论文小综 | Pre-training on Graphs
本文转载自公众号:浙大KG。
作者:方尹、杨海宏,浙江大学在读博士,主要研究方向为图表示学习。
一种有效的解决此问题的方式是,在未标注的数据上通过自监督的方式对GNN模型进行预训练。这样,在下游任务上只需少量的标注数据对模型进行微调。
接下来我们将结合4篇论文简述预训练方法在图结构数据上的应用。
这篇文章提出的GPT-GNN通过生成式预训练的方式来初始化GNN,下图为GPT-GNN的预训练-微调流程。
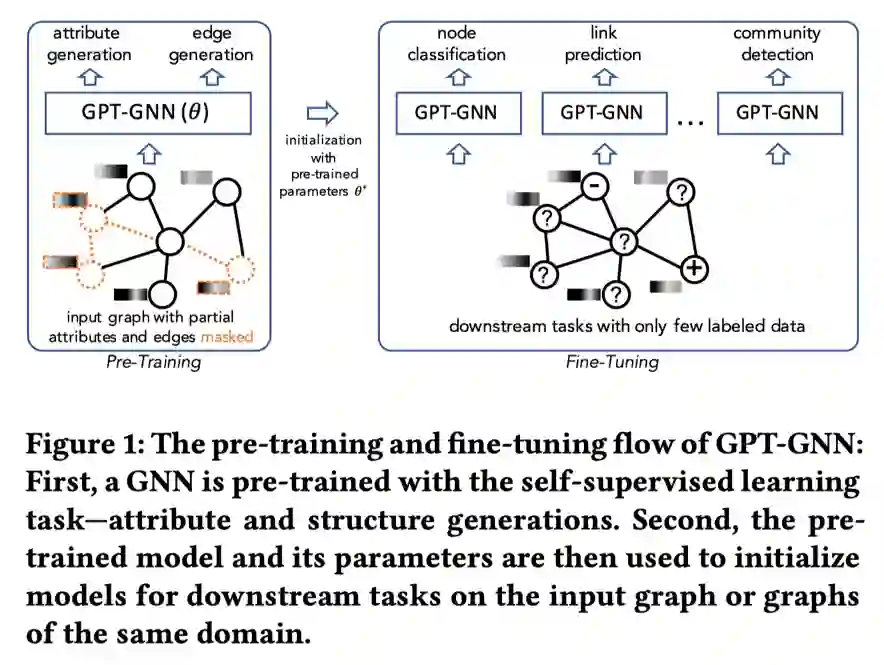
如上图所示,首先通过重构/生成输入图的结构信息和节点属性信息来预训练GNN,再将预训练好的GNN及参数用于下游任务,针对少部分的标注数据进行微调。
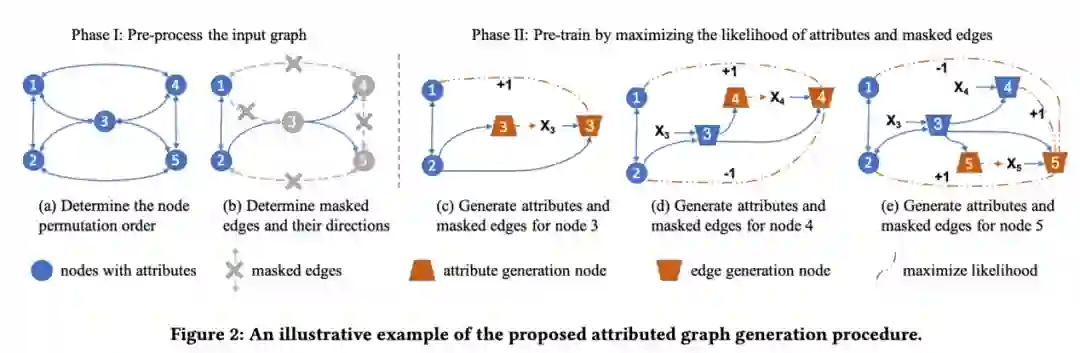
在预训练过程中,出于对训练效率的考虑,作者希望只对输入图运行一次GNN就计算出节点属性生成和边生成过程的损失,且同时进行节点属性生成和边生成两个任务。但是,边的生成过程需要用到节点的属性信息,如果两个生成过程同时进行,会导致信息泄漏。为避免该问题,文章将节点在不同的阶段分为属性生成节点和边生成节点两种类型。值得注意的是,同一节点在不同阶段既可以作为属性生成节点又可以作为边生成节点。
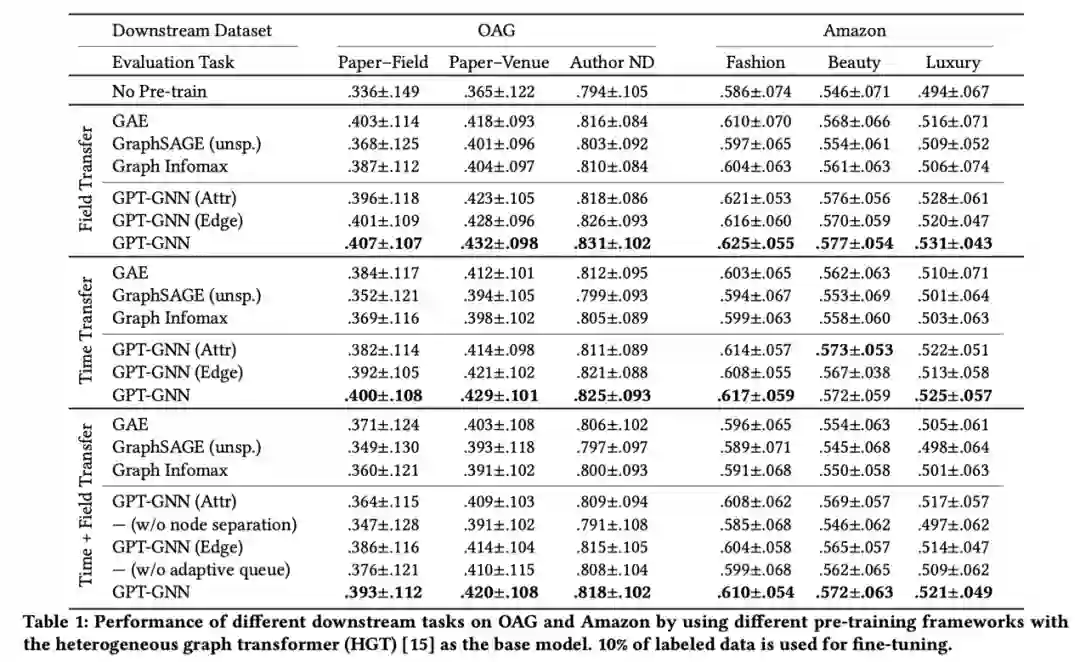
表中总结了在OAG和Amazon上使用不同的预训练方法在下游任务中表现出的性能。实验在预训练和微调阶段之间设置了三种不同的传输设置:分别使用来自2014年之前和2014年之后的数据进行预训练和微调(Time Transfer);将CS领域的论文用于下游微调,将其他领域的所有论文用于预训练(Field Transfer);在其他领域2014年之前的论文上进行预训练,并在CS领域2014年之后的论文上微调(Time+Field Transfer).总体而言,GPT-GNN框架显著提高了两个数据集上所有下游任务的性能。
发表会议:ICLR 2020
论文链接:https://arxiv.org/pdf/1905.12265.pdf
这篇文章提出了一种新的GNN预训练策略及自监督方法。但是,只在整张图或是只在单个节点上进行GNN预训练时带来的提升有限,甚至会导致在部分下游任务上出现负迁移。因此,本文在单个节点及整张图上进行预训练,使GNN同时学习局部和全局的信息传递。
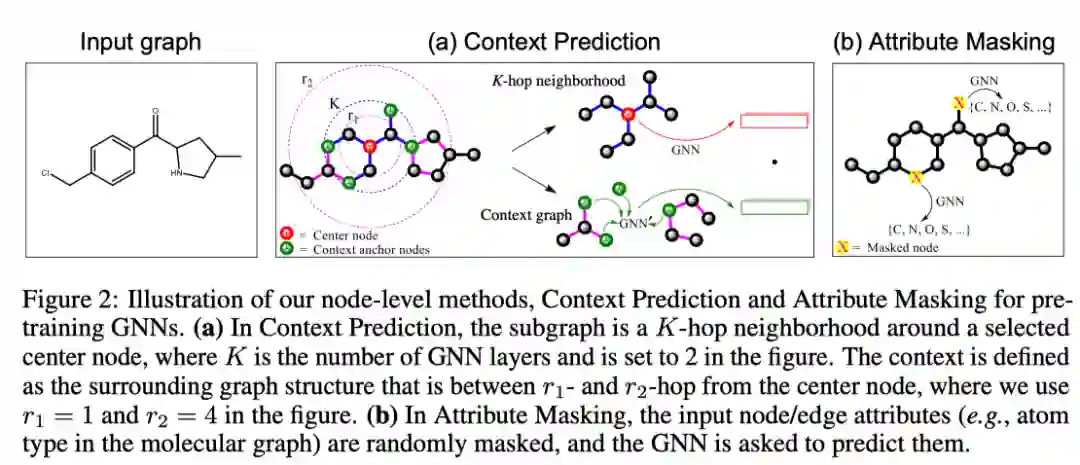
图为作者提出的节点级别的两种自监督学习方法。其中,在context prediction任务中,通过子图预测其周围的图结构,使模型具有通过中心节点预测周围结构的能力;在attribute masking任务中,让网络能够预测masked掉的节点或边,以学习图的性质及领域知识。
在进行节点级别预训练后,接着进行图级别的预训练。为了将特定领域的信息编码到图表示中,作者提出图级别的多任务的有监督预训练,共同预测多个图的标签,每个属性都对应于一个二分类任务,在得到图表示之后利用线性分类器进行分类。
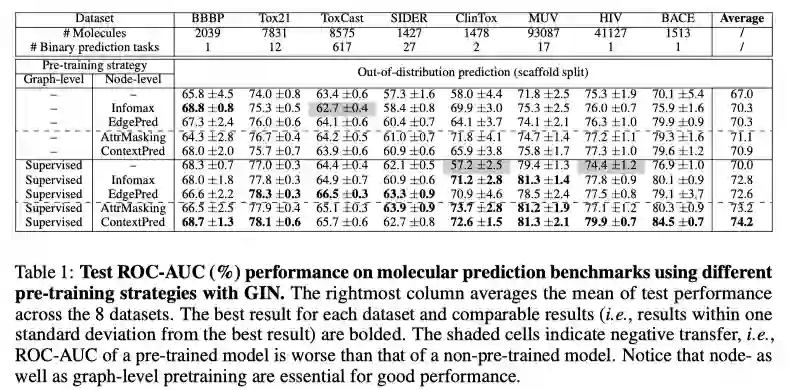
预训练结束后,将得到的GNN模型在下游任务中进行微调。图级别的表示经过线性分类器后预测下游任务的图标签。如下表所示,该预训练框架在分子性质预测和蛋白质功能预测任务中超越了SOTA.
发表会议:NeurIPS 2020
论文链接:https://proceedings.neurips.cc/paper/2020/file/94aef38441efa3380a3bed3faf1f9d5d-Paper.pdf
这篇文章认为不应将上下文和节点/边的信息分开考虑,由此提出Graph Representation frOm self-superVised mEssage passing tRansformer (GROVER)框架。
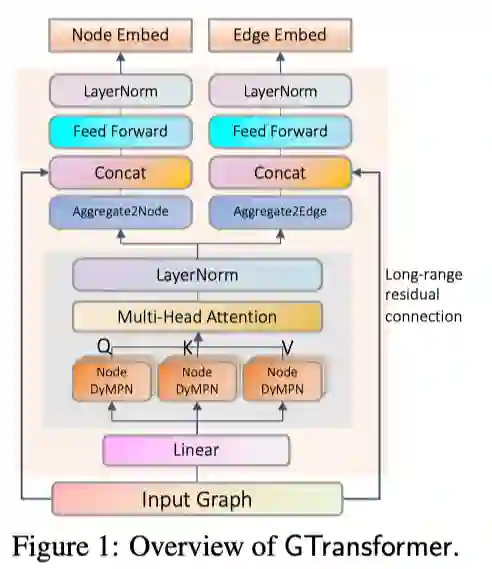
作者提出利用如上图所示的GNN Transformer模型捕捉两方面的信息:利用可随机选择跳数的动态信息传递网络dyMPN得到query, key, value的向量表示,可得到子图的结构信息;利用transformer作为encoder,可得到节点之间的全局信息。
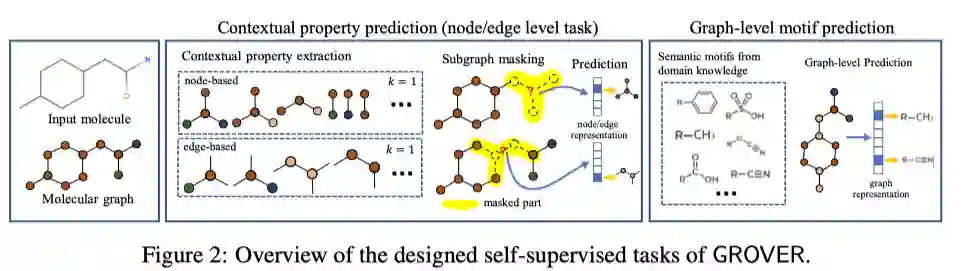
本文在节点和边级别及图级别上分别提出了新的自监督任务。在上下文属性预测任务中,将分子图输入GROVER后,可获得节点和边的表示,随机选择节点,获得其表示后,为了让该节点表示能够编码一些上下文的信息,统计固定跳数的子结构的统计信息作为标签,并用该节点的表示去预测其上下文统计信息。在图级别的主题预测任务中,作者统计了包含领域信息的子结构作为主题标签,预测图的主题标签实际上是一个多分类任务。
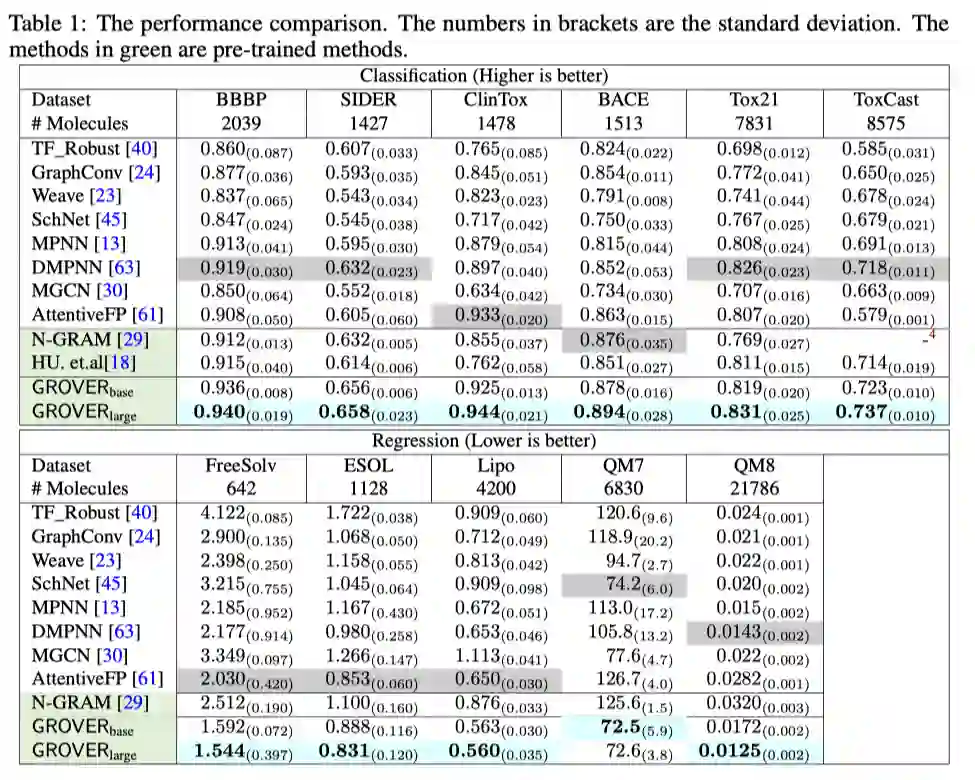
该论文探索了大规模(一千万个未标记分子数据、一亿参数)预训练GNN模型的潜力。利用自监督学习任务和提出的GTransfomer模型,GROVER可以从庞大的未标记分子数据集中学习到丰富的领域知识。通过对GROVER微调,可在11个benchmark上相比当前SOTA有不错的提升。
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
发表会议:KDD 2020
论文链接:https://arxiv.org/pdf/2006.09963.pdf
这篇文章设计了一种自监督的图对比编码(GCC)预训练框架,关注图结构的相似性,使两个局部结构相似的节点拥有相近的表示。
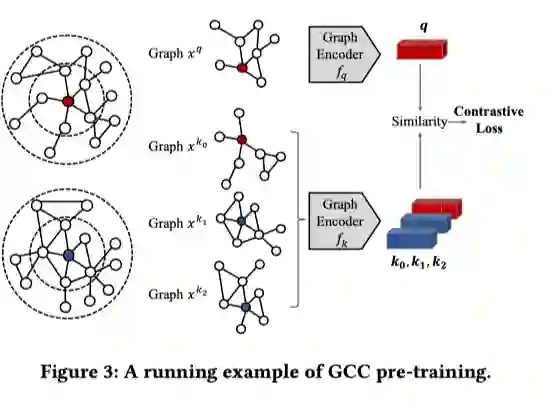
GCC可用于多种下游任务。本文探索了GCC在节点分类、图分类及相似搜索中的应用。具体地,在节点分类任务中,利用GCC预训练得到的编码器对节点的r-ego子图进行编码;在图分类任务中,对输入图直接进行编码;在相似搜索中,利用GCC分别对两个节点的r-ego子图进行编码,并计算编码后两者的距离作为相似度的度量。
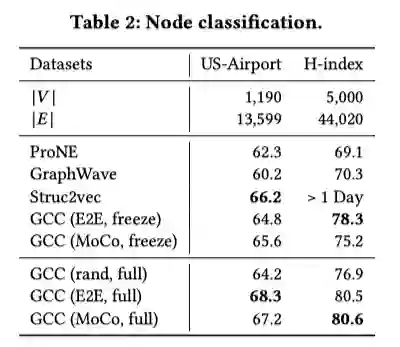
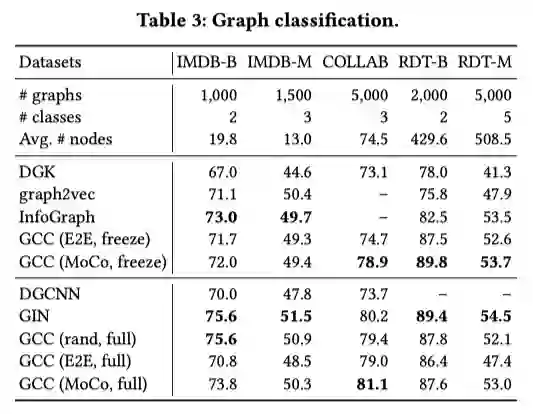
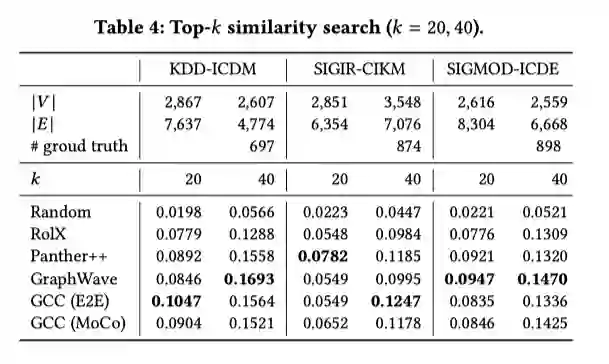
本文提出的GCC预训练框架,利用对比学习的方法,有效的捕捉了图的结构化信息,且可以迁移到各类下游任务及各类图中。实验结果表明了GCC在多中任务多个数据集上都获得了较为突出的表现,证明了GCC的有效性。
综上所述,为了提升模型的泛化性能,充分利用图结构数据本身丰富的结构信息和特征信息,上述论文使用不同的思路(包括引入对比学习,生成式预训练,模仿BERT的Masked Prediction策略等),将“预训练-微调”的思路应用于图表示学习中,从而进一步提升下游任务的性能。
“预训练-微调”相关方案的主要特点是充分利用大量无标注数据。这一点与大规模图结构数据高度契合。相关任务仍有较大的提升空间。除了图结构的信息挖掘之外,知识图谱等图结构数据中所包含的语义信息与推理逻辑仍未被充分挖掘。欢迎大家补充和交流。


浙江大学知识引擎实验室
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。