ACL 2020 | 香侬科技提出用Dice Loss缓解数据集数据不平衡问题

论文标题:
Dice Loss for Data-imbalanced NLP Tasks
论文作者:
Xiaofei Sun*, Xiaoya Li*, Yuxian Meng, Junjun Liang, Fei Wu, Jiwei Li
论文链接:
https://arxiv.org/pdf/1911.02855.pdf
今天,我们将给大家介绍香侬科技收录于ACL2020的第二篇文章, 题目为Dice Loss for Data-imbalanced NLP Tasks。
在本文中,我们提出用Dice Loss缓解大量NLP任务中的数据不平衡问题,从而能够提高基于F1评分的表现。
Dice Loss形式简单且十分有效,将Cross Entropy Loss替换为Dice Loss能够在词性标注数据集CTB5、CTB6、UD1.4,命名实体识别数据集CoNLL2003、OntoNotes5.0、MSRA、OntoNotes4.0,和问答数据集SQuAD、Quoref上接近或超过当前最佳结果。
自然语言处理中的“不平衡”数据集
在各类自然语言处理任务中,数据不平衡是一个非常常见的问题,尤其见于序列标注任务中。比如,对词性标注任务来说,我们一般使用BIEOS,如果我们把O视为负例,其他视为正例,那么负例数和正例数之比是相当大的。
这种不平衡会导致两个问题:
训练与测试失配。占据绝大多数的负例会支配模型的训练过程,导致模型倾向于负例,而测试时使用的F1指标需要每个类都能准确预测;
简单负例过多。负例占绝大多数也意味着其中包含了很多简单样本,这些简单样本对于模型学习困难样本几乎没有帮助,反而会在交叉熵的作用下推动模型遗忘对困难样本的知识。
总的来说,大量简单负例会在交叉熵的作用下推动模型忽视困难正例的学习,而序列标注任务往往使用F1衡量,从而在正例上预测欠佳直接导致了F1值偏低。
在本文,我们认为这种问题是交叉熵本身的特点带来的:交叉熵“平等”地看待每一个样本,无论正负,都尽力把它们推向1(正例)或0(负例)。但实际上,对分类而言,将一个样本分类为负只需要它的概率<0.5即可,完全没有必要将它推向0。
基于这个观察,我们使用现有的Dice Loss,并提出一个基于Dice Loss的自适应损失——DSC,在训练时推动模型更加关注困难的样本,降低简单负例的学习度,从而在整体上提高基于F1值的效果。
我们在多个任务上实验,包括:词性标注、命名实体识别、问答和段落识别。
对词性标注,我们能在CTB5上达到97.92的F1,在CTB6上达到96.57的F1,在UD1.4上达到96.98,在WSJ上达到99.38,在Tweets上达到92.58,显著超越基线模型。
对命名实体识别,我们能在CoNLL2003上实现93.33,在OntoNotes5上实现92.07,在MSRA上实现96.72,在OntoNotes4上实现84.47的F1值,接近或超过当前最佳。
对问答,我们能在SQuAD1/2和QuoRef上超过基线模型约1个F1值。
对段落识别,我们的方法也能显著提高结果。
从 Cross Entropy 到 Dice Losses
交叉熵损失(CE)
我们按照逻辑顺序来梳理如何从交叉熵损失到Dice Loss。我们以二分类作为说明,记输入为


首先,传统的交叉熵损失是:

显然,对每个样本,CE对它们都一视同仁,不管当前样本是简单还是复杂。当简单样本有很多的时候,模型的训练就会被这些简单样本占据,使得模型难以从复杂样本中学习。
于是,一种简单的改进方法是,降低模型在简单样本上的学习速率,从而得到下述加权交叉熵损失:

对不同样本,我们可以设置不同的权重,从而控制模型在该样本上学习的程度。但是此时,权重的选择又变得比较困难。
因为我们的目标是缓解数据集的不平衡问题从而提高基于F1评测指标的效果,我们希望有一种损失函数能够直接作用于F1。
Sørensen–Dice系数(DSC)
幸运的是,我们可以利用一种现有的方法——Sørensen–Dice系数(简称DSC)——去衡量F1。DSC是一种用于衡量两个集合之间相似度的指标:

如果我们令A是所有模型预测为正的样本的集合,令B为所有实际上为正类的样本集合,那么DSC就可以重写为:

其中,TP是True Positive,FN是False Negative,FP是False Negative,D是数据集,f是一个分类模型。于是,在这个意义上,DSC是和F1等价的。
既然如此,我们就想直接优化DSC,然而上述表达式是离散的。为此,我们需要把上述DSC表达式转化为连续的版本,从而视为一种soft F1。
对单个样本x,我们直接定义它的DSC:

注意这和一开始DSC的定义是一致的。可以看到,若x是负类,那么它的DSC就为0,从而不会对训练有贡献。为了让负类也能有所贡献,我们增加一个平滑项:

但这样一来,又需要我们根据不同的数据集手动地调整平滑项。而且,当easy-negative样本很多的时候,即便使用上述平滑项,整个模型训练过程仍然会被它们主导。基于此,我们使用一种“自调节”的DSC:

比较上面两个DSC,可以发现,


从导数上看,一旦模型正确分类当前样本(刚刚经过0.5),DSC就会使模型更少关注它,而不是像交叉熵那样,鼓励模型迫近0或1这两个端点,这就能有效避免因简单样本过多导致模型训练受到简单样本的支配。
事实上,这比较类似Focal Loss (FL),即降低已分好类的样本的学习权重:

不过,FL即使能对简单样本降低学习权重,但是它本质上仍然是在鼓励简单样本趋向0或1,这就和DSC有了根本上的区别。
因此,我们说DSC通过“平衡”简单样本和困难样本的学习过程,从而提高了最终的F1值(因为F1要求各类都有比较好的结果)。
Dice Loss(DL)与Tversky Loss(TL)
除了上述DSC之外,我们还比较了两种

特别地,在TL中,如果
损失总结
最后,我们来总结一下各损失:



我们把后面三个损失统称为Dice Loss。
实验
词性标注
我们首先在词性标注任务上实验,数据集有中文的CTB5/6、UD1.4和英文的WSJ、Tweets。基线模型包括Joint-POS、Lattice-LSTM及BERT。下表分别是中文和英文的实验结果:
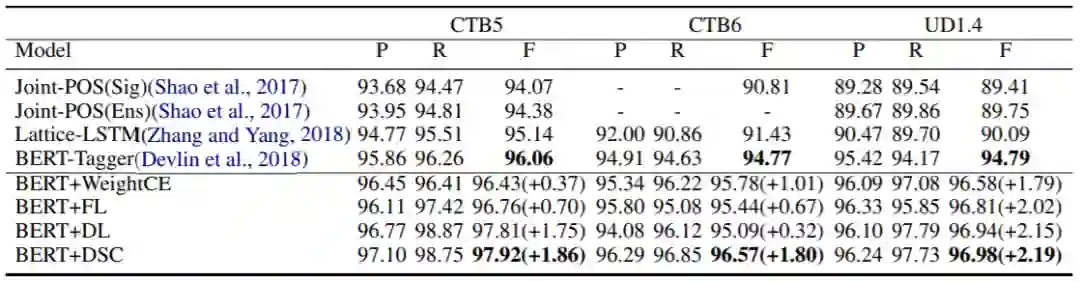
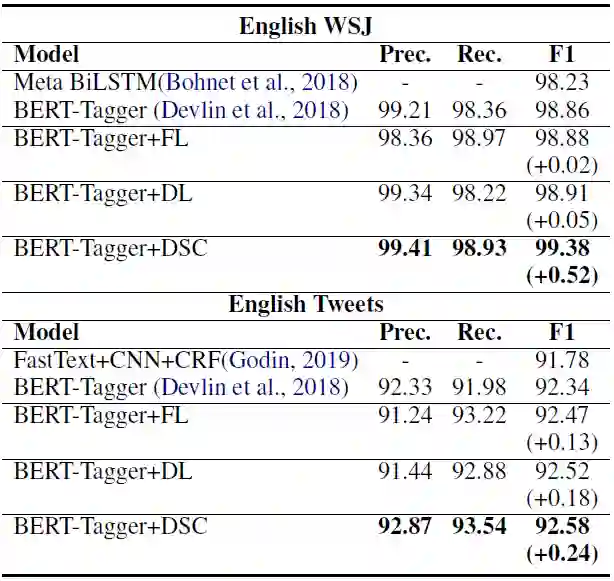
可以看到,DSC在各个数据集上都能得到最好的效果提升,而其他方法的提升并不一致。
命名实体识别
下面我们在命名实体识别任务上实验,数据集有中文的Ontonotes4、MSRA和英文的CoNLL2003、OntoNotes5,基线模型有ELMo、CVT、BERT-Tagger与BERT-MRC。下表是实验结果:
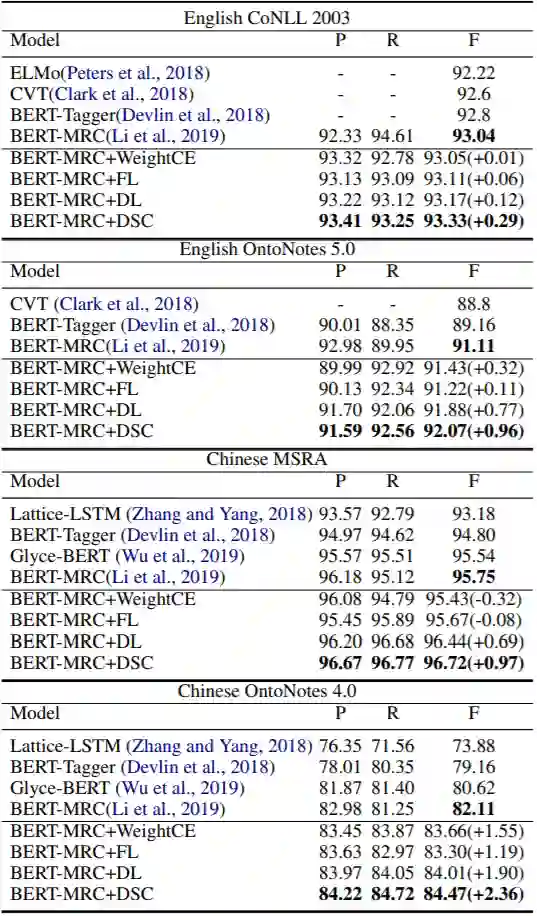
与词性标注一样,DSC能够保持效果一致的提高。
问答
下面我们在SQuAD1/2和QuoRef上对问答任务进行实验,基线模型有QANet、BERT与XLNet,下表是实验结果:
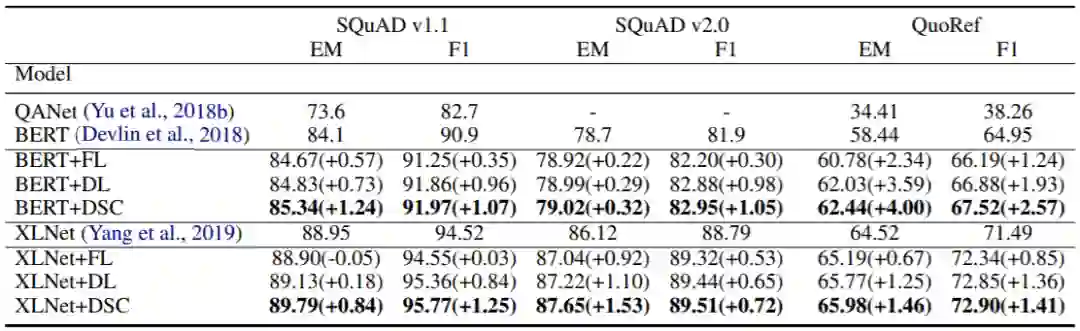
无论是对BERT还是对XLNet,DSC都有显著的提升。
段落识别
段落识别是一个分类任务,需要判断两个给定的段落语义是否相同。和标注任务相比,该任务的不平衡度要轻得多。下表是实验结果:
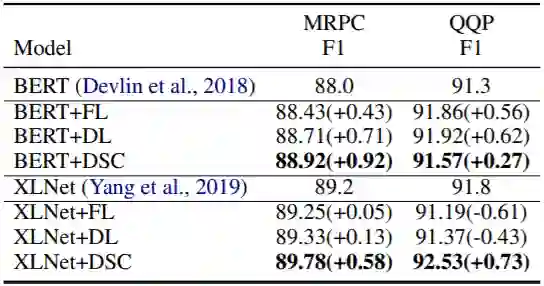
尽管效果提升没有序列标注任务大,但仍然有接近一个点的提升。
不平衡程度的影响
既然Dice Loss的提出是为了缓解数据分布不平衡的问题,我们自然想问,不平衡的程度对效果的提升影响如何。我们使用段落识别的QQP数据集进行实验。QQP原始数据包含37%的正类和63%的负类,我们使用下述方法改变数据分布:
+positive:使用同义词替换等方式增加正类数量,使数据分布平衡(50:50)。
+negative:使用同义词替换等方式增加负类数量,使数据分布更加不平衡(21:79)。
-negative:随机删除负类,使数据分布平衡(50:50)。
+positive&+negative:同时增加正类和负类,使数据分布平衡(50:50)。
以上方法最终都得到了相同大小的数据集。下表是实验结果:

首先观察到,数据的平衡性对最终结果影响是非常大的,即使是基线模型BERT,大体上讲,数据越不平衡,最终结果就越差,当然这也受到整体数据量的影响。
而对平衡的数据集(+positive,+positive&+negative)来说,DSC带来的提高略小于不平衡的数据集(original,+negative),而-negative提高最差可能与它的数据量有关。
对以准确率为指标的任务的影响
通过上述实验我们知道,Dice Loss有助于提高F1值的表现,那么对以准确率为指标的任务又如何呢?我们在SST2和SST5上实验,下表是实验结果:
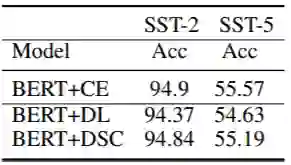
可以看到,使用Dice Loss实际上是降低了准确率,这是因为Dice Loss考虑的实际上是类间的“平衡”,而不是笼统地考虑所有的数据。
小结
本文使用现有的Dice Loss,并提出了一种新型的自适应损失DSC,用于各种数据分布不平衡的NLP任务中,以缓解训练时的交叉熵与测试时的F1的失配问题。
实验表明,使用该损失可以显著提高标注任务、分类任务的F1值,并且也说明了F1效果的提升与数据不平衡的程度、数据量大小有密切的关系。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



