样本不平衡数据集防坑骗指南
一、序
不管你在数据科学的哪一个方向研究,可能数据不平衡(imbalanced data)都是一个常见的问题。很多人总是会强调极端状况下的数据不平衡,如医疗数据,犯罪数据等。但在实际中,更多的不平衡并不会显得那么极端。如果你关注过kaggle上的比赛冠军的分享,你会发现观察数据尤其是了解不平衡情况经常会是第一步(当然还会有其他的预处理和分析)。

除了数据本身外,有些算法如决策树,Logistic回归等对数据的不平衡比较敏感,算法取向会明显朝着数据量比较大的类。如果出现极端不平衡的情况,这些算法很可能完全失效。另外一个问题是任务的评价指标,准确率仍然是很多任务的评价指标(虽然为了解决这个问题提出了F-score等更多的评价方法),尤其是在一些比赛中,这种评价方式也会驱使算法更多关注数据比较多的类。
二、数据层面策略:采样技术
利用采样技术来平衡数据的做法简单直观却又非常有效。尤其是现在深度学习中广泛采用了数据增强技术后,和采样技术结合更是如虎添翼,(如果不用数据增强,只进行类似过采样的操作的话,某类中的某些样本多次重复出现可能会对特征表征学习带来伤害)。
2.1 随机欠采样和随机过采样
随机欠采样和随机过采样是一对好兄(基)弟(友),各有长短。
随机欠采样是针对数据较多的类别下手。通过随机从样本较多的数据类中采样得到一个较小的子集,将此子集和数据较少的类结合作为新的数据集。
比如,如果正样本有50例,负样本有950例,正样本比例为5%。在负样本中随机选出10%,为95例,与正样本组合(95+50)组成新的训练集,此时正样本所占的比例为35%,比原始的5%有了很大改进。
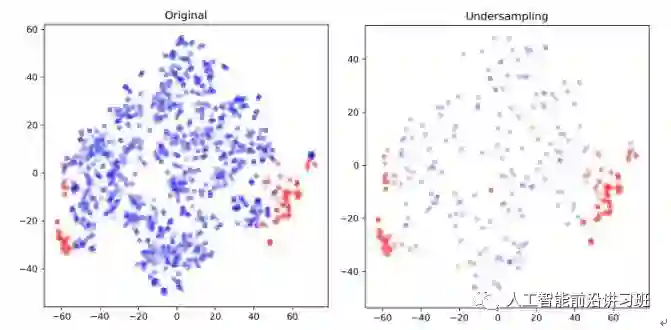
欠采样的优缺点都很明显。优点是在平衡数据的同时减小了数据量,加速训练,尤其是当样本集规模很大的时候。但是这也正是造成其缺点的主要原因,数据减少会影响模型的特征学习能力和泛化能力。
与欠采样相反的是,过采样通过随机复制样本较少类别中的样本以期达到减少不平衡的目的。比如,如果正样本有50例,负样本有950例,正样本比例为5%。如果将正样本复制10次,那么新的数据正样本所占比例接近30%。
过采样的优缺点也很明显。优点是相对于欠采样的方法,过采样没有导致数据信息损失,在实际操作中一般效果也好于欠采样。但是由于对较少类别的复制,过采样增加了过拟合的可能性。
2.2 基于聚类的过采样
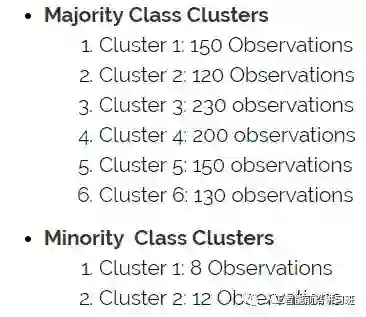
这种方法先对不同的类别分别进行聚类,一般情况下设置样本较多的类聚类中心数目较多,而样本较少的类聚类中心较少。然后通过对每个cluster进行过采样/欠采样使原始类别中所有的cluster有相同数目的样本。
比如数据集汇总正样本有20,负样本有980,正样本所占比例为2%。对每个类别分别聚类如下:
然后依据聚类中心进行过采样/欠采样使原始类中每个cluster样本数目相同。
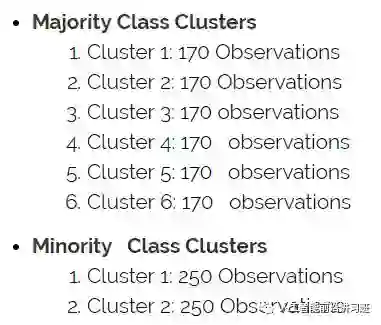
此时正样本所占比例为33%。
这种方法通过聚类作为中介不但一定程度上缓解了类间的样本不平衡问题,还一定程度上缓解了类内的不平衡问题。但是这种方法和一般的过采样方法一样容易使模型对训练数据过拟合。
2.3 Informed Over Sampling (SMOTE)
由于在一般的过采样方法中直接复制少数类别中的样本容易造成模型泛化能力下降,所以就提出了这种利用人造数据的方法减弱过采样带来的过拟合的方法。这种方法先对数据较少的类别抽取一个子集,然后对这个子集进行过采样。但是这时的过采样不再是直接复制,而是利用人为的方法生成相似的样本。
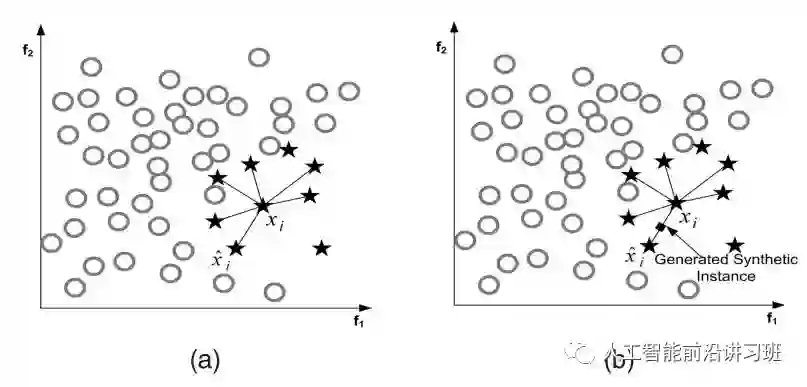
SMOTE的人为生成方式很简单,如下图b中的一个样本xi,先找到其近邻的K个样本,然后从这几个近邻样本中随机选取一个xi^hat,利用以下公式即可得到新的人工生成样本:
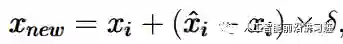
如果是下图所示的二维情况,可以看成是在两者连线中间选择了一个点作为人工样本。
比如,有20个正样本,980个负样本,正样本所占比例为2%。从正样本中随机选取15个样本进行人工合成过采样,得到300个相似的样本。此时正样本所占的比例为24%左右。
这种方法的优点是通过人造相似样本取代直接复制的方法减弱了过拟合,也没有丢失有用的信息。但是这种方法在进行人工合成样本时没有考虑进去近邻样本可能来自于不同类别,导致增大类别间的重叠。另外SMOTE在数据维度很高时效率很低。
2.4 Borderline-SMOTE
SMOTE没有考虑样本较少的那个类别(minority classes)自身潜在的分布,Borderline-SMOTE在此上面进行了优化。
MSMOTE通过计算minority classes最近邻K个样本中属于原始类别(minority和majority)的比例将minority classes分为三个不同的组:Danger,Safe,Noise。如下图中A属于Noise,B属于Safe,C属于Danger。
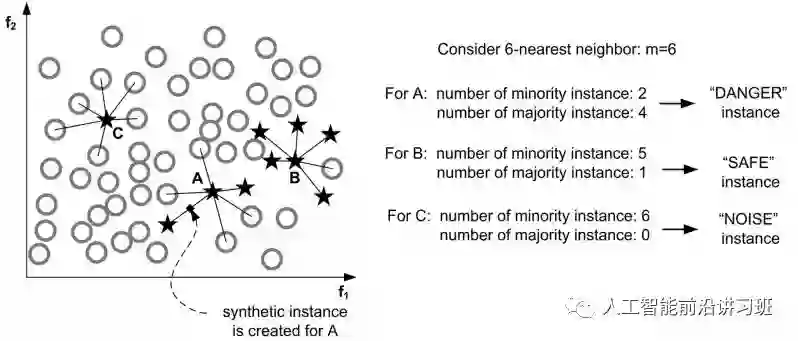
然后只对Danger中的样本采用SMOTE算法,其他两类不再过采样。
除了Borderline-SMOTE外,还有ADASAN等自适应人工合成样本的方式,读者可查阅文献进行阅读。
2.4 基于数据清洗的SMOTE
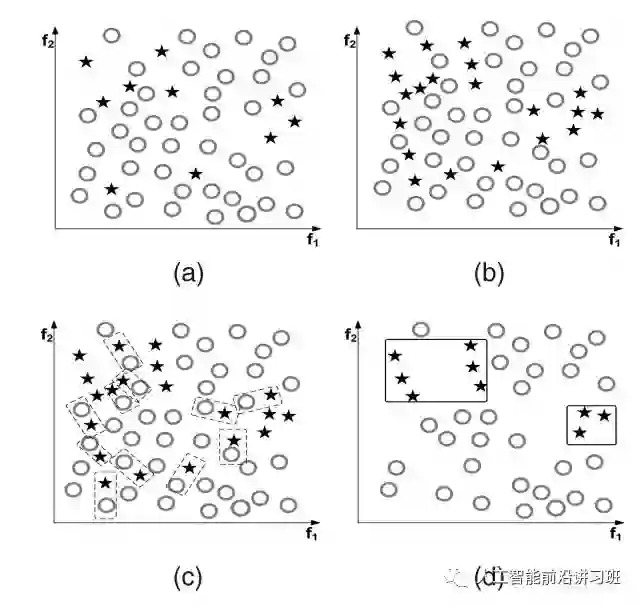
正如前文所示,实际的数据中不但存在样本不均衡的问题,还经常伴随着不同类别的样本重叠问题,如下图a所示。如果直接进行SMOTE过采样,得到的结果如b所示,虽然minority classes样本数目增多了,但是样本的重叠反而加剧了,很明显这并不有利于分类。
如果此时有一种数据清洗技术可以去掉一些重叠样本,那么对分类来说将会十分有益。这就是将要讲述的Tomek Links方法。对于一对样本(x_i, x_j)其中x_i来自于minority classes,x_j来自于majority classes。如果不存在一个x_k使得:
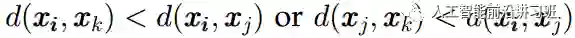
那么称(x_i, x_j)是一个TomekLink。如下图c中的虚线矩形框中的样本对。当得到TomekLink之后,移去所有的Tomek Link并且反复进行。得到结果如d所示。此时样本的重叠大大减小。Tomek Link的优势在于可以和很多算法结合起来,如CNN+Tomek Link。
三、 算法策略: 集成算法
集成算法在Kaggle比赛中基本是所有冠军的必备武器,它也是解决非平衡数据问题的一个很重要手段。集成策略通常通过将多个分类器结果进行融合来提高算法效果。
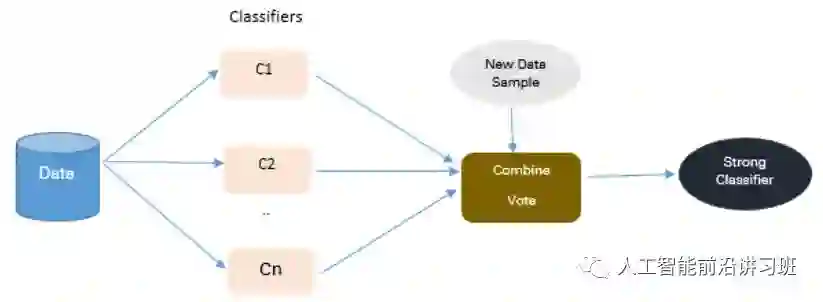
3.1 Bagging
Bagging是Bootstrap Aggregating的缩写。传统的Bagging算法先生成n个不同的bootstrap训练样本集,然后将算法分别在每个样本集上进行训练,最后将所有的预测结果进行融合。Bagging在一定程度上可以减弱过拟合。和Boosting不同的是,Bagging是允许有放回的数据重采样。
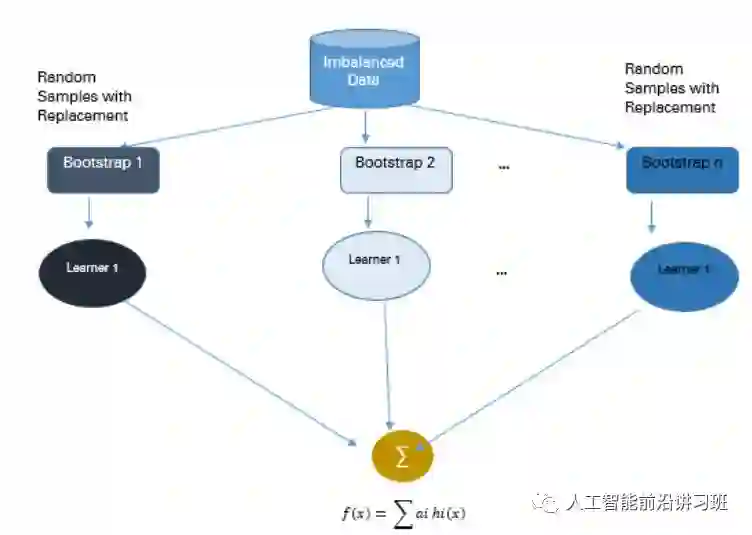
Bagging的优点是可以提高算法的稳定性和准确率,减弱算法的variance和过拟合,而且在噪声样本环境下,Bagging通常比Boosting表现要好。但是Baging的问题是只在基础分类器都能产生想对不错的结果的时候work,如果有的基础分类器结果很差,可能会很严重的影响Bagging的结果。
3.2 Boosting
Boosting通过将弱分类器结合起来构成强分类器。在新一轮的迭代中,新的分类器更加关注上一轮训练中分类错误的样本,给这些样本赋予更大的权重。Ada Boost是Boosting算法中的一个代表。
注意在Boosting算法中所谓的弱分类器的基本假设是其要率好于随机选择的结果,这样才能保证集成之后能提供一个更好的效果。
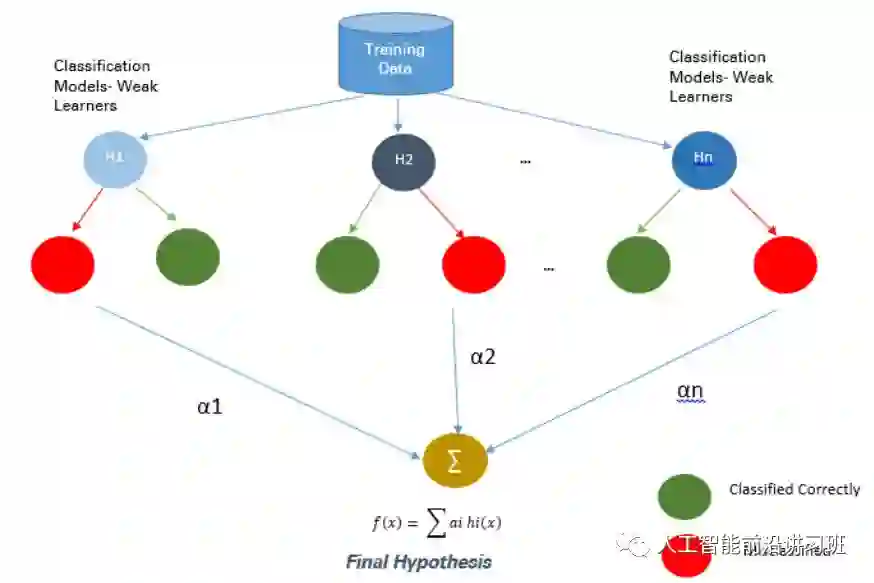
Boosting算法实现起来很容易并且有很好的泛化性,但是其缺点是对于噪音和离群点比较敏感。
在深度学习流行之前,XG Boost一度占据了Kaggle冠军的大半壁江山。即使现在深度学习如此火热,XG Boost仍然没有落伍,Kaggle比赛仍有很多将其与深度学习结合取得冠军的例子。XG Boost由于其并行执行的特性使其10倍速度于其他的Boosting技术。并且其可以很容易的使用各种自定义的优化器和评价标准,而且其在处理missing value方面表现非常好。
四、不平衡数据导向的评价方式进化史
话不多说先上图,本节主要叙述都将基于本图。
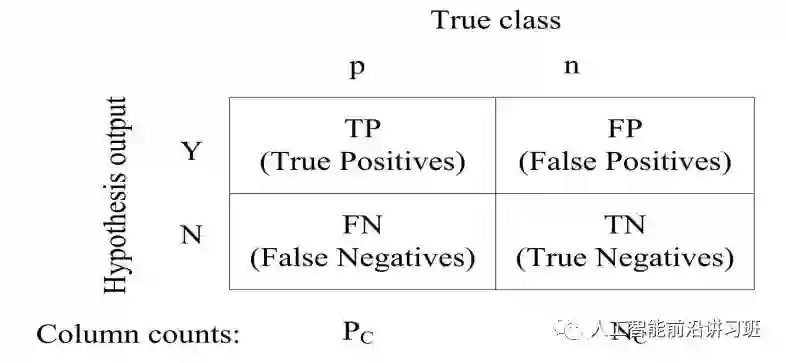
如果您熟悉这个图,那混淆矩阵想来不是一个陌生的概念。最常见的算法评价方式莫不过是准确率和错误率,用公式表示就是:
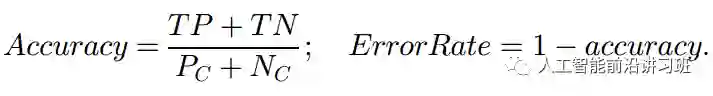
虽然在多数情况下准确率和错误率可以很好的评估算法性能,但如果遇到不平衡数据,准确率和错误率显然不合适。比如正样本有5个,负样本有95个,如果将所有样本都分为负样本,仍然可以得到95%的准确率。这不是一个假设,这是实际不平衡数据情况下算法经常出现的问题。早期有不少关于评价方式设计的研究,出现了我们现在熟悉的F-score, ROC等评价方式。
4.1 F-Measure
F-Measure的计算方式如下:

Percision可以简单地记为“你认为是正类的样本中到底有多少是对的”,recall可以记为”实际上是正类的有多少被你检测出来了”。系数β用来调整percision和recall的相对重要程度,通常取1.
尽管F-Measure相对于准确率和错误率这种评价方式有很大提高,但仍然回答不了像“在多种样本数据分布下如何对比算法性能”这种问题。此时ROC便被提出了。
4.2 ROC、AUC
ROC通过计算真阳性比例(true positive rate)和假阳性比例(false positive rate)得到。
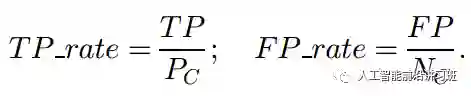
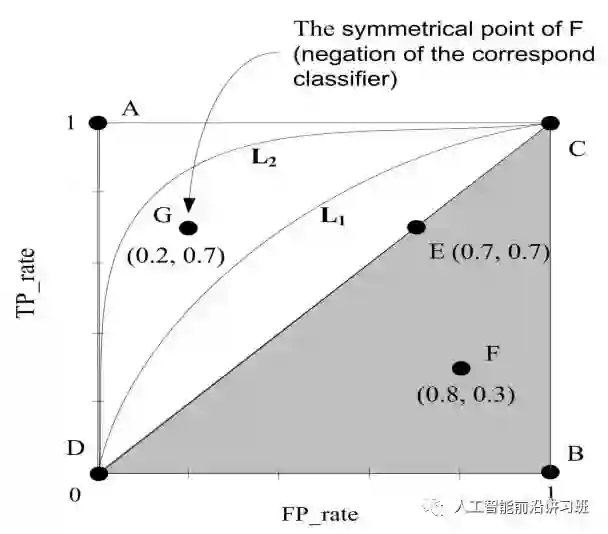
在ROC图中,点A(0,1)代表最好的分类效果。当然实际中一般不可能的达到,所以越接近A点的分类器算法越好。而在对角线上的算法如E,相当于随机选择,而阴影中的算法就可以直接爆炸了,还不如随机选择的算法可能感觉自己生不如死吧。但是换个角度想,类似点F所代表的算法是否就真的是个total loser呢?实际上不见得,如果将其正负类结果互换,F点就由(0.8, 0.3)变成了(0.3,0.8)。所以遇到这种情况也不要抱头痛哭,这说明分类器使用信息的姿势不对,而不是没学到信息。
soft-type的分类器可以输出一系列连续的数值表示样本属于某一类的概率,这时通过设定阈值可以得到一系列在ROC空间的点,也就是我们常说的ROC曲线。而ROC曲线下的面积就是AUC。AUC越大代表算法性能越好。
4.3 PR、AUC
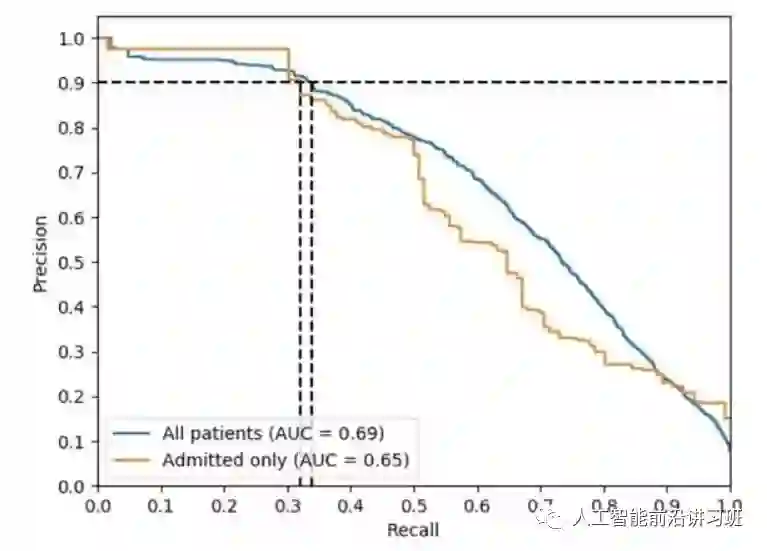
ROC曲线提供了一个非常强大的衡量算法性能的标准,但是在数据倾斜很严重的数据集中ROC对算法会显得太过乐观。如果负类数据远多于正类(Nc >> Pc),当分类器在假阳性(false positive)上有剧烈变化时, FP_rate却没有明显的改变,因为Nc此时占有支配地位,所以ROC就显得不是很合理。然而此时persion可以很好的检测到这种变化。
如下图所示,PR曲线下面积也代表AUC。和ROC不同的是,算法越靠近右上角代表性能越好。
五、总结
在面对不均衡数据时,没有一步到位的算法可以解决,可能需要尝试多种策略寻找最适应数据集的算法。在大多数情况下,数据合成方法中的SMOTE及其衍生品效果优于其他数据平衡方法。经常的做法是将SMOTE等数据合成方法与Bagging和Boosting等算法结合起来一起使用。
不平衡数据处理算法的研究现在依然不少,只是多数情况下会与具体研究的方向结合起来。如2017年的focal loss在目标检测领域大获成功,其简洁又有效的思路让人眼前一亮。
由于篇幅和时间限制,另外一篇实践导向的非常好的文章不在本文中整理,请读者自行参考:
《8 Tactics to Combat Imbalanced Classes in Your Machine LearningDataset》。
注:本文主要整理自综述“learningfrom imbalanced data”以及analyticsvidhya.com等国外博主的分享

历史文章推荐:
AI综述专栏 | 脑启发的视觉计算2017年度关键进展回顾(附PPT)
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI
