b 并最小化 R(w,b)。
在二分类中有以下三种值得注意的损失函数:

对于 0-1 指示函数,经验风险只是 T 上的错误率。在某种意义上,这是最佳损失函数,因为最小化错误率往往是实践中所渴求的目标。不幸的是,该函数不适合梯度下降(没有可以下降的梯度:每一处的导数都为 0)
通过将误分类数据上的单元惩罚替换为严格递减惩罚,hinge 损失函数(用于 SVM)和 softplus 损失函数(用于 logistic 回归)克服了这一局限性。注意:这两个损失函数也会惩罚一些边界附近正确分类的数据,有效地保证了安全边际。
缩放参数∥w∥
之前忽视了很重要的一点,即符号距离 s(x) 是通过权重向量的范数来缩放的。如果 d(x) 是 x 和 C 之间的实际符号欧氏距离,那么我们有:
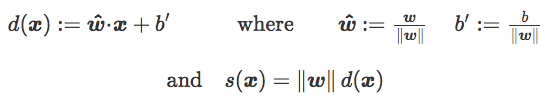
因此,范数‖w‖可以理解为损失函数在经验风险表达式中的缩放参数:

我们这样定义损失函数 f‖w‖:z→f(‖w‖×z)。
我们观察到,重新缩放后,0-1 指示函数不变,但 hinge 损失函数和 softplus 损失函数却受到了很大影响。
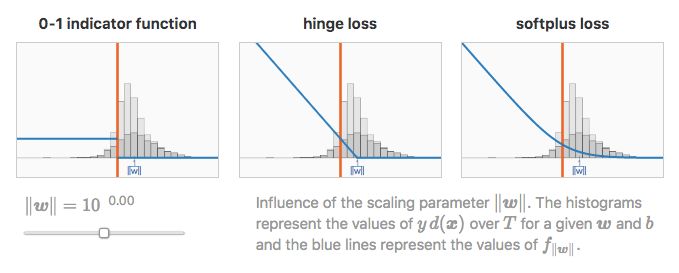
0-1 指示函数
值得注意的是,对于缩放参数的极值,hinge 损失和 softplus 损失函数表现一致。

更确切地说,两个损失函数都满足:
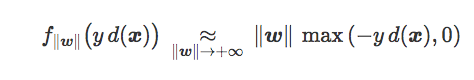
为方便表述,我们将误分类数据集表示为:
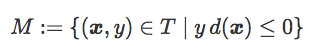
经验风险可以表示为:
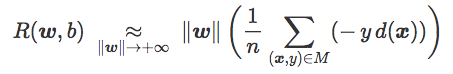
这一表达包含一个名为误差距离的项:
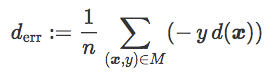
该项为正,可以理解为被 C 误分类的每个训练样本之间的平均距离(对正确分类数据没有贡献)。它与训练误差相关——尽管并不完全相等。
最后,我们得到:
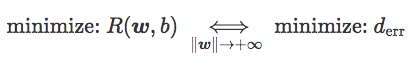
以上公式可以用语言表述为:当‖w‖很大时,将 hinge 损失和 softplus 损失最小化就等于将错误距离最小化,近似于将训练集上的错误率最小化。

更确切地说,对于一些正值α和β,两个损失函数都满足:
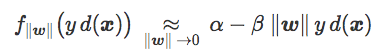
经验风险可以表示为:
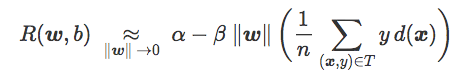
这一表述包含一个名为对抗距离的项:
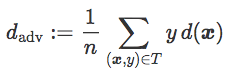
这是 T 中图像和分类边界 C 之间的平均距离(对于误分类图像的贡献为负)。可以将它看做针对对抗干扰的鲁棒性的度量:d_adv 比较高时,误分类图像的数量有限,正确分类的图像距离 C 非常远。
最后我们可以得到:
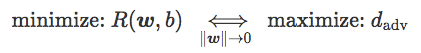
也就是说,当 ‖w‖很小时,将 hinge 损失和 softplus 损失最小化就等于将对抗距离最大化,这可以解释为将对抗样本最小化的现象。
结束语
实际上,可以通过在经验风险中添加正则项来控制 ‖w‖ 的值,从而产生正则损失:
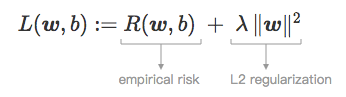
小的正则化参数 λ 可以让 ‖w‖ 无限制地增长,而较大的 λ 则导致 ‖w‖ 收缩。
总之,用于线性分类(SVM 和逻辑回归)的两个标准模型在两个目标之间平衡:
当正则化程度低时,它们最小化误差距离;
当正则化程度高时,它们最大化对抗距离。
对抗距离和倾斜角度
前一节中出现的对抗距离是对对抗干扰鲁棒性的度量。更方便的是,它可以表示为单个参数的函数:分类边界和最近质心分类器之间的角度。
如果 T_I 和 T_J 分别是 T 对 I 和 J 中元素的限制,我们可以写作:
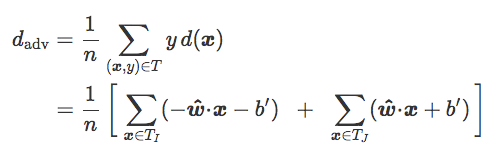
如果 T_I 和 T_J 平衡(n=2n_I=2n_J):
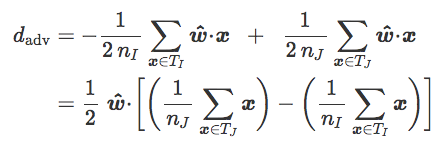
如果 i 和 j 分别为 T_I 和 T_J 的质心:
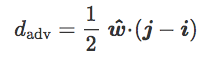
现在介绍最近质心分类器,它的单位法向量 z^=(j−i)/‖j−i‖:
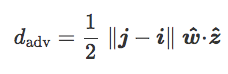
最后,我们称包含 w hat 和 z hat 的斜平面为 C,称在 w hat 和 z hat 内的角θ为倾斜角 C:
d_adv=12‖j−i‖cos(θ)
该方程在斜平面上的几何解释是:
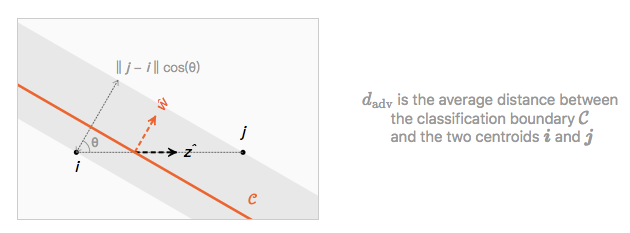
在一个给定的训练集 T 内,两个质心的距离 ‖j−i‖已经固定,d_adv 只取决于倾斜角θ。会出现以下两个现象:
通过最近质心分类器(θ=0)可以使对抗现象最小化
当θ→π/2 时,对抗样本可以任意增强(如在玩具问题部分的分类器 L_θ一样)
举例:SVM on MNIST
我们现在要说明先前关于 MNIST 数据的二进制分类的注意事项。对于每一种能够分类的数字,我们利用每类有 3000 张图片的数据集来训练多个 SVM 模型(w,b), 正则化参数λ∈[10^−1,10^7]。
我们首先绘制训练数据和边界之间的距离 y_d(x)的分布作为正则化参数λ(灰色直方图)的函数。在每个模型收敛(蓝线)后叠加损失函数 f‖w‖。
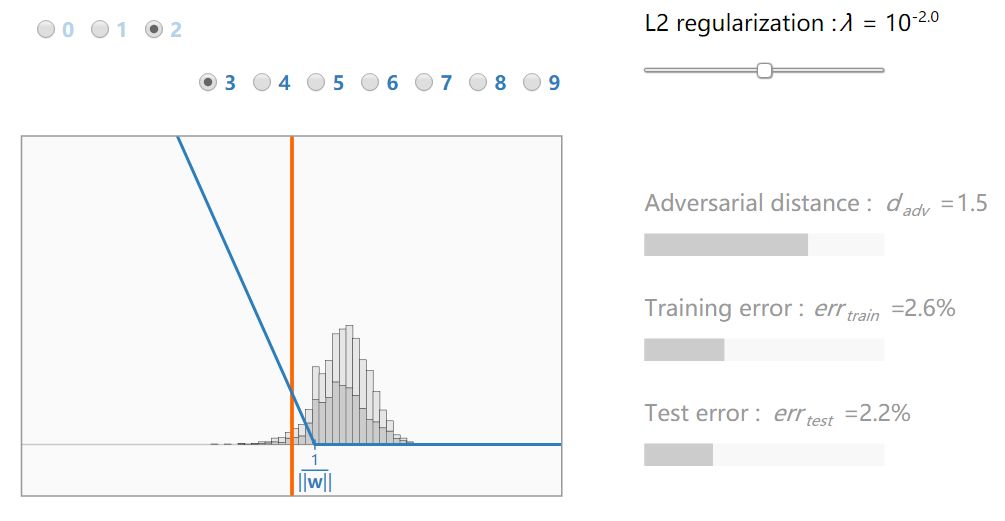
可以看到 hinge 损失的缩小对获得的模型有明显的影响。不幸的是,训练误差最小化和对抗距离最大化是相互矛盾的目标:当 λ很小,err_train 最小化;当λ很大,d_adv 最大化。注意,对于中级正规化λ_optimal,测试误差最小化。当λ<λ_optimal 时,分类器会过拟合;当λ>λ_optimal 时,分类器欠拟合。
为了更好地理解这两个目标是如何平衡的,我们可以从不同的角度来看训练数据。
首先计算最近质心分类器的单位权重向量 z hat,然后针对每个 SVM 模型 (w,b) 计算出单位向量 n hat,这样 (z hat,n hat) 就是斜平面 w 的一组标准正交基。最后,将训练数据映射到 (z hat,n hat):
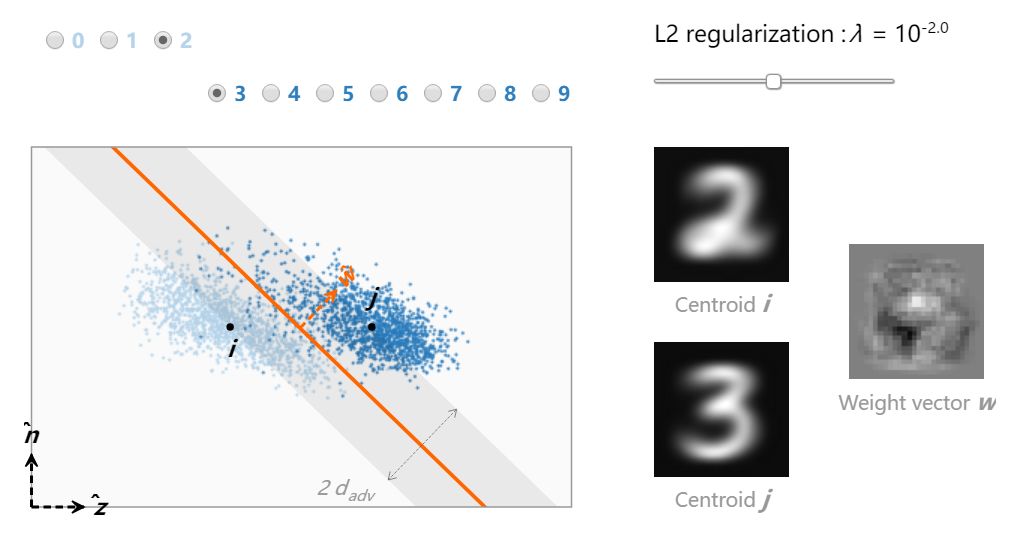
水平方向穿过两个质心,选定垂直方向,使 w 属于该平面(超平面边界则以直线形式出现)。由于 (z hat,n hat) 是一组标准正交基,所以这个平面的距离实际上是像素的距离。要理解为什么当λ变化时数据点移动,我们需要想象倾斜平面在 784 维输入空间内绕在 z hat 旋转(所以对于每个 λ值都会显示 784 维训练数据里对应的每个不同的部分)。
对于高正则化等级,此模型与最近质心分类器平行,且对抗距离最大化。当λ减少, 分类边界通过向低方差的方向倾斜提升它对训练数据的适应性。最终,少量错误分类的训练样本被覆盖,导致对抗距离减小,权重向量难以解释。
最后,我们可以发现每个模型中的两个典型映像 x、y(每类一个)和它们的镜像 x_m、y_m。它们在倾斜平面 w 上的投影直观地反映了线性分类中的对抗现象。
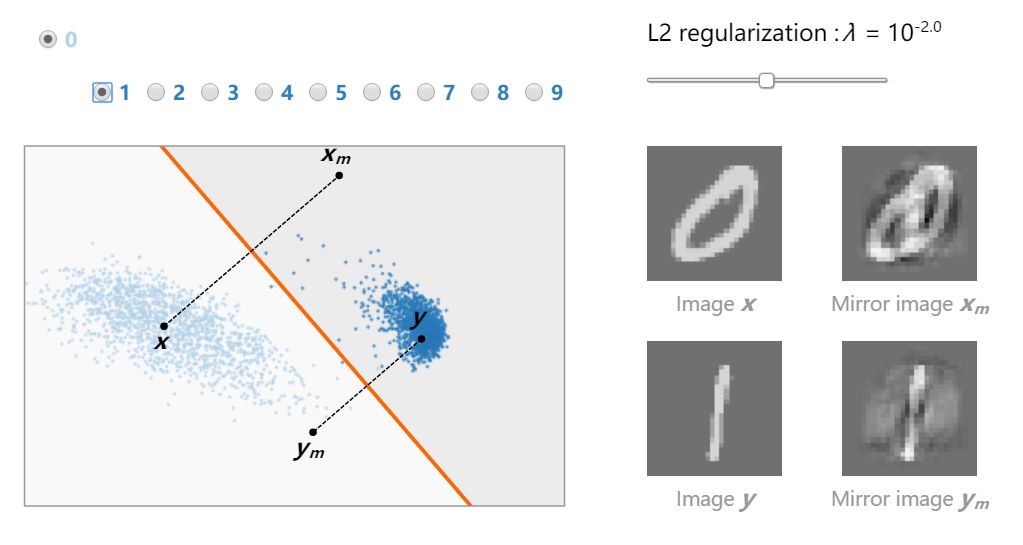
当倾斜角接近π/2 时,该模型易受强对抗样本 (||x_m−x||→0 and ||y_m−y||→0) 的影响。这是强过拟合的表现,它的发生与否取决于区分这两个类的难度 (对比 7s 和 9s 的分类以及 0 和 1 的分类)。
神经网络中的对抗样本
由于对抗距离和倾斜角度的等效性,线性问题非常简单,可以在平面上可视化。然而在神经网络中,类边界不是平坦的,对抗距离无法缩减为单个参数。尽管如此,它与线性问题仍有相似之处。
第一步:双层二值网络
假设 N 是一个双层网络,具有定义 R^d 中非线性二值分类器的单个输出。N 的第一层由权重矩阵 W_1 和偏置向量 b_1 指定,N 的第二层由权重向量 W_2 和偏置 b_2 指定。我们假设这两个层被校正线性单元的ϕ层分开,该校正线性单元应用函数 z→max(0,z)。对于 R^d 中的图像 x,我们将 x 到 N 的原始分数称为值:
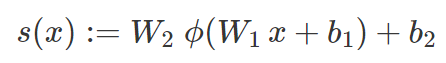
与线性问题相似,损失函数 f 在 T 上的经验风险可以表示为:
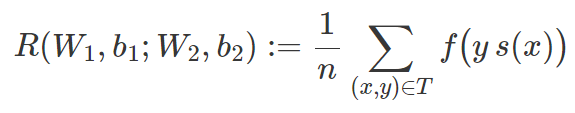
而训练 N 在于为选好的 f 找到 W_1、b_1、W_2 和 b_2 以及最小化 R。
ϕ 是分段线性的,并且在每个图像 x 周围存在局部线性区域 L_x,其中:
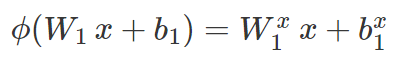
其中 W_1^x 和 b_1^x 是通过将 W_1 和 b_1 中的一些线分别置零而获得的。在 L_x 中,原始分数可以表示为:
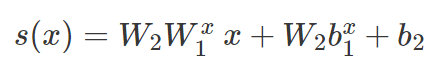
这可以被视为局部线性分类器 C_x 的原始分数,我们对线性问题的分析几乎可以不加修饰地应用。首先,我们观察到 s(x) 是一个折合距离。如果 d(x) 是 x 和 C_x 之间实际带符号的欧氏距离,我们可以得到以下公式:
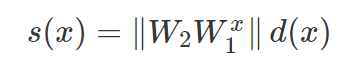
备注:
d(x) 也可以看做是 x 和由 N 定义的边界之间距离的线性近似(到最近的对抗样本的距离)。
W2W1^x 是 N 在 L_x 内的梯度。它是 x 的对抗方向,在实践中通过反向传播进行计算。
范数‖W2W1^x‖可以理解为损失函数的缩放参数(缩放现在是局部的,依赖于 x)。同时控制所有局部缩放的一个简单方法是将 L2 正则化项添加到独立作用于范数‖W_1‖和‖W_2‖的经验风险中(请记住,W1^x 中的权重是 W1 中权重的子集)。随着梯度下降,这相当于在每次迭代中衰减权重 W_1 和 W_2。随着梯度下降,这相当于在每次迭代中衰减权重 W_1 和 W_2。更确切地说,对于学习率η和衰减因数λ,权重衰减更新为:
W_1←W_1−ηλW_1 和 W_2←W_2−ηλW_2
在衰减因数小的情况下,允许缩放参数‖W_2W_1^x‖无限制增长,损失只惩罚误分类数据。将经验风险最小化相当于将训练集上的误差最小化。
随着衰减因数λ增大,缩放参数‖W_2W_1^x‖减小,损失函数开始惩罚越来越多的正确分类数据,使其距离边界越来越远。在这种情况下,L2 权重衰减可以看做是一种对抗训练。
总之,L2 正则化充当损失函数上的缩放机制,在线性分类和小型神经网络中都是如此。
随着梯度下降,利用大幅度权重衰减可以进行一种简单的对抗训练。
第二步:通常情况
之前的分析可以推广到更多的层数,甚至是非分段线性激活函数。更重要的发现是:
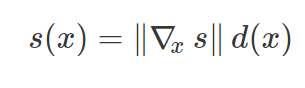
∇_x s 是 x 的原始分数梯度,d(x) 是网络定义的 x 和边界之间距离的线性近似。范数‖∇_x s‖构成损失函数的尺度参数,该参数可以用来控制权重的衰减。
这种思想不止适用于二分类。在多分类情况下,原始分数为一个向量,其元素被称作 logits。每个 logitsi(x) 通过 softmax 函数转换为概率 pi(x):
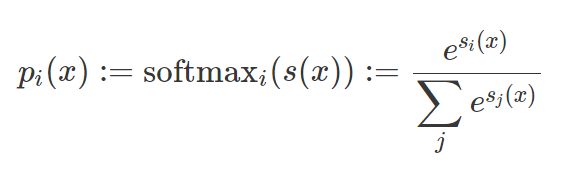
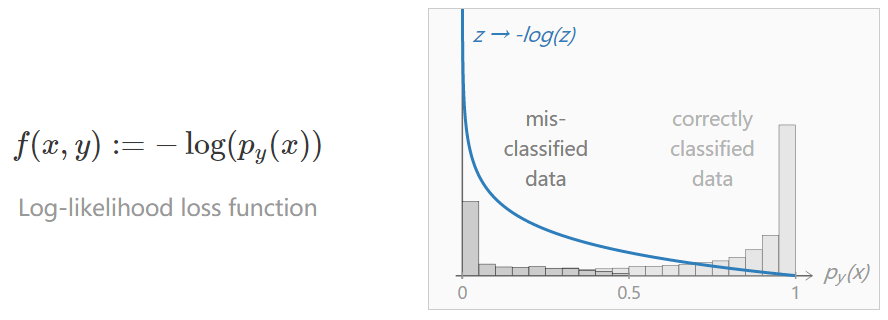
图像/标签对 (x,y) 正确分类的概率是 p_y(x)。对数似然损失函数通过将以下惩罚项归于 (x,y),使其接近于 1。
现在,改变权重衰减影响了 logits 的缩放,有效充当了 softmax 函数的 temperature 参数。当权重衰减非常小,生成的概率分布会很接近 one-hot 编码(p_y(x)≈0 or 1),只有分类错误的数据会产生非零惩罚。当权重衰减较大,生成的概率分布会变得更加的平滑,正确分类的数据也开始参与到训练中,从而避免了过拟合。
实际观察结果表明,现代深度网络都没有得到充分正则化:
1. 经常校准不良并产生过于自信的预测 [28]。
2. 总是收敛到零训练误差,即使在数据的随机标记任务中也如此 [29]。
3. 易受到小规模线性攻击 [2]。
举例:LeNet on MNIST
仅利用权重衰减对神经网络进行正则化就能处理对抗样本吗?这个想法非常简单,并已被考量过:Goodfellow 等人 [2] 观察到,在线性情况下,对抗训练「有点类似于 L1 正则化」。然而作者曾报道,在 MNIST 上对 maxout 网络进行训练时,L1 0.0025 的权重衰减系数「有点过大,导致模型在训练集上的误差超过 5%。较小的权重衰减系数可以带来成功的训练,但不会带来正则化效益。」我们再次将此想法付诸实践,得到的观察结果更加细致。使用较大的权重衰减显然不是灵丹妙药,但我们发现它确实有助于减少对抗样本现象,至少在简单的设置中如此。
考虑到 MNIST 上的的 LeNet(10 类别问题)。我们使用基线 MatConvNet[30] 实现,其架构如下:

我们分别用一个 10^−4 的小幅度权重衰减和一个 10^−1 的大幅度权重衰减训练该网络(我们将训练后的两种网络分别称为 LeNet_low 和 LeNet_high)。我们保持其它所有参数不变:训练 50 个 epoch,批尺寸为 300,学习率为 0.0005,动量为 0.9。
我们可以进行若干次观察。首先绘制两个网络的训练和测试误差,将其作为 epoch 的函数。
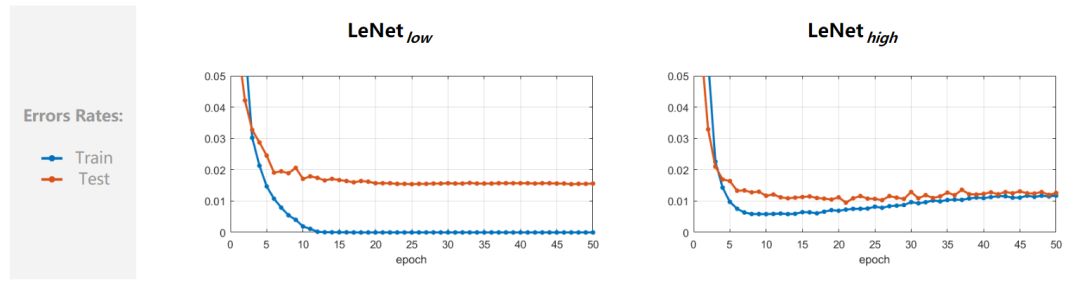
从图中可以看出,LeNet_high 的过拟合较少(训练和测试误差在训练结束时大致相等),并且比 LeNet_low 的性能稍好一点(最终测试误差为 1.2 % VS 1.6 %)。
我们还可以检查学到的权重。下面,我们计算它们的均方根值(RMS),并为每个卷积层随机选择滤波器。
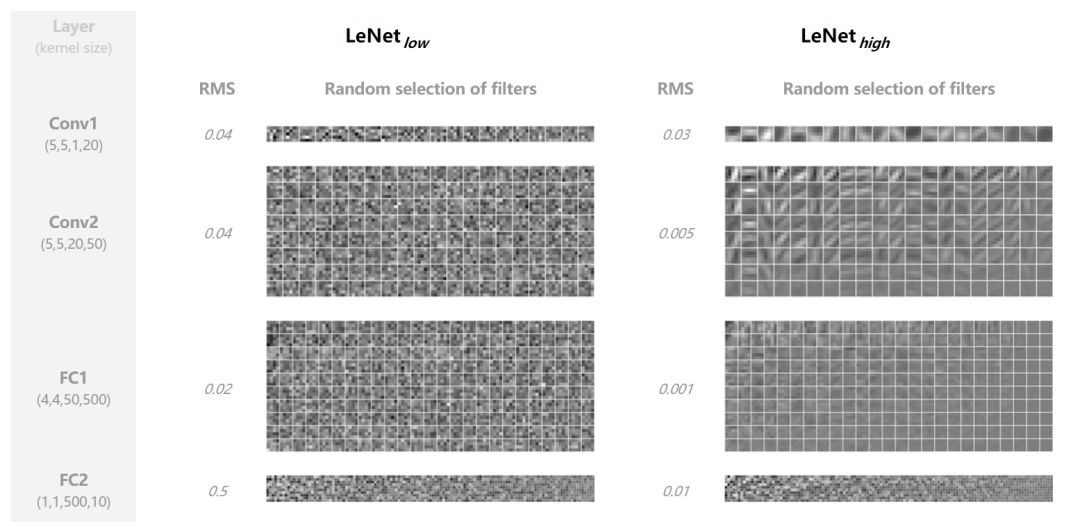
不出所料,随着较大权重衰减学习到的权重 RMS 要小得多。LeNet_high 的滤波器也比 LeNet_low 的滤波器要更平滑(参见 Conv1 和 Conv2 中边缘检测器带噪声的情况),并且它们的幅度在每个卷积层中变化更大(参见 Conv2 和 FC1 中的均匀灰度滤波器)。
最后,我们对两个网络进行相同的视觉评估:对于每个数字的随机实例,我们会生成一个高置信度对抗样本,目标是执行标签 0→1,1→2,…9→0 的循环排列。具体而言,通过对期望标签的概率进行梯度上升直到中值达到 0.95,来生成每个对抗样本。我们在下图展示了十幅原始图像 OI,以及它们对应的对抗样本 AE 和对抗干扰 Pert。

我们看到 LeNet_high 比 LeNet_low 更不容易受到对抗样本的影响:对抗干扰有更高的 L2 范数,这对观察者来说更有意义。
未来研究展望
虽然近年来对抗样本已经引起了广泛关注,并且它对机器学习的理论和实践来说都有很大意义,但迄今为止仍有很多不明之处。本文旨在提供一个关于对抗样本线性问题的清晰、直观概览,希望为后续工作打下坚实的基础。我们还发现 L2 权重衰减在 MINIST 的一个小型神经网络中发挥的作用超出预期。
但是,在更为复杂的数据集的更深模型中,一切都变得更加复杂。我们发现,模型的非线性越强,权重衰减似乎越没有帮助。这一局限可能很浅显,需要进一步探究(例如,我们可能应该在训练时更加注意对数几率的缩放)。或者深层网络的高度非线性可能是阻碍 L2 正则化实现一阶对抗训练类型的根本障碍。我们认为,要找到令人满意的解决方案,可能需要关于深度学习的崭新思路。

原文链接:https://thomas-tanay.github.io/post--L2-regularization/
参考文献:
1. *Intriguing properties of neural networks* [PDF] (https://arxiv.org/pdf/1312.6199.pdf)
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. and Fergus, R., 2013. arXiv preprint arXiv:1312.6199.
2. *Explaining and harnessing adversarial examples* [PDF] (https://arxiv.org/pdf/1412.6572.pdf)
Goodfellow, I.J., Shlens, J. and Szegedy, C., 2014. arXiv preprint arXiv:1412.6572.
3. *Deep Face Recognition.* [PDF] (http://www.robots.ox.ac.uk:5000/~vgg/publications/2015/Parkhi15/parkhi15.pdf)
Parkhi, O.M., Vedaldi, A., Zisserman, A. and others, ., 2015. BMVC, Vol 1(3), pp. 6.
4. *Practical black-box attacks against deep learning systems using adversarial examples* [PDF] (https://arxiv.org/pdf/1412.6572.pdf)
Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik, Z.B. and Swami, A., 2016. arXiv preprint arXiv:1602.02697.
5. *Adversarial machine learning at scale* [PDF] (https://arxiv.org/pdf/1611.01236.pdf)
Kurakin, A., Goodfellow, I. and Bengio, S., 2016. arXiv preprint arXiv:1611.01236.
6. *Robust physical-world attacks on machine learning models* [PDF] (https://arxiv.org/pdf/1707.08945.pdf)
Evtimov, I., Eykholt, K., Fernandes, E., Kohno, T., Li, B., Prakash, A., Rahmati, A. and Song, D., 2017. arXiv preprint arXiv:1707.08945.
7. *Synthesizing robust adversarial examples* [PDF] (https://arxiv.org/pdf/1707.07397.pdf)
Athalye, A. and Sutskever, I., 2017. arXiv preprint arXiv:1707.07397.
8. *Deepfool: a simple and accurate method to fool deep neural networks* [PDF] (https://arxiv.org/pdf/1511.04599.pdf)
Moosavi-Dezfooli, S., Fawzi, A. and Frossard, P., 2016. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2574—2582.
9. *Towards evaluating the robustness of neural networks* [PDF] (https://arxiv.org/pdf/1608.04644.pdf)
Carlini, N. and Wagner, D., 2016. arXiv preprint arXiv:1608.04644.
10. *Measuring neural net robustness with constraints* [PDF] (https://arxiv.org/pdf/1605.07262.pdf)
Bastani, O., Ioannou, Y., Lampropoulos, L., Vytiniotis, D., Nori, A. and Criminisi, A., 2016. Advances in Neural Information Processing Systems, pp. 2613—2621.
11. *Robustness of classifiers: from adversarial to random noise* [PDF] (https://arxiv.org/pdf/1608.08967.pdf)
Fawzi, A., Moosavi-Dezfooli, S. and Frossard, P., 2016. Advances in Neural Information Processing Systems, pp. 1632—1640.
12. *Ground-Truth Adversarial Examples* [PDF] (https://arxiv.org/pdf/1709.10207.pdf)
Carlini, N., Katz, G., Barrett, C. and Dill, D.L., 2017. arXiv preprint arXiv:1709.10207.
13. *Towards deep neural network architectures robust to adversarial examples* [PDF] (https://arxiv.org/pdf/1412.5068.pdf)
Gu, S. and Rigazio, L., 2014. arXiv preprint arXiv:1412.5068.
14. *Distillation as a defense to adversarial perturbations against deep neural networks* [PDF] (https://arxiv.org/pdf/1511.04508.pdf)
Papernot, N., McDaniel, P., Wu, X., Jha, S. and Swami, A., 2016. Security and Privacy (SP), 2016 IEEE Symposium on, pp. 582—597.
15. *Suppressing the Unusual: towards Robust CNNs using Symmetric Activation Functions* [PDF] (https://arxiv.org/pdf/1603.05145.pdf)
Zhao, Q. and Griffin, L.D., 2016. arXiv preprint arXiv:1603.05145.
16. *Towards robust deep neural networks with BANG* [PDF] (https://arxiv.org/pdf/1612.00138.pdf)
Rozsa, A., Gunther, M. and Boult, T.E., 2016. arXiv preprint arXiv:1612.00138.
17. *Dimensionality Reduction as a Defense against Evasion Attacks on Machine Learning Classifiers* [PDF] (https://arxiv.org/pdf/1704.02654.pdf)
Bhagoji, A.N., Cullina, D. and Mittal, P., 2017. arXiv preprint arXiv:1704.02654.
18. *Detecting Adversarial Samples from Artifacts* [PDF] (https://arxiv.org/pdf/1703.00410.pdf)
Feinman, R., Curtin, R.R., Shintre, S. and Gardner, A.B., 2017. arXiv preprint arXiv:1703.00410.
19. *On the (statistical) detection of adversarial examples* [PDF] (https://arxiv.org/pdf/1702.06280.pdf)
Grosse, K., Manoharan, P., Papernot, N., Backes, M. and McDaniel, P., 2017. arXiv preprint arXiv:1702.06280.
20. *On detecting adversarial perturbations* [PDF] (https://arxiv.org/pdf/1702.04267.pdf)
Metzen, J.H., Genewein, T., Fischer, V. and Bischoff, B., 2017. arXiv preprint arXiv:1702.04267.
21. *Ensemble Adversarial Training: Attacks and Defenses* [PDF] (https://arxiv.org/pdf/1705.07204.pdf)
Tramer, F., Kurakin, A., Papernot, N., Boneh, D. and McDaniel, P., 2017. arXiv preprint arXiv:1705.07204.
22. *Towards deep learning models resistant to adversarial attacks* [PDF] (https://arxiv.org/pdf/1706.06083.pdf)
Madry, A., Makelov, A., Schmidt, L., Tsipras, D. and Vladu, A., 2017. arXiv preprint arXiv:1706.06083.
23. *Attacking Machine Learning with Adversarial Examples* [link] (https://blog.openai.com/adversarial-example-research)
Goodfellow, I., Papernot, N., Huang, S., Duan, Y., Abbeel, P. and Clark, J., 2017.
24. *Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods* [PDF] (https://arxiv.org/pdf/1705.07263.pdf)
Carlini, N. and Wagner, D., 2017. arXiv preprint arXiv:1705.07263.
25. *Distance-weighted discrimination* [link] (http://www.tandfonline.com/doi/pdf/10.1198/016214507000001120)
Marron, J.S., Todd, M.J. and Ahn, J., 2007. Journal of the American Statistical Association, Vol 102(480), pp. 1267—1271. Taylor \& Francis.
26. *Robustness and regularization of support vector machines* [PDF] (http://www.jmlr.org/papers/volume10/xu09b/xu09b.pdf)
Xu, H., Caramanis, C. and Mannor, S., 2009. Journal of Machine Learning Research, Vol 10(Jul), pp. 1485—1510.
27. *Distilling the knowledge in a neural network* [PDF] (https://arxiv.org/pdf/1503.02531.pdf)
Hinton, G., Vinyals, O. and Dean, J., 2015. arXiv preprint arXiv:1503.02531.
28. *On Calibration of Modern Neural Networks* [PDF] (https://arxiv.org/pdf/1706.04599.pdf)
Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q., 2017. arXiv preprint arXiv:1706.04599.
29. *Understanding deep learning requires rethinking generalization* [PDF] (https://arxiv.org/pdf/1611.03530.pdf)
Zhang, C., Bengio, S., Hardt, M., Recht, B. and Vinyals, O., 2016. arXiv preprint arXiv:1611.03530.
30. *Matconvnet: Convolutional neural networks for matlab* [PDF] (http://www.vlfeat.org/matconvnet/matconvnet-manual.pdf)
Vedaldi, A. and Lenc, K., 2015. Proceedings of the 23rd ACM international conference on Multimedia, pp. 689—692.
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



