21种NLP任务激活函数大比拼:你一定猜不到谁赢了
选自arXiv
机器之心编译
参与:panda
在用神经网络学习自然语言处理任务时,选择哪个激活函数更好?去年谷歌大脑提出的 swish 函数又如何?不同的研究者和工程师可能会给出不同的答案。德国达姆施塔特工业大学的一篇 EMNLP 论文给出了 21 种激活函数在 NLP 任务上的实验比较结果,发现比较冷门的 penalized tanh 函数表现优异。研究者也已在 GitHub 上发布了相关代码和数据。
论文:https://arxiv.org/pdf/1901.02671.pdf
项目:https://github.com/UKPLab/emnlp2018-activation-functions

摘要:激活函数在神经网络中发挥着重要的作用,它们的非线性为深度学习的成功做出了重要的贡献。目前最流行的激活函数之一是 ReLU,但研究者最近又提出或「发现」了几种竞争者,其中包括 LReLU 函数和 swish。大多数研究都是在少数几种任务上比较新提出的激活函数(通常是图像分类方面的任务),且对比的竞争者也少(通常是 ReLU),而我们首次在 8 种不同的 NLP 任务上进行了 21 种激活函数的大规模比较。
我们发现一种很大程度上不为人知的激活函数在所有任务上都表现得最稳定,即所谓的 penalized tanh 函数。我们还表明它能在 LSTM 单元中成功替代 sigmoid 和 tanh 门,并能在一种高难度的 NLP 任务上取得优于标准选择 2 个百分点的表现。
1 引言
激活函数是神经网络的一大关键组件,因为它们可将原本线性的分类器转换成非线性的。神经网络近些年在众多任务上表现优异这一事实已经证明这种转换至关重要。尽管理论上而言,Sigmoid 或 tanh 等不同的激活函数往往是等价的——它们都能近似任意的连续函数(Hornik, 1991),但不同的激活函数往往会在实践中表现出非常多样的行为。
举个例子,sigmoid 是一种在神经网络实践中占据了几十年主导地位的激活函数,最终却被证明不适用于学习,原因是(根据公认的看法)它的导数很小,这可能会导致梯度消失问题。在这方面,事实证明所谓的 ReLU 函数(Glorot et al., 2011)要更加适用得多。它在正的区域有一个恒等导数,因此宣称更不易受梯度消失问题的影响。因此它也已经成为了目前最流行的激活函数(有争议)。对 ReLU 的成功的认可让人们提出了多种扩展(Maas et al., 2013; He et al., 2015; Klambauer et al., 2017),但没有任何一种能一样受欢迎,原因很可能是 ReLU 很简洁,而不同扩展在不同数据集和模型上所报告的增益往往是不一致的或较低(Ramachandran et al., 2017)。
人们已经为激活函数认定了多种被认为对学习成功很重要的特征属性,比如与它们的导数相关的属性、单调性以及它们的范围是否有限。但是,Ramachandran et al. (2017) 在近期一项研究中使用了自动搜索来寻找表现优良的全新激活函数,他们的搜索空间包含了基本一元和二元函数的组合,比如 max、min、sin、tanh 或 exp。他们发现很多函数都不具备被认为有用的属性,比如非单调激活函数或不满足 ReLU 保留梯度的属性的函数。
实际上,他们最成功的函数——他们称之为 swish,并不满足这两个条件。但是,和之前的工作一样,他们也只是在少数不同数据集和少数几类不同网络上对比评估了他们的新发现和(整流)基准激活函数——这些数据集通常取自 CIFAR(Krizhevsky, 2009)和 ImageNet(Russakovsky et al., 2015)等图像分类社区,使用的网络也通常是充斥着图像分类社区的深度卷积网络(Szegedy et al., 2016)。
就我们所知,人们还没有大规模地通过实验比较过不同激活函数在不同任务和网络架构上的表现,更别说在自然语言处理(NLP)领域了。究竟哪个激活函数在不同的 NLP 任务和常用 NLP 模型上表现最好最稳定?在此之前,这个问题一直都未能得到解答。
我们用本研究填补了这一空白。(1)我们比较了 21 种不同的激活函数,包括 Ramachandran et al. (2017) 中通过自动搜索找到的 6 种表现最佳的激活函数;(2)我们采用了 3 种常见的 NLP 任务类型(句子分类、文档分类、序列标注),包含 8 项单个任务;(3)我们使用了 3 种常用的 NLP 架构,即 MLP、CNN 和 RNN。(4)我们在两个不同维度上比较了所有这些函数,即最佳表现和平均表现。
我们发现,在这些不同的任务上,一种很大程度上不为人知的激活函数「penalized tanh」(Xu et al., 2016)表现最稳定。我们还发现它能在 LSTM 单元中成功替代 tanh 和 sigmoid。我们进一步发现 Ramachandran et al. (2017) 中发现的大多数表现优异的函数在我们的任务上表现不佳。但 swish 是一个例外,它在多个任务上都表现不错,但并没有 penalized tanh 与其它函数稳定
2 理论
我们考虑了 21 种激活函数,其中 6 种是 Ramachandran et al. (2017) 中「全新」提出的。表 1 给出了这 6 种函数与 sigmoid 函数的形式。

表 1:上:sigmoid 函数与 Ramachandran et al. (2017) 中表现最好的 6 种激活函数。下:具有不同参数的 LReLU 函数以及 penalized tanh。
另外 14 种激活函数分别是:tanh、sin、relu、lrelu0.01、lrelu-0.30、maxout-2、maxout-3、maxout4、prelu、linear、elu、cube、penalized tanh、selu。我们简单介绍一下:
lrelu-0.01 和 lrelu0.30 是所谓的 leaky relu(LReLU)函数(Maas et al., 2013),它们背后的思想是避免在 relu 的负区域出现零激活/导数。表 1 也给出了它们的函数形式。
prelu(He et al., 2015)是对 LReLU 函数的泛化,是将其负区域中的斜率设置为一个可学习的参数。
maxout 函数(Goodfellow et al., 2013)的不同在于其引入了额外的参数,而且并不在单个标量输入上操作。比如 maxout-2 是取两个输入中的最大值的操作:max{xW+b, xV+c},因此可学习参数的数量多一倍。maxout-3 类似,是取三个输入中的最大值。如 Goodfellow et al. (2013) 所示,maxout 可以近似任意凸函数。
sin 是标准的正弦函数,被提出用于神经网络学习,比如 Parascandolo et al. (2016),其中表明 sin 在特定任务上的学习速度比更有地位的函数快。
penalized tanh(Xu et al., 2016)的定义与 LReLU 函数类似,可被看作是「惩罚」负区域中的恒等函数。penalized tanh 在 CIFAR-100 上报告的优良表现(Krizhevsky, 2009)让作者推测:激活函数在原点附近的斜率可能对学习至关重要。
linear 是恒等函数 f(x) = x。
cube 是立方函数 f(x) = x³,由 Chen and Manning (2014) 为依赖关系分析所用的一个 MLP 提出。
elu(Clevert et al., 2015)是 relu 的又一种变体,其假设了负值,使平均激活更以零为中心。
selu 是 elu 的一种扩展版,Klambauer et al. (2017) 将其用在了所谓的自归一化神经网络背景中。
激活函数的属性
人们推测激活函数的很多属性都对学习成功至关重要。表 2 列出了其中一些,另外还给出了一些简要的说明和解释。

表 2:常被提及的激活函数属性
3 实验
我们使用三种神经网络类型和三种 NLP 任务类型进行了实验。

表 3:我们实验中使用的评估任务,按任务类型(句子分类、文档分类、序列标注)分组,并给出了统计数据和示例。C 是指所要预测的类别的数量。

表 4:每种网络类型的超参数范围。超参数取自指定范围中的离散或连续均匀分布。重复的值表示多个集合。N (µ, s) 是均值为 μ 且标准差为 s 的正态分布;µ = m 是 Keras 的特定优化器的默认值(如果选取的学习率小于 0,则我们选择它为 m)。
3.1 MLP & 句子分类
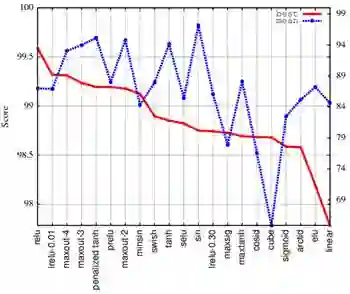
图 1:句子分类。左侧 Y 轴:最佳结果;右侧 Y 轴:平均结果。在 Y 轴上的分数是在所有 mini 实验上的平均。
3.2 CNN & 文档分类

图 2:文档分类
3.3 RNN & 序列标注
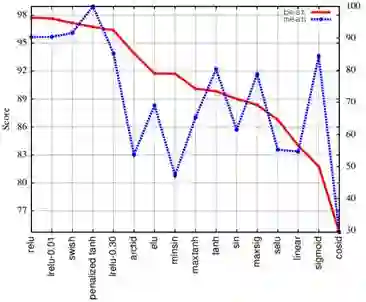
图 3:序列标注
4 分析与讨论
获胜者统计情况
在最佳表现上,句子分类、文档分类和序列标注这三个元任务平均而言都是 rectifier(整流)家族的一个成员获胜,即 relu(获胜 2 次)和 elu。另外,在每种情况中,cube 和 cosid 都位列表现最差的激活函数。Ramachandran et al. (2017) 中新提出的函数大都位居中间位置,但 swish 和 minsin 在「表现最佳」类别中表现最佳。对于「表现平均」类别,maxout 函数尤其突出,另外 penalized tanh 和 sin 也常处于领先位置。
为了得到更深入的见解,我们计算了所有 17 个 mini 实验上的获胜统计情况,统计了每种激活函数位居前三的次数。结果见表 5,其中排除了 prelu 和 maxout 函数,因为它们没有在所有 mini 实验中测试。

表 5:获得前三名的次数统计。括号中是进入前三的次数,仅给出了至少 4 次进入前三的激活函数。
可以看到,penalized tanh 和 swish 在「表现最佳」类别中胜出,之后是整流系函数。「表现平均」类别的获胜者无疑是通过使用有限范围来使激活函数饱和而获胜的。如果将比较限制在句子和文档分类(包含 maxout 函数),则 penalized tanh 在「表现平均」类别上优于 maxout。
似乎能够得出结论了:在各种超参数设置上,范围有限的函数表现更稳定,而非饱和函数往往能得到更好的最佳表现。penalized tanh 是值得一提的例外,它在这两个类别上都有很好的表现(成本更高的 maxout 函数是另一个例外)。如果 penalized tanh 在原点附近的斜率是其表现良好的原因,那么这也可以解释 cube 为何表现如此之差,因为它在原点附近非常平坦。
超参数的影响
为了直观地了解超参数影响我们的不同激活函数的方式,我们在测试集上在所有使用的超参数上对激活函数的分数进行了回归操作。比如,我们估计了:
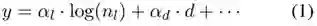
其中 y 是在测试集上的分数,n_l 是网络中层的数量,d 是 dropout 值等等。每个回归量 k 的系数 α_k 是我们想要估计的值(尤其是它们的大小和符号)。我们对规模(比如单元数、过滤器数)显著大于其它变量的特定变量求取了对数。对于优化器等离散回归量,我们使用了二元哑变量(binary dummy variables)。我们为每个激活函数和每个 mini 实验独立地估计了(1)式。
整体而言,结果呈现出非常多样化的模式,这让我们无法得出很确定的结果。尽管如此,我们还是观察到尽管所有模型在隐藏层更少时的表现平均更好,尤其是 swish 能稳健地应对更多隐藏层(较小的负系数 α_l),但 penalized tanh 的程度更小。在句子分类任务中,sin 和 maxout 函数能尤其稳健地应对隐藏层增多的情况。因为 penalized tanh 是一个饱和函数,sin 甚至是一个振荡函数,因此我们得出结论:保持梯度(导数接近 1)并非是成功学习更深度网络的必要前提条件。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


