方法总结:教你处理机器学习中不平衡类问题
【导读】在构建机器学习模型的时候,你是否遇到过类样本不平衡问题?本文就讨论一下如何解决不同程度的类样本不平衡问题。本文整理了数据科学研究者Devin Soni发布的一篇博文的主要内容,分析了不平衡类的情况,并讨论了几种解决方案:度量指标、代价敏感学习、采样方法、异常检测。这些技术中适合不同程度的不平衡问题,例如,简单的采样技术可以让你克服轻微的不平衡,而异常检测方法可能解决极端的不平衡。选择合适的方法能帮助你克服你遇到的不平衡问题。

Dealing with Imbalanced Classes in Machine Learning
▌介绍(Introduction)
大多数分类问题样本都会有一定程度的类失衡,即每个类在数据集中的份额不等。妥善调整评价指标和方法以适应目标是非常重要的,如果没有这样做,最终可能会因为所用的不平衡样本而得到一个无意义的指标。
例如,假设有两个类A和B. 类A占数据集的90%,而类B占另外的10%,但你最感兴趣的是识别类B的样本。如果只是简单地预测类A,你可以达到90%的准确度,但是这对你来说意义不大。相反,合适的校准的方法可能会只有较低的准确性,但会有一个true positive rate(或召回率),实际上这才是你应该优化的标准。这些情况经常发生在检测中,例如在线不良内容检测或医学数据中的疾病标记检测。
现在我将讨论几种可以用来缓解不平衡的技术。其中一些技术适用于大多数分类问题,而另一些技术可能更适合特定的不平衡问题。这篇文章中,我将从二元分类的角度来讨论这些问题,但是大多数情况下,同样适用于多元分类。我也假定目标是识别少数的类,否则,不能证明这些技巧是有必要的。
▌度量指标(Metrics)
一般来说,这个问题处理的是召回率(true positive实例被划分为positive的百分率)与精确度(被划分为positive 的实例中确实是positive的比例)之间的平衡。在我们想要检测少数类的情况下,我们通常更关心的是召回率而不是精确度,就像在检测的场景下,错过一个positive的实例的成本通常高于错误地标记一个negative的实例。例如,如果我们试图检测不良内容(辱骂、欺骗内容等),手动审核人员发现实际上非不良内容是极少的,但要识别不良内容则更加困难。因此,比较不平衡分类问题的方法时,请考虑使用比准确性更合适的指标,如召回率,precision和AUC/ROC。在参数选择或模型选择时,换一种度量方法可能就能提高少数类检测的性能。
▌代价敏感学习
在常规学习中,我们平等对待所有错误类别,因为没有针对少数类的奖励机制,所以这会导致不平衡的分类问题。成本敏感(代价敏感)学习改变了这一点,并且使用函数C(p,t)(通常表示为矩阵)表示将类别t的实例误分类为类别p的成本。这样我们可以对少数类错分给于较多的惩罚,给多数类错分较少的惩罚。我们希望这会增加正确率(true positive rate)。一个公认方案是使成本等于该类所构成的数据集比例的倒数。这样随着类实例数的减少惩罚会增加。

▌采样
解决不平衡数据集的一个简单方法是使数据集平衡,要么增加样本数较少的类的实例,要么减少采样大多数类的实例。理论上讲,我们创造一个平衡的数据集时不会导致偏向某个类。但实际上,这些简单的抽样方法存在缺陷。对少数类进行过度采样可能导致模型过拟合,因为从已经很小的实例集采样会引入重复的实例。同样,对多数类减少采样可能会丢失那些有区分性的重要样本。
还有优于简单采样(过采样或欠采样)的更强大的采样方法。最著名的方法是SMOTE,通过形成相邻实例的凸组合来创建少数类的新实例。如下图所示,它有效地绘制特征空间中少数点之间的线条,并沿着这些线条进行采样。我们创建了新的实例(而不是重复使用),这使我们能够平衡我们的数据集,而不会过度拟合。然而因为这些实例仍然是从现有的数据点创建的,所以这并不完全有效(数据集仍然不平衡)。
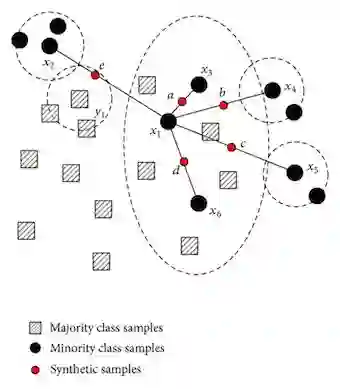
▌异常检测
在更极端的情况下,在异常检测的背景下考虑分类可能会更好。在异常检测中,我们假设存在一个异常的“数据点分布”,且任何偏移的点都是异常的。当我们将分类问题重新归类为一个异常检测问题时,我们把多数类别视为点的“正常”分布,将少数视为异常。有许多异常检测算法,如聚类方法,one-class SVM和隔离森林。
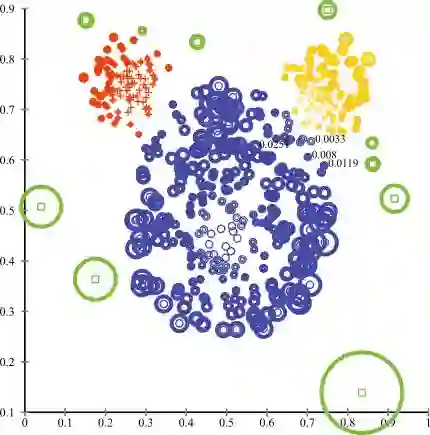
▌结论
希望通过这些方法的组合可以帮你解决平衡问题。 就像我之前说过的,这些技术中适合不同程度的不平衡问题。 例如,简单的采样技术可以让你克服轻微的不平衡,而异常检测方法可能解决极端的不平衡。 最终,对于这个问题,没有一个通用的方法,你需要尝试每种方法,看看它们是否适用于你的特定问题和指标。
参考链接:
https://towardsdatascience.com/dealing-with-imbalanced-classes-in-machine-learning-d43d6fa19d2
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



