打造万物识别之利器——微信扫一扫地标识别篇

导语
回忆一下每逢节假日的“朋友圈摄影大赛”,当我们看到让自己也心动却又未知的风光美景时,除了直接点赞评论“这是哪里呀?”之外,是否还有更“优雅”的方式呢?
微信识图可以让我们当一回朋友圈的“老司机”,只用在图片上长按搜一搜就能轻松获得我们想要的信息了。本文将介绍在这背后,我们在数据和算法上所做的探索和积累。
背景
▍微信地标识别
现在,“万物”皆可识别的微信识图可以轻松满足我们的好奇心,在微信里长按图片,这类地标风景的各类百科、资讯、甚至景点服务都能一触即达。
各地的秀丽风光、人文建筑在我们在朋友圈里等待我们云旅游。微信地标识别,入口已经覆盖到微信中几乎所有会出现图片的位置上,扫一扫、朋友圈、公众号、聊天窗口等等。

图1-1 微信识物部分能力
相比于其他同类产品而言,微信地标识别在操作体验、识别效果和内容展示上,都更具有微信特色。在操作体验上,识别入口遍及微信整个生态,只需在图片上长按搜一搜就能轻松触达;在识别效果上,数据覆盖面广,算法识别结果精准;在内容展示上,能够直达微信生态中的所有信息、咨询和服务。
微信地标识别,从最早的广州首届直播节活动——扫广州塔进入直播间开始,到如今拥有覆盖国内外近10万类目地标、风景的识别能力。本文将介绍在这一过程中,我们在数据和算法上所做的积累与探索。
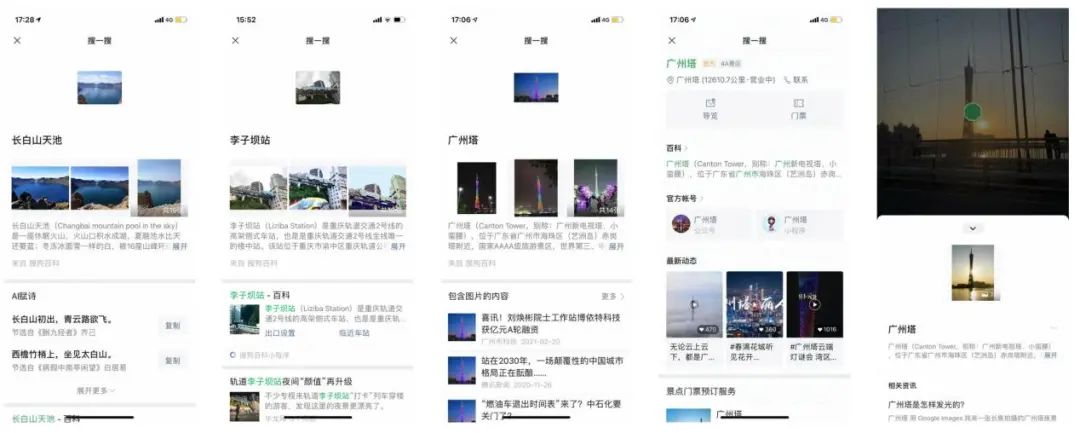
图1-2 微信地标识别结果展示
数据处理
地标识别可以定义为一个对于单独垂类的细粒度图像识别问题,我们沿用在商品识别上的经验,使用基于检索的方案来做地标的细粒度识别任务。对于图像检索任务,我们首先需要对地标数据进行清洗和处理来构建训练和检索库(gallery)。
在构建我们的检索库时,主要的挑战如下:

图2-1 地标图像样例
针对以上挑战,我们整体的数据处理流程如下图所示。我们将其归纳为:检测、聚类、合并、过滤四个主要步骤,下面将对其一一介绍。
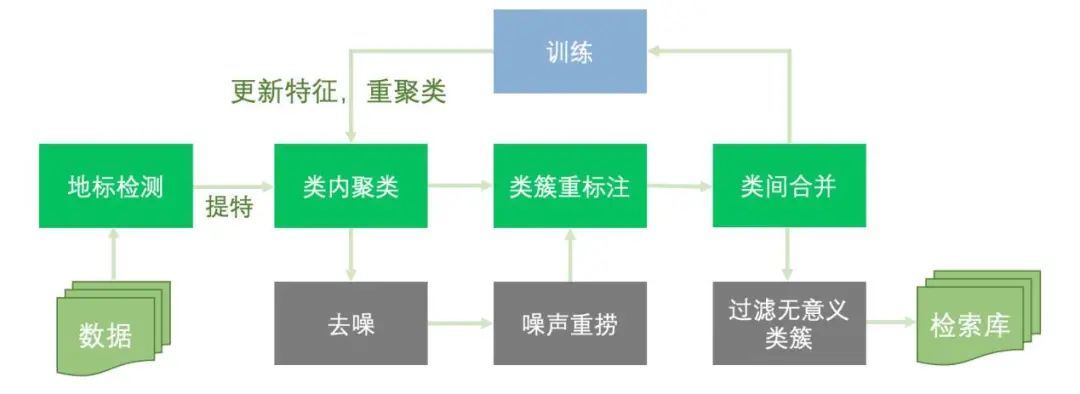
图2-2 地标数据处理流程图
▍检测
检测是我们识图系统的基础能力,通过统一的检测器来对用户query图进行分流,后续进入不同的细分大类的逻辑(如植物/名画/地标)。
有关此检测器的相关内容参考文章《微信识图之面向多源异构数据的检测器设计》的详细介绍,此处,我们仅使用检测器来对离线地标数据进行初步过滤,过滤掉其中的一些明显非地标的噪声,比如一些混在在地标图片中的植物、菜品等其他大类的图片。
▍聚类
使用基于开源数据集训练的分类模型对地标图片进行提特后,我们对同一类目下的所有样本进行DBSCAN聚类,目的是用来去除同类目下的离群(噪声)样本,同时把同类目(A)下图片聚成多个类簇来重标注为多个子类(a1, a2,...),用于后续的模型训练。
通过这种方式,可以轻易地区分同类目下的不同场景,来细化我们的类目标注,例如将上文所说的典型的室内室外两种场景进行分离。此外,我们会对一些样本数目多的类目的噪声样本进行二次聚类,捞回部分有相似特征的噪声样本来作为尾部类目,来丰富我们的训练集。
▍合并
在使用聚类解决类内干扰后,我们会得到大量的来自不同类目的子类簇。这些类簇中必定存在着部分不同类目间的子类簇交叉,而这种在检索库中的“一图多义”的现象是非常不利于我们的后续检索的。
因此,我们进行了类间合并,来消除这种“一图多义”的现象。具体做法是,对2.2中聚类得到的每个类簇提取一个proxy-feature来表征这个类簇的所有样本,随后对各个类簇的proxy-features同样进行聚类,来发现相似类簇,从而对相似类簇进行合并。
▍过滤
最后,在经过以上步骤后,我们已经得到相对干净的地标数据,可用于我们检索模型训练。但是对于需要用于在线检索的检索库而言,我们还需要过滤掉一些不不具有地标属性的入库图片,例如星空、蓝天、海面、雪地等场景,这类场景不具有判别性,没有有效的可区分的特征,我们直接通过一个分类器来自动过滤此类图片。
算法优化
在数据就绪后,本章将重点介绍我们在地标识别的算法上探索。
▍数据增强
对于地标数据而言,检索模型面临的最大挑战可以归结为多遮挡、多尺度、多目标三类。我们在基础的随机翻转、旋转、缩放、剪裁和色彩变换的基础上,加入了更多的drop-based和mix-based增强策略,来应对以上挑战。
drop-based增强策略其核心是对输入图像进行随机的裁剪或者抠图,来人为制造空间上的信息缺失,以这种方式来鼓励模型能够更多地从上下文信息中补全缺失的内容,从而然模型避免过度地聚焦于局部信息,提高模型的全局信息提取能力和泛化性。该类方法典型有Cutout/Random Erase、Gridmask等。
mix-based增强策略本质是混合不同的图像和其对应label,通过对模型引入一个线性的正则来让模型更加鲁棒,增强模型的泛化性能。该类方法比较经典的Mixup。此外这类方法在半监督学习中也有非常不错的应用。
在地标识别中,我们主要采用的是结合drop-based和mix-based的增强。CutMix就是这两类方法的结合,使用图像A的部分区域来覆盖到图像B上进行遮挡,从而生成一个对应的混合图像。
结合地标图像的多遮挡、多尺度、多目标的特点,我们简化了CutMix的操作,简单地把把图像A的原图进行缩放,并遮挡到图像B的任意一个角落上,生成了一个有多目标物的地标图。
通过这种简单的操作,同时增强了模型对于多遮挡、多尺度、多目标的处理能力。能够无代价地提升模型近2个点的精度。

图3-1 地标识别数据增强策略示意图
▍损失函数优化
在地标识别中,我们主要采用augar-based的损失函数如Arcface来训练模型,具体原理在此不再过多介绍,在我们的实验中发现,经过交叉熵预热后的模型再切换到Arcface会有更好的效果。
此外,我着重推荐一些我非常喜欢的一些memory bank相关的工作。memory bank的思想是通过一个特征队列来记忆过去大量的特征,并和当前特征组成海量的特征对来提升模型的表征能力。
这个思想在自监督学习(Self-supervised Learning)和度量学习(Metric Learning)中已经有许多相关工作,例如NPID、MoCo、XBM。这类方法同样在地标识别中有很好的增益。
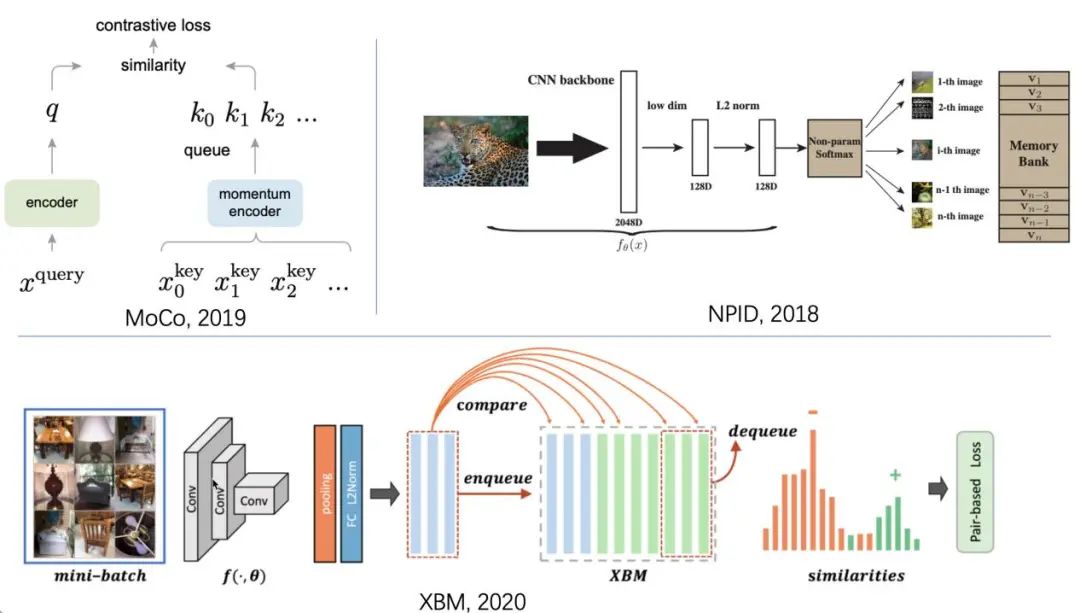
图3-2 memory bank 方法结构示意图
▍后处理策略
我们通常将经过主干网络提取到的图像特征视为global feature,它包含了图像更多的全局和语义信息,有助于我们在整个gallery(检索库)中进行初步检索和排序。
此外,在检索任务上另一个重要的策略是,针对检索结果进行重排序(Re-ranking),即从其他的角度来对query和检索样本进行计算和度量,对检索要的样本来重新排序,从而让检索结果更加精确。在地标识别中,我们主要采用了两种不同的重排序策略:1)k互重排序,2)Superpoint重排序。
k互重排序的经典工作(Re-ranking Person Re-identification with k-reciprocal Encoding),主要是用于行人重识别任务中,同样能够用到地标检索的任务当中。
它的主要贡献是在Re-ranking上,虽然该方法在如今看来并不是非常“优雅”,但在一些实际应用中却有很不错的效果,基于此各种变体的Re-ranking方法也被大家广泛使用。它的核心思路是利用query和各个检索结果之的对偶关系来重新排序检索结果。
具体而言,对于给定的query Q而言,从gallery中检索出一组candidate list。对于candidate list中任意的检索结果A而言,如果将其作为query A,能够在A的检索结果中返回图像Q,那么我们就认为Q和A是互为k-reciprocal neibours,我们认为此时Q和A是同类的概率更高。通过以上描述的k-reciprocal neibours关系,我们可以对candidate list中的图像进行重排序,从而优化检索结果。
但在实际的检索结果中,过度地依赖于global feature,容易让结果一致化,导致一些极端case无法很难被正确检索。实际上,对于一些用户的query而言,在利用global feature的基础上,聚焦于局部特征的local feature能更好地辅助我们进行检索。
这里我们所说的local feature指的是SIFT这类方法提取的特征点和描述子。SIFT是一种基于局部兴趣点的算法,对图片的尺度和旋转鲁棒,这类特征正好契合于地标图像的多尺度、多视角的特点,非常适合作为global feature的补充。在此,我重点介绍两个我们使用过的基于深度模型的local feature方法,一是DELF(Deep Local Features)、二是SuperPoint。
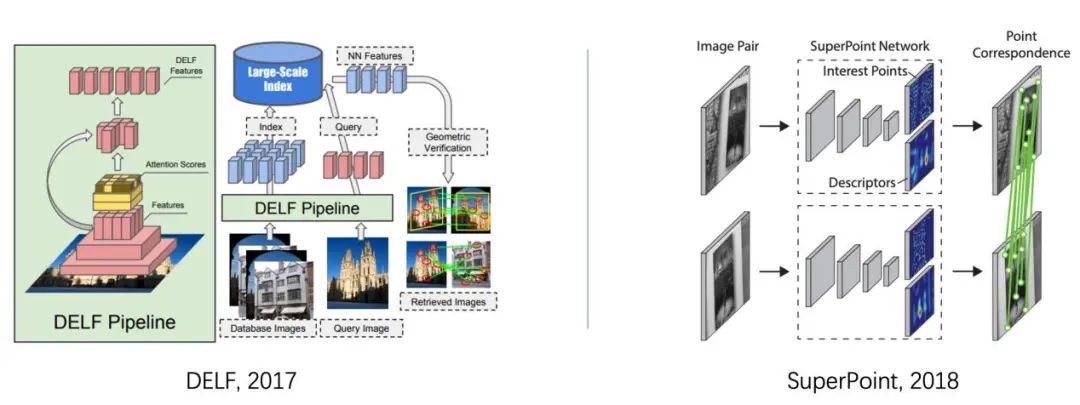
图3-3 Local feature 方法示意图,左:DELF,右:SuperPoint
DELF的核心是提出了一种用于关键点提取的注意力机制,从网络的特征层中提取局部特征。不同于传统方法(SIFT和LIST),DELF是在完成特征提取后再进行关键点挑选。
通过基于CNN的主干网络来对图像进行特征提取,将最后获得的特征图视作局部表达的一种稠密网络。在此之后,使用了基于注意力机制来从这个特征图中选取关键点并计算需要的局部特征,过滤掉其他无用特征。
SuperPoint同样是基于深度模型的Local feature方法。同样的在主干网络进行特征提取后,使用这个特征图来生成关键点和对应的描述子。
不同于DELF的注意力机制,SuperPoint使用了两个head(兴趣点解码器和描述子解码器)来直接输出关键点和对应的描述子,这两者直接进行联合训练。从我们的实验效果上来看,在地标识别的任务上,SuperPoint的效果会略好于DELF。
以上基于深度模型的local feature方法一个显著优势是可以共用主干网络,在一次前向传播过程中完成特征的提取和关键点检测,可以很好的和我们自身的主干网络来进行结合,同时只有极小的额外计算开销。在使用了local feature进行Re-ranking之后,我们的地标检索的效果有约3个点的明显提升。
▍图像质量评估
对于地标、风景的图像而言,在检索任务之外,我们还需要考虑召回的图像的自身的图像质量。我们希望展示给用户和query图相似并且更具美感的相似图。我们使用了NIMA来从直观感受和美学角度上来对图像生成相应的质量分数,来辅助我们对相似图进行排序。
NIMA不是简单地对图像进行质量好坏的分类或者质量分的回归,而是直接预测出图像评级的分布(直方图),来更直接地呈现出人类对图像的偏好。更多细节可以参考其论文。
总结和展望
本文从数据处理到算法优化来介绍了我们在地标识别上的一些实践和探索的经验。通过对原始数据进行检测、聚类、合并和过滤来生成用于入库的gallery和训练集。并且介绍了我们针对地标图像的自身特点的数据增强策略,和在模型上各种行之有效的改进技巧。
在算法上,后续我们将重点探索无监督、半监督算法对于地标识别精度的提升;在数据上,思考引入更多的多模态的数据来辅助识别(例如GPS的位置信息、文本信息);在展示形式上,扩展更丰富多样的内容和信息,通过扫一扫来连接我们的生活。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。



